百度高效研发实战训练营
一、百度高效研发实战训练营Step1
1 设计方法与实践
1.1 软件设计原则
软件设计的目的
软件设计是为了使软件在长期范围内能够容易的进行变化。我们从下面这三个点来理解这句话。
变化:软件不是一成不变的,无论是软件本身的需求、软件依赖的其他软件资源都是一直在发生变化的,唯一不变的就是变化。
容易:任何一个软件的变化都需要成本,要尽可能的降低变化的成本,使得软件可以很容易应对软件的变化。
长期:事实上需要长期进行维护的软件更应该做好软件设计,因为软件长期的变化非常多,难以提前作出预测,需要良好的软件设计来应对。
软件设计原则
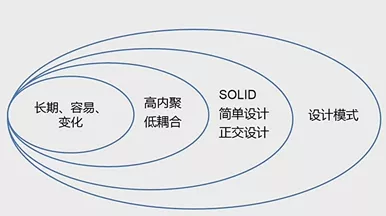
软件设计有着很多的原则,最基本的原则是高内聚低耦合,它也是软件设计追求的最高目标。 内聚 指的是一个软件内部间元素相关联的程度。
高内聚追求的是紧密相关联的元素要放在一起。
低耦合指的是单位之间尽可能少地关联,依赖。
在高内聚低耦合之上有很多其他的原则:如SOLID原则、简单设计、正交设计,在这之上还会有设计模式作为最高层的软件设计原则。
1.2 clean code
clean code的概念
clean code中文解释为整洁代码,是指写的代码能够在尽可能短的时间内被别人读懂,且代码看上去排版整洁、逻辑清晰、扩展性好。
命名规则
代码中命名需要遵循以下的几个规则:
表达它是什么,不要表达怎么做。
代码要做到自注释。
使用有意义的循环迭代变量。
避免缩写,尤其拼音缩写。
不要使用非约定俗成的缩写。
避免使用魔法数。
不要害怕长变量名。
注释
注释对于代码来说是必不可少的。通常情况下,好的注释包含:版权信息,设计意图,警示信息。
不好的注释则具有以下一个或几个特点:同义反复、隐晦关联关系、套用模板、提供历史修改记录以及注释掉的代码。
函数
在写函数时,应当注意,每个函数只做一件事,每个函数应是单一职责。
函数分为骨架函数和步骤函数。
- 骨架函数 是业务逻辑和算法是在高层次上的抽象描述。
- 步骤函数 是业务逻辑和算法的一些实现细节,是被隐藏起来的。
编码细节
在编码细节方面,需要遵循以下几点规则:
- 使用自然的比较顺序。
- 简化逻辑层次,避免多层嵌套。
- 在写三元表达式时不要出现复杂的逻辑和过长的条件。
- 需要控制变量的作用域,也就是缩小变量作用域的范围,越小越好。
1.3 单元测试
为什么进行单元测试
测试是分为不同层次的:最底层是单元测试,中间是基于模块级、组件级的测试,再往上则是系统级别的测试。
越底层的测试,越能够快速地发现问题。底层的测试集成性更好,能够安全的进行代码修改。上层的测试一般情况下获得反馈的速度比较慢,测试过程也比较笨重。
所以单元测试具有更早发现问题,更容易集成,更安全地代码修改的优点。
写好单元测试的重要性
写好单元很费时。

好的单元测试能够降低产品开发的成本。 然而单元测试写得不好的话,不但会增加产品开发的成本,而且还会增加单元测试成本。
单元测试原则与模式
第一个原则:Tests As Documentation
将测试当成一个文档工作,也就是说我们需要把测试写得像文档一样简洁,通过一些描述,可以清晰地知道这个测试的作用。在之后对项目修改时,只需要查看单元测试即可。
第二个原则:Fully Automated and Self-Checking
单元测试都是可以进行自我检查、自我校验的,通过代码的编写,能够知道测试是否成功,不需要人为判定。
第三个原则:Do No Harm,不可破坏性。
部分开发人员在进行测试时,为了完成目的,会基于测试代码创立一些逻辑,这种做法是错误的。在写测试时不能单独为测试创建特别的逻辑,更不能破坏原有代码的逻辑。
第四个原则:Keep tests as simple as possible,简洁性。
单元测试虽然是用来保证代码的正确性,但单元测试也是一份代码,为了避免过多的测试代码相覆盖,要尽可能地把单元测试的代码写得简单,保证其不会出错。
1.4 重构
重构时需要遵循的规则如下:
- 业务导向
重构一定是要解决实际的业务问题的,而不是为了重构去重构。
- 小步快跑
通常重构是需要多人同时参与,重构过程中开发人员要随时对比主干与分支的情况。当某一个开发人员在分支上进行了大量改动并准备将其合并到主干时,有可能主干和分支的代码有很大的差异。所以进行重构时,要将问题拆分成多个小的单元进行修改,并且每修改一个就进行一次分支合并。这种小步快跑的模式可以随时同步主干上的代码,减少出错的可能。
- 演进式设计
在进行代码重构之前,我们不可能知道重构的最终结果是什么。为了保证能够得到一个比较好的结果,我们采用演进式设计方法。在重构过程中遵循包括高内聚低耦合、正交设计原则、SOLID原则等软件设计原则,不断地用小步快跑的方式去重构,只有这样结果才能令人满意。
正交设计原则
分离关注点、消除重复、缩小依赖范围、向着稳定的方向依赖。
在代码中,根据功能的不同,将其分为不同的变化方向。每个变化方向都是一个职责,我们把每一个不同的变化方向称作关注点,根据它的变化方向来进行相应的处理。
1.5 配置化架构
- 配置化架构的定义:
以可配置的方式构建软件的方法。它是在领域建模的基础上,以配置表述业务,以配置组织架构元素,比如服务、组件、数据等,并对配置进行规范化、自动化的管理。
定义的原因:
通常情况下配置指的是对数据的抽象,需要架构上的描述;
架构上描述的配置指的是对架构元素的抽象,描述配置化不完整;
配置化包括对业务的抽象,尤其是逻辑;
配置化还包括对配置的管理以及分支。
- 如何应用配置化架构
应用配置化架构包括三方面:从业务上改造,提高配置本身的开发效率,降低配置的维护成本。
- 业务配置化改造
- 组件配置化
组件配置化表达是业务层面上非常重要的一环,组件是一个独立升级发布的单元,这样的单元关联了很多配置,可将这些配置分为两类。一类是组件内部的配置,另二类是描述组件与组件间关系的配置。只有组件配置化是不够的,往往还需要构建DSL来帮助。
- 构建DSL:
DSL是工程师针对不同的领域创建的语言。具有很强的针对性,在专业领域有时很长的代码只需要将其改为一行配置就足够了。
- 提高配置的开发效率
通过下面的持续发布的系统,能够很好地提高配置的开发效率。它只针对配置,可以独立的发布配置。在系统中:需要配置前端编辑逻辑,后端校验逻辑,当存储发生变更时,触发测试流水线,当测试流水线无异常后,才会借用部署的工具,将配置分发到线上去。
- 降低配置的维护成本
通常来说,代码数量很大的项目,配置也会很多。这样的配置在维护起来需要花费大量的成本。所以在设计配置的时候,要满足以下这些规则:
让配置尽可能地在部署、数据版本、业务属性和架构描述这四个不同维度间参数能够共用。把部署的配置和策略的配置分离开来。
针对配置本身的语法,让配置支持合并.
减少冗余信息。
消除信息重复。
使用配置的默认值。
2. 高效研发流程脚本
2.1 从产品目标到产品路线图
满足用户诉求是产品的基础功能,在此之上还有一个更高的期望,即产品的目标。通常情况下产品目标与产品的收益、市场份额、流水有关。在制定具体产品目标时,需要考虑产品的商业模式以及产品所处的阶段。好的产品目标是具体的、可衡量的、相对稳定的。
在进行产品目标阶段性地拆解时,需要考虑拆解的维度与方法。除了根据阶段性的时间维度进行拆分外,还可以根据产品的里程碑进行拆分。
2.2 从产品路线图到发布计划
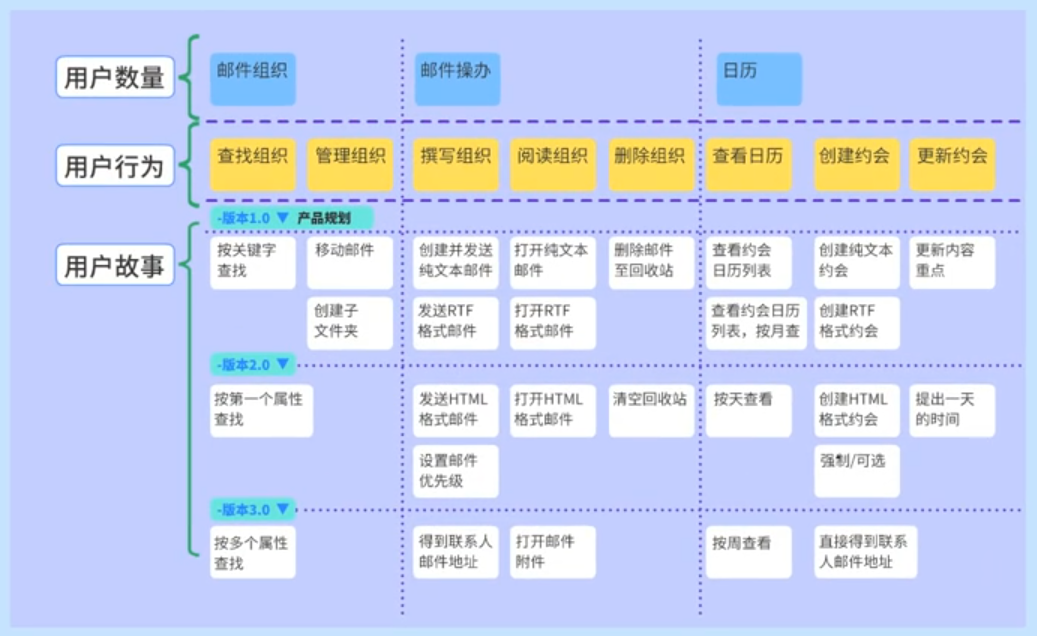
在了解如何制定产品发布计划之前,我们需要先了解一个工具:用户故事地图。用户故事地图实际上是一个完整的用户故事。它可以帮助我们增强团队协作、洞察真实需求、打磨优良产品。
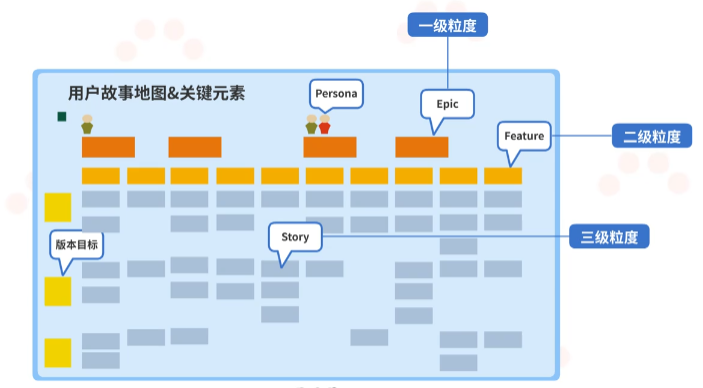
想要创建用户故事地图,首先要有用户故事地图的框架。它的核心是一条从左到右的时间线,然后从上到下按照归纳结构分为三个层级。这一条时间线上方的一级粒度的功能需求,在工作中,我们称之为Epic,也就是橙色卡片。这条时间线下方的第一行为二级粒度的功能需求,在工作中,称之为Feature,是黄色卡片。在二级粒度功能下,蓝色的卡片为三级粒度的需求,工作中,称之为Story,是蓝色卡片。
用户故事地图创建中五个重要的步骤:
一步一步写出你的故事
组织情节
探索替代故事
提取故事地图的主干
切分出能帮你达成特定目标的任务
“训练智能机器人小A从起床到出门”的简单例子
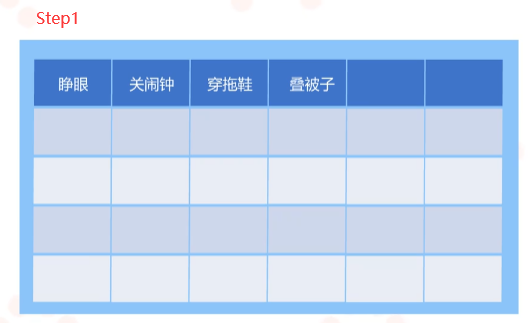

首先我们使用蓝色卡片 按照步骤写出每个任务,每张卡片只写一个任务,任务以动词开头,如“睁眼”、“关闹钟”、“穿拖鞋”、“叠被子”等等。然后按照任务的发生顺序从左到右的组织卡片摆放。
接下来第二步,对所有的任务进行提取,得到概括性的行为,把这些行为放到黄色卡片上,也就是feature。如:“睁眼”、“关闹钟”这些行为可以归为“醒来”后要做的事情;“穿拖鞋”、“叠被子”这两个行为可以归为“起来”后要做的事情。
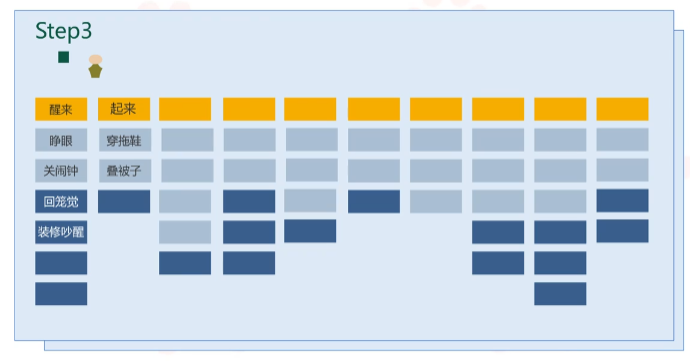
接下来进入第三步:探索替代故事。细节、替代、变化和异常构成故事地图的主题。比如:时间充裕可以睡个回笼觉,楼上装修被提前吵醒等等可能发生的变化和异常。我们需要将这些任务补充进地图。
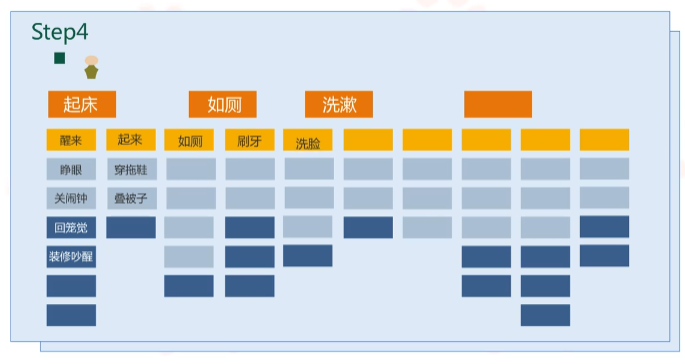
然后进入第四步:将一系列类似的任务提取出来,形成更大的目标。在类似任务的上方,放一张橙色的卡片,也就是之前提到的Epic,卡片贴上一个动词短语,使其足以覆盖其下方所有任务卡片所要表达的意思。例如:“起床”可以概括“醒来”和“起来”;“如厕”可以概括“如厕”和“刷牙”。
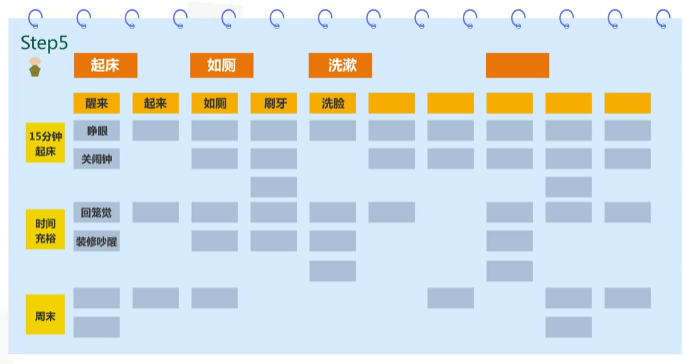
此时已经完成了较为完整的故事地图。然后进入第五步,切分出能达成特定目标的任务。先确定本次迭代需要完成的特性/目标,使用切分来识别和特定相关的所有任务和细节。
在“训练智能机器人小A从起床到出门”这个例子中,分为了三个版本。在第一个版本15分钟起床,回笼觉这张卡片明显是不需要放到其中的。在这些的story中选出满足15分钟起床的事务并将其放入都第一个版本中。至此我们也就完成了一个简单的用户故事地图的创建。

上面这张图片是实际工作中对用户故事地图的应用,可以看到在实际工作中完整的用户故事地图所包含的内容非常庞杂。
完成用户故事地图之后,就需要制订发布计划。在创建用户故事地图的第五步中,我们切分出了达成特定功能的任务目标,每一个发布计划都对应着一个版本。具体的步骤如下:
Big Story进行细化讨论
按照价值和重要程度进行版本规划
确定每个版本的期望达成目标
- 确定每个版本的内容
- 团队达成共识
通过以上步骤,就基本确定了用户故事地图的发布计划。
2.3 从发布计划到迭代计划
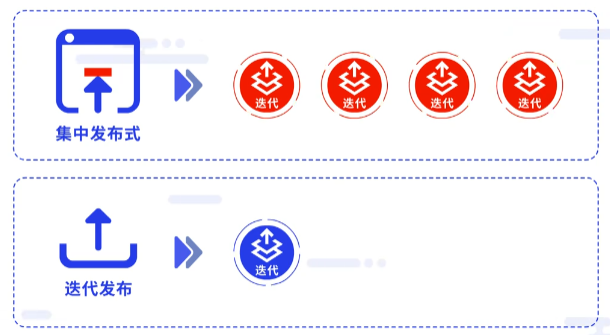
第三部分主要讲解 集中发布式模式 这一常用的模式,在集中发布式模式中,一次发布包含多次迭代;在迭代发布模式中,一次发布等于一次迭代。
很多大型项目都在使用这一模式,通常是每月发布一次,一次发布包含四个迭代,四个迭代之后,发布一次版本。
从发布计划到迭代计划共包括四个内容。
- 用户故事拆分

用户故事的拆分对迭代速率有一定影响。对用户故事的拆分要做到拆分出的故事尽量小,但是要适当,并不是越小越好。避免出现一个迭代内无法完成的故事。
- 用户故事优先级
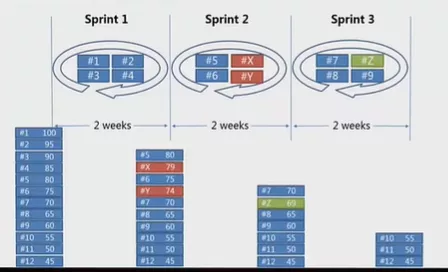
在完成用户故事拆分后,需要对用户故事的优先级进行排序。用户故事的排序其实是对需求的一个排序,优先级排序有许多方法,如高中低、数字排序、衣服尺码L、XL等方式。优先级决定排入迭代的顺序。
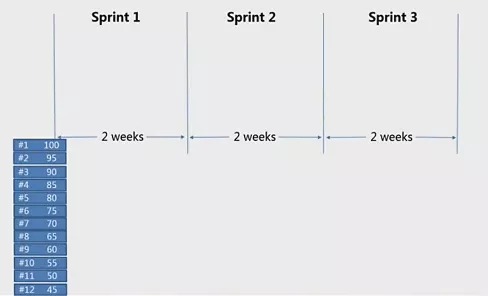
以一个两周的迭代时间为例,假设我们有这样一个需求,前面的数字是需求卡片的序号,后面的数字从100到45,这是项目优先级排序的一个方式。每一次迭代能做4个卡片时,我们就会把优先级最高的卡片放入迭代池。
而当第二次迭代时,需求发生了变化,出现了x和y两个新的需求,x和y有着较高的优先级,那么我们仍然将优先级最高的四个卡片放入迭代池中。
第三次迭代中又插入了新需求z,需求z也有较高的优先级,那么当我们进行迭代的时候,需求z就会顶替另一个需求被放入迭代池中。
通过以上的例子可以看到,在原本的迭代计划中,12张卡片会被按顺序放入迭代池中,而真实情况是插入了更高优先级的需求,替换了低优先级的需求,把低优先级的需求放入了下一次迭代中。这就是优先级排序对迭代计划的影响。
- 用户故事估算
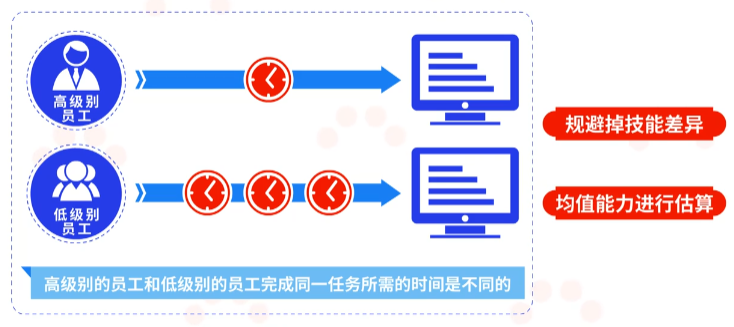
在迭代之前,需要对用户故事进行估算,用户故事估算实际上是对工作量的估算。这个工作量体现的是团队均值能力。
通常在公司内有不同级别的员工,高级别的员工和低级别的员工完成同一任务所需的时间是不同的。所以在进行用户故事估算时就需要规避掉技能的差异,根据团队的均值能力来进行估算。
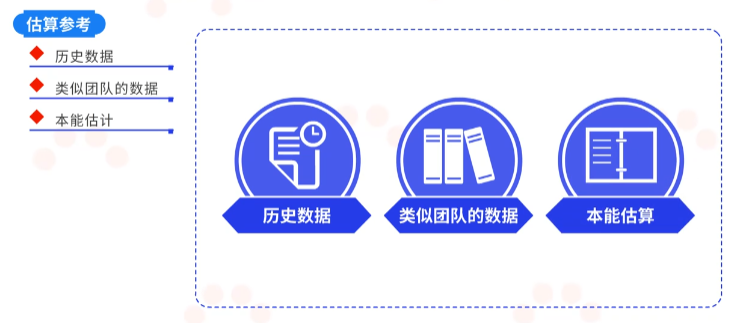
- 迭代计划制定
当前面三步全部完成后,才能开始指定迭代计划。
将已拆分好的用户故事按照优先级依次放入迭代池中,对每个要进行迭代的用户故事进行估算,确定好迭代的时间期限。所以我们就制定出了迭代计划。
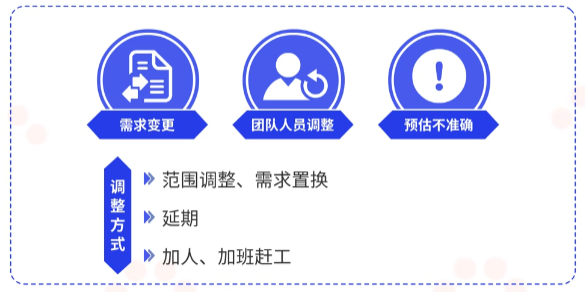
推荐采用范围调整、需求置换方式,即插入高优先级用户故事,顺延低优先级故事到下一次迭代。
2.4 从迭代计划到迭代的落地执行
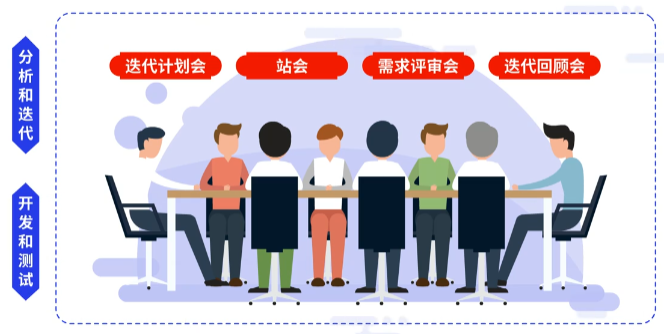
在整个过程中开发和测试以story的力度进行。分析、开发与测试三个步骤并行。
团队可以使用卡片墙标注完成的任务和未完成的任务以及遇到的bug等。通过这种方式,能够对执行情况有清晰的认知,对执行过程产生积极的影响。
3 研发工具链介绍
3.1 项目管理工具: iCafe
3.1.1 需求管理
需求管理是一个项目的基石。在互联网行业中,因为产品需求迭代快速这一特点,需求管理一直非常令人头疼。所以如何对需求进行更好的管理,更好的做出产品规划对互联网行业的项目来说是一个重要的问题。
传统的需求管理方法有以下几种:
直接将需求写在文档上面,
将需求制作成需求卡片,通过这样的方式让研发人员与需求人员保持信息的一致。
使用Excel进行需求管理和排序。
这三种方法都存在很多的缺点,如撰写文档耗时长、文档编写需求较多人力、文档维护成本高、文档使用过程中沟通不畅等等。文字因为其阅读特性,不方便对任务进行直观的展现。所以在很多项目开发过程中,经常会出现文档交给研发人员后,开发出的产品与文档设计不一致的问题。
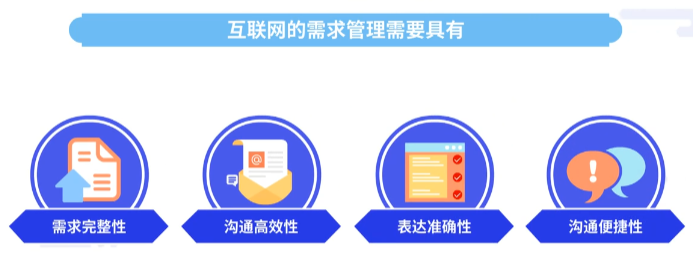
互联网的需求管理需要具有需求完整性、沟通高效性、表达准确性,沟通便捷性等特点。
研究表明,不同的沟通方式产生的沟通效果各有不同。在所有的沟通方式中,文档沟通是最低效的沟通方式,而面对面使用白板沟通是最高效的沟通方式。结合多种高效沟通方式,就产生了用户故事地图这种新颖的需求管理、排序的方式。
用户故事地图是敏捷项目管理中一种重要的管理方式。
首先使用卡片在白板上将所有的需求列出来,这样有助于展现产品全貌,而且将需求转化为可视的卡片能更好的根据用户反馈对任务需求进行排序;
然后使用不同的颜色对卡片进行分层。蓝色卡片是第一层,黄色卡片是第二层,白色卡片是第三层。将颗粒度最小的需求放在白色卡片这一层,低颗粒度的需求更容易被研发人员接受。
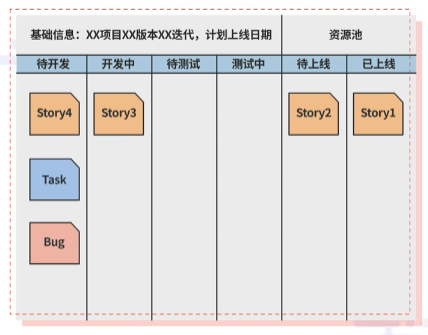
最后通过横向的分组,把迭代计划每一期的每一版本的需求进行归类分组。这样有利于打通产品视图和研发计划视图。
通过以上步骤可以得到一个较为完整的用户故事地图。
3.1.2 迭代计划
在完成产品的版本规划后,研发团队需要制定相应的迭代计划。敏捷、快速、合理地迭代计划能够更高效地促进项目的迭代。
基于用户故事地图,可以在制定迭代计划的过程中中直接对需求进行上下拖拽修改优先级,左右拖拽更改计划。这样可以更清晰的展现迭代计划,使开发团队更好定位到的里程碑,完善整个迭代计划。
3.1.3 进度追踪

进度跟踪的三大法宝:站会、卡片墙、燃尽图。
站会同卡片墙相结合,在站会过程中可以直接通过电子看板共享项目进度和项目问题,提升站会沟通效率。

用户故事地图是一种非常高效需求管理方式,目前所有的研发团队都可以在效率云上不受物理条件限制的直接使用它进行需求管理和追踪。
3.1.4 持续改进
针对持续改进,有卡片状态时长散点图和卡片状态累积流图这两种工具。

卡片状态时长散点图能够精确展示团队工作速率,从需求提出到需求上线的单个周期时长和平均周期时长,精确的展示团队在每一个状态的工作速率及工作速率的变化。
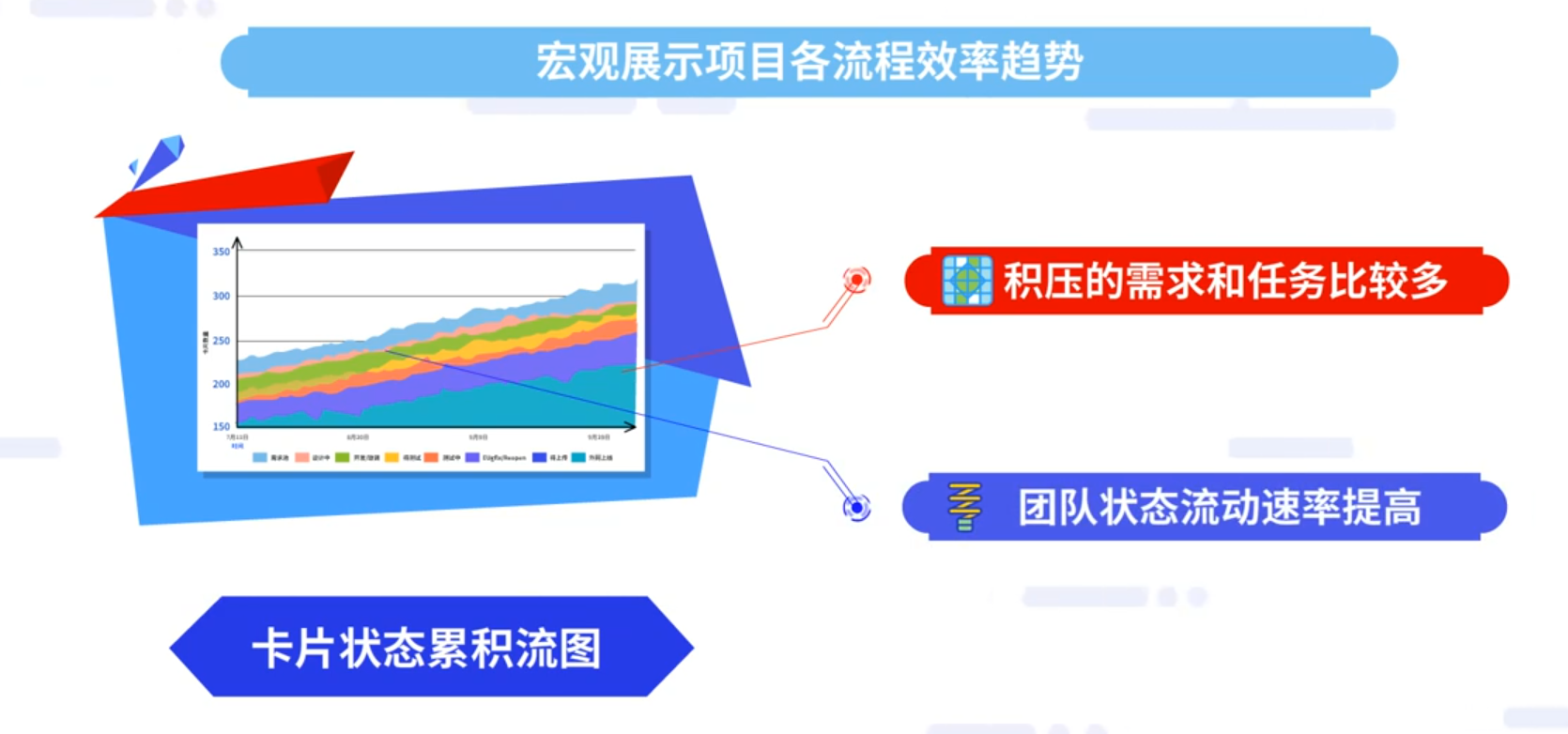
卡片状态累积流图能够宏观展示项目各流程效率趋势,颜色的色块宽表示该流程积压的需求和任务比较多,色条变窄表明团队状态流动速率提高。
基于这两幅图工具,研发团队可以周期性地进行自检,对过去一段时间的工作进行自我审视,然后持续改进。
3.2 代码管理工具:iCode
3.2.1 工作流
运转无序,开发混乱是困扰很多团队的一个问题,严重影响产品的交付。
典型的问题有:代码处理随意、bug重复发生、测试不完善、发布版本混乱等。
支持以下两种标准的工作流,用来保障团队有序协作。
1. 基于主干的工作流
在基于主干的工作流中,整个团队维护一条主干分支。为了保证主干分支的质量,需要配套严 格的准入机制,变更点在合入前需要经过机器、人工的双重评审,通过后才能合入主干。
需要发布的时候,会基于主干拉取发布分支,这个分支其实是主干特定点的快照,单纯用于发 布,如果发布问题过程中发现问题,回到主干修复Bug或进行功能增强,必要时再将主干提交拣 选到相应的发布分支上。
分支发布和主干并行不悖,不用担心开发中的功能被带到线上,发布完成后恢复到一条主干的 简明模式。
基于主干的工作流优点有:
- 主干质量高,随时可以发布。
- 模型简单,只有一条主干,节省分支合并的成本。
缺点: 在开发高质量的工程项目时,团队需要建设完备的测试用例,在提交环节要求提交人保持原子提交,即功能和提交一一对应。
2. 基于分支的工作流
在基于分支的工作流中,主干用于存储线上代码,需要变更时,基于主干最新代码开分支完成功能的开发、测试和发布;分支发布前,需要先同步主干的更新;上线之后,需要将分支合并回主干。
基于分支的工作流的优点有:
- 分支并行,独立开发,分支不会相互影响;
- 对团队而言,使用门槛低,分支贯穿一个独立功能开发、测试、发布的整个过程,给予团队充分的时间完善测试用例及完成人工测试;
- 容易上手,系统会引导开发人员完成新建分支、同步主干、合会主干等全部操作。
缺点:需要花费分支合并的成本、需要不断地同步主干,来发现分支的冲突风险点并提前解决。
3.2.2 评审
评审是保证团队工程质量的一个重要的过程。如果不经过评审直接提交代码,可能会污染代码历史,增加后期维护成本,严重时可能还会产生代码质量问题。
在项目开发过程中,可能会出现本地运行正常的代码,在测试环境或者线上环境突然崩溃的情况。针对这样的问题,可以使用质量防护网。质量防护网包括代码扫描、持续集成、人工评审三个层次。
代码扫描能够找出不符合代码规范的地方,在行间距中插入代码评论,同时出具一个风格报告,方便工程师对代码风格问题进行修改。
持续集成会配置一个云端构建,通过云端构建,快速探测出代码初期Bug,帮助开发人员提早修复。
在前两步做好后,团队的资深成员就可以就架构、逻辑、设计等问题进行深入评审。
通过这三步,实现了机器、人工双重评审,层层递进,确保团队的工程质量。
3.3 交付平台:iPipe
3.3.1 固化端到端的交付流程
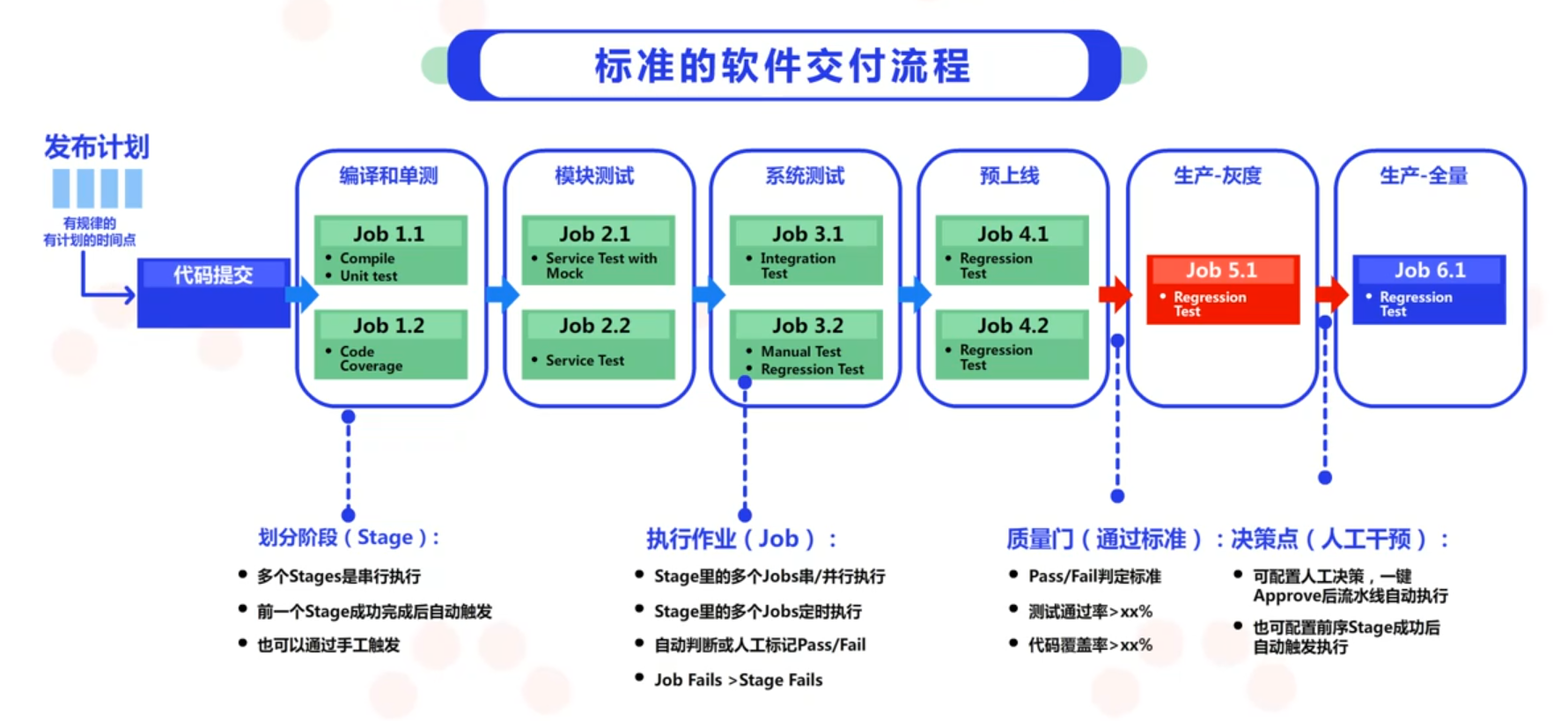
标准的软件交付的过程包括以下几点:
会有一个明确的发布版本的输入,
基于这个发布版本,会进行代码提交。
代码提交之后会进行编译、测试。其中测试环节可能包含模块级的测试和系统级的测试。
进行发布。发布上线的过程可能会分为预上线、生产灰度、生产全量几个环节。
为了使代码变更流程标准化,需要使用交付流水线的方式来落地。通过标准化交付过程从而达到可靠、可重复的作用。交付流水线是串行执行的,上一个阶段成功执行后,就会触发下一个阶段。执行阶段由任务组成,这些任务可以是穿行的也可是并行的。任务的执行状态决定阶段执行状态。
iPipe这一工具目前包含了标准的交付流水线,用户可以在iPipe中看到流水线的构建情况。在使用交付流水线的过程中,如果当前阶段失败,后面的阶段就不会继续进行,这样可以节省资源并且快速的发现问题,及时修复问题。
3.3.2 插件化现有工具和服务

在交付流水线中执行各种任务时需要依赖很多工具和服务,比如maven,docker、jenkins、git等工具和服务。
我们通过一套标准的插件化开发规范将这些工具和服务集成到了流水线中,用户在使用流水线的过程中就可以很方便的使用这些插件和服务。如果流水线中没有想使用的插件、服务或工具,可以根据效率云提供的插件规范,自行扩展以满足项目需求。
3.3.3 数据度量驱动过程改进
通过交付流水线,可以快速获取项目所有的数据和信息,如:一个版本从代码提交到交付上线的周期或者一个项目各个阶段发现的缺陷数量等等。
用户可以通过调用API获取数据来进行数据的度量,从而推动交付过程的改进。在后续的发展中,平台会识别项目中关键的数据指标并且自动化的形成更加鲜明的数据报表。这样就可以持续的进行数据度量,给个人及团队提供一个维度丰富的平台。
4 持续交付方法与实践
4.1 为什么要做持续交付
4.1.1 软件交付流程
传统软件交付流程通常包括四个步骤:
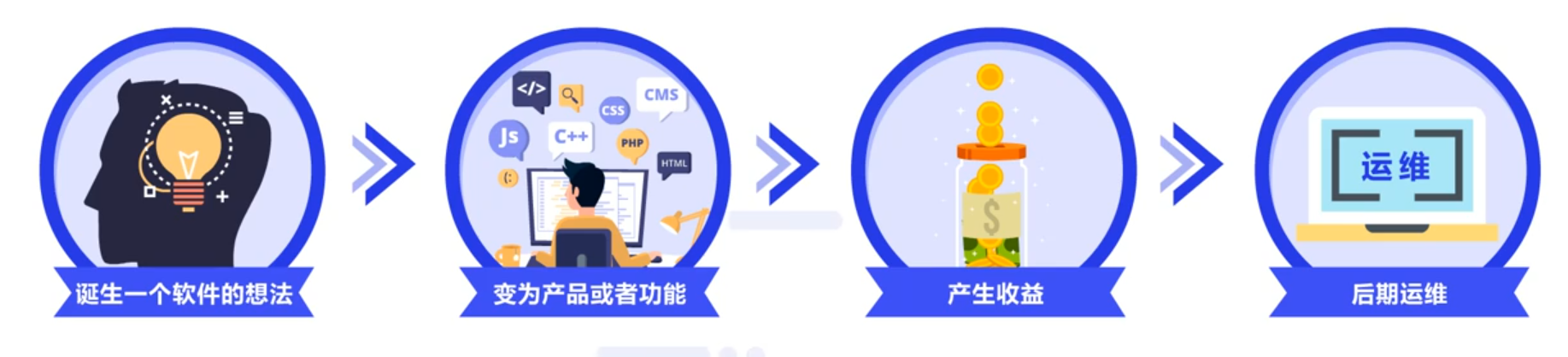
首先业务人员会诞生一个软件的想法;
然后开发人员将这个想法变为一个产品或者功能;
经过测试人员的测试之后提交给用户使用并产生收益;
最后运维人员参与产品或功能的后期运维。
4.1.2 传统软件交付的问题和困境
通过分析以上流程,可以发现一些传统软件交付流程存在的问题。
业务人员产生的需求文档沟通效率较低,有时会产生需求文档描述不明确、需求文档变更频繁等问题。
随着开发进度的推进,测试人员的工作量会逐步增加,测试工作的比重会越来越大。而且由于测试方法和测试工具有限,自动化测试程度低,无法很好地把控软件质量。
真实项目中运维的排期经常会被挤占,又因为手工运维繁琐复杂,时间和技术上的双重压迫会导致运维质量难以保证。
因为存在以上问题,所以传统的软件交付经常会出现开发团队花费大量成本开发出的功能或产品并不能满足客户需求这一双输的局面。由此可以总结出传统的软件交付存在两个层面的困境:
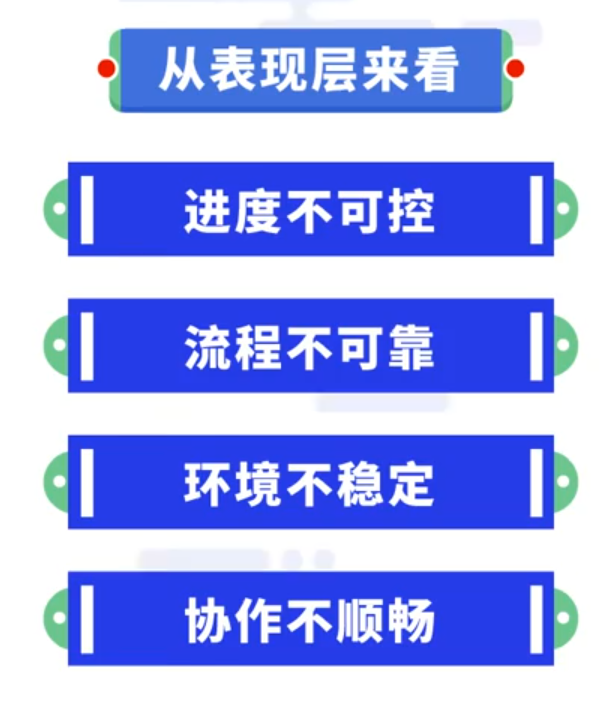
从表现层来看,传统软件交付存在进度不可控;流程不可靠;环境不稳定;协作不顺畅等困境。

表现层的问题其实都是由底层问题引起的,从根源上来说,存在分支冗余导致合并困难;缺陷过多导致阻塞测试;开发环境、测试环境、部署环境不统一导致的未知错误;代码提交版本混乱无法回溯;等待上线周期过长;项目部署操作复杂经常失败;上线之后出现问题需要紧急回滚;架构设计不合理导致发生错误之后无法准确定位等困境。
4.1.3 持续交付的流程与优势

经过对传统软件交付问题的分析和总结,持续交付应运而生,持续交付是一系列开发实践方法,用来确保让代码能够快速、安全的部署到生产环境中。持续交付是一个完全自动化的过程,当业务开发完成的时候,可以做到一键部署。持续交付提供了一套更为完善的解决传统软件开发流程的方案。
在需求阶段,抛弃了传统的需求文档的方式,使用便于开发人员理解的用户故事。
在开发测试阶段,做到持续集成,让测试人员尽早进入项目开始测试。
在运维阶段,打通开发和运维之间的通路,保持开发环境和运维环境的统一。
持续交付具备以下几个优势:
- 持续交付能够有效缩短提交代码到正式部署上线的时间,降低部署风险。
- 持续交付能够自动的、快速的提供反馈,及时发现和修复缺陷。
- 持续交付让软件在整个生命周期内都处于可部署的状态。
- 持续交付能够简化部署步骤,使软件版本更加清晰。
- 持续交付能够让交付过程成为一种可靠的、可预期的、可视化的过程。
4.1.4 敏捷开发与Devops

持续交付依靠敏捷开发(Agile)和Devops两个组件的支撑可以更好地发挥作用。
敏捷开发(Agile)主要作用于需求阶段和研发阶段。
Devops主要作用于开发测试和运维部署阶段。
了解Devops的相关知识。
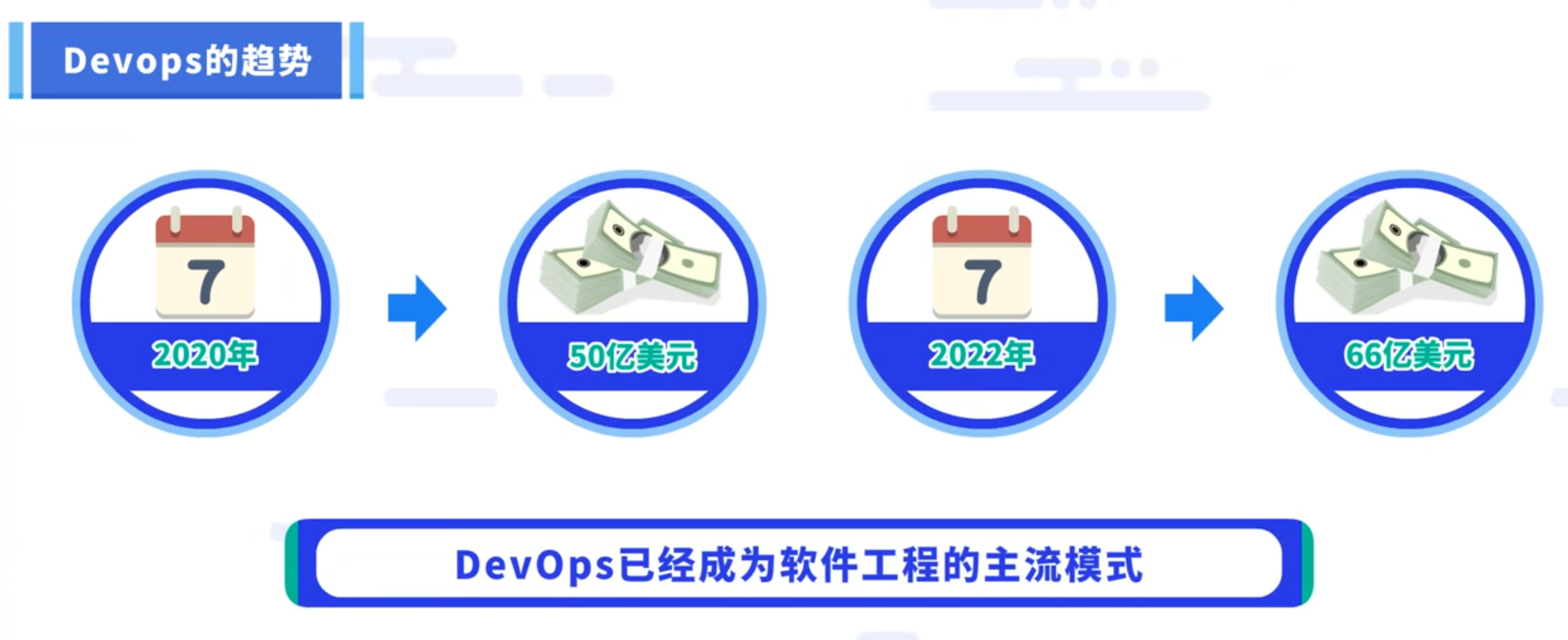
Devops的趋势
根据最近的一项集体研究,DevOps的市场在2020年创造了约50亿美元的产值,预计到2022年,这个数字将达到约66亿美元。随着Devops的影响力不断扩大,目前DevOps已经成为软件工程的主流模式。
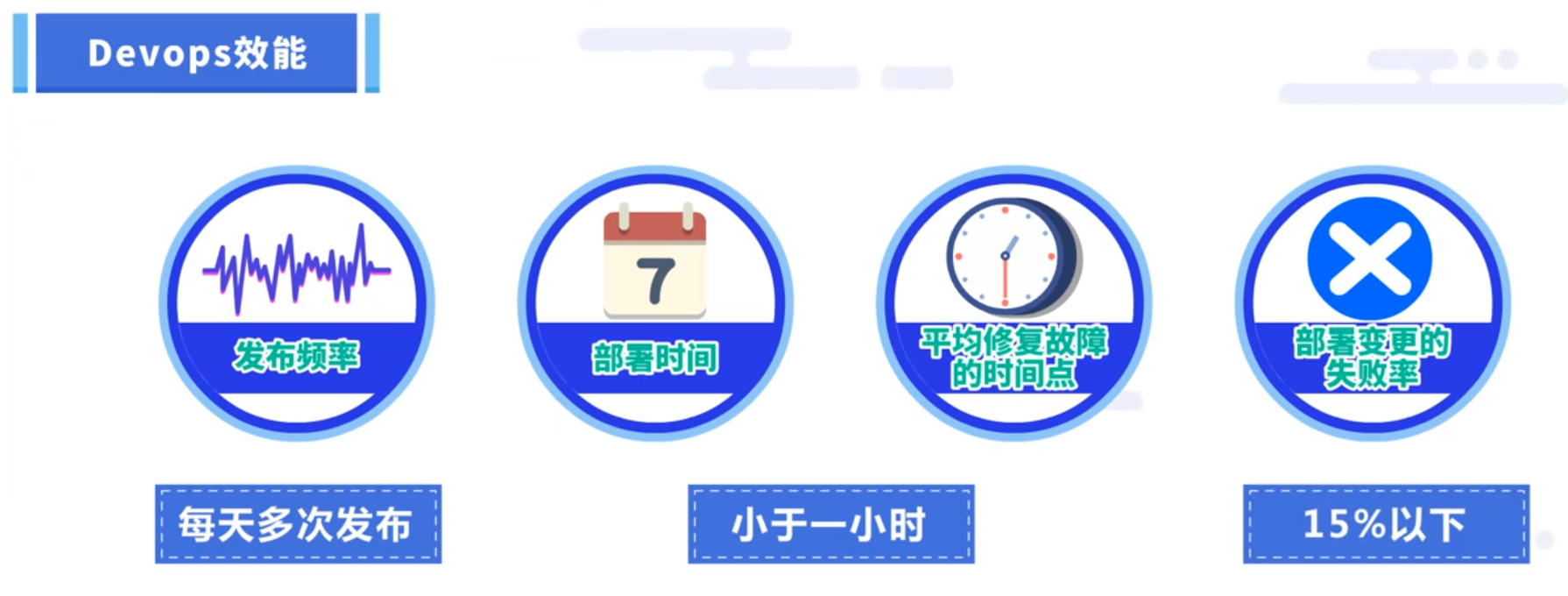
Devops效能
Devops的效能跟发布频率、部署时间、平均修复故障的时间点、部署变更的失败率四个因素紧密相关。通常在高效的团队内,发布频率会达到每天多次发布、部署时间和平均修复故障时间都小于一小时,部署变更的失败率也能维持在15%以下。
4.1.5 软件交付能力指标
在评价互联网公司的软件交付能力的时候,通常会使用两个指标:

仅涉及一行代码的改动需要花费多少时间才能部署上线,这也是核心指标。
开发团队是否在以一种可重复、可靠的方式在执行软件交付。
目前,国外的主流互联网企业部署周期都以分钟为单位, Amazon、Google这些头部互联网企业单日的部署频率都在20000次以上。国内以百度、阿里、腾讯三大互联网巨头的数据来看,单日部署的频率也达到了单日8000次以上。高频率的部署代表着能够更快更好的响应客户的需求。
4.2 如何做到高效的持续交付
4.2.1 持续交付方法
为了能更好的做到高效的持续交付。在此我们提供了一个三层叠加的持续交付方法。
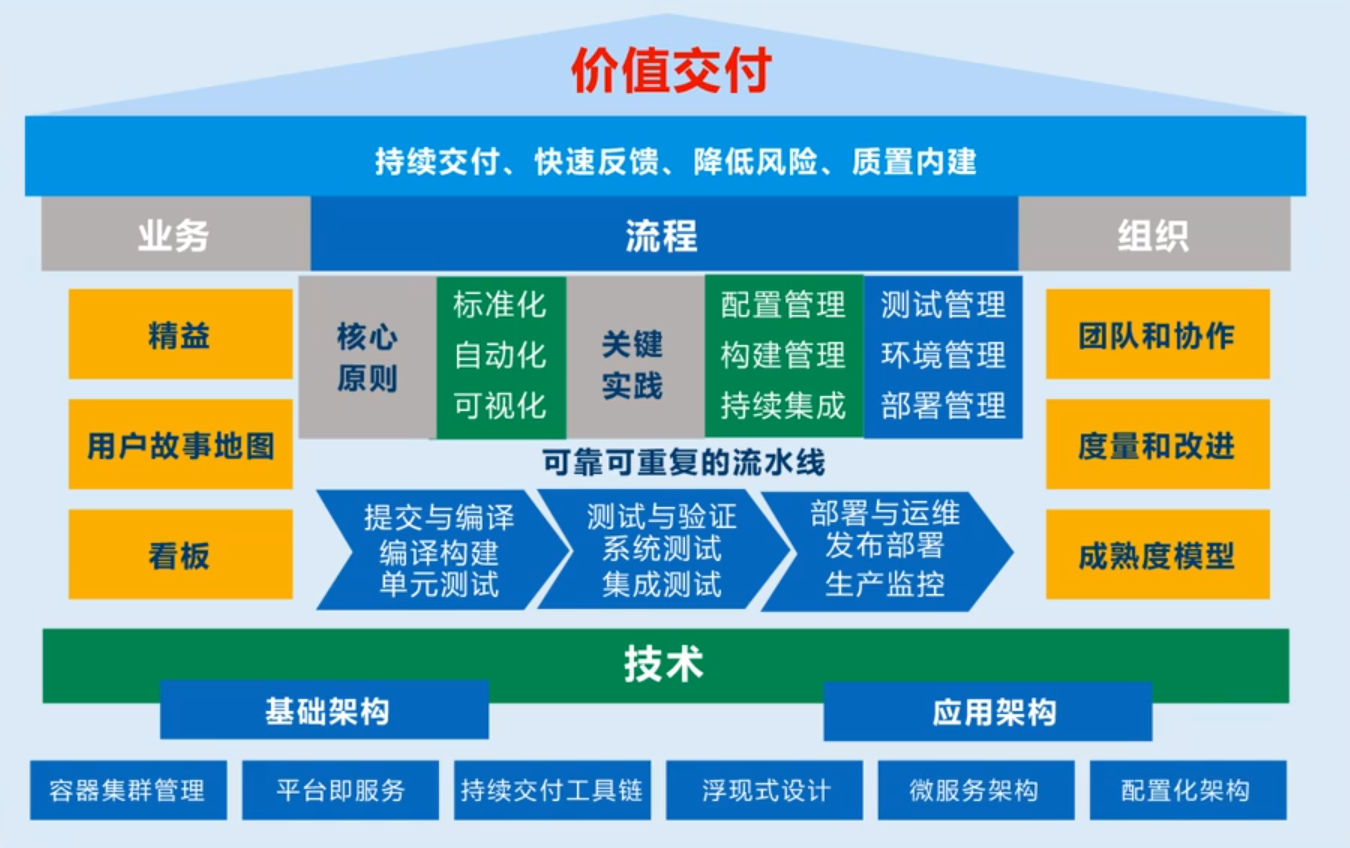
首先最上层,持续交付的总目标是价值交付,要为用户交付有价值的内容。
然后第二层包含了业务、流程、组织三个维度。
在业务这一维度,主要通过精益、用户故事地图、看板三种方式来减少业务部门与开发部门的沟通困难。
在流程这一维度,主要集中于创建一个供开发、测试、运维人员使用的可靠、可重复的流水线,将这种流水线应用于项目的流程中。
在组织这一维度,要求加强团队协作,提高项目质量和项目改进能力,并且引入了成熟度模型用于评估团队的能力层级。
如果没有技术能力的支撑,仅依靠方法和指导思想不足以做到高效持续交付。所以第三层也是最重要的底层是技术层。技术层包括了基础架构和应用架构。基础架构引入了容器集群管理、研发工具平台、持续交付工具链。应用框架引入了浮现式设计、微服务框架还有能够抽离出来的配置化架构。
4.2.2 持续交付、持续集成、持续部署的关系
要进一步构建可靠可重复的流水线,首先就是要理清持续交付、持续集成和持续部署三者之间的关系。

简单来说持续集成和持续部署是持续交付的基础,持续交付包括但不限于持续集成和持续部署。
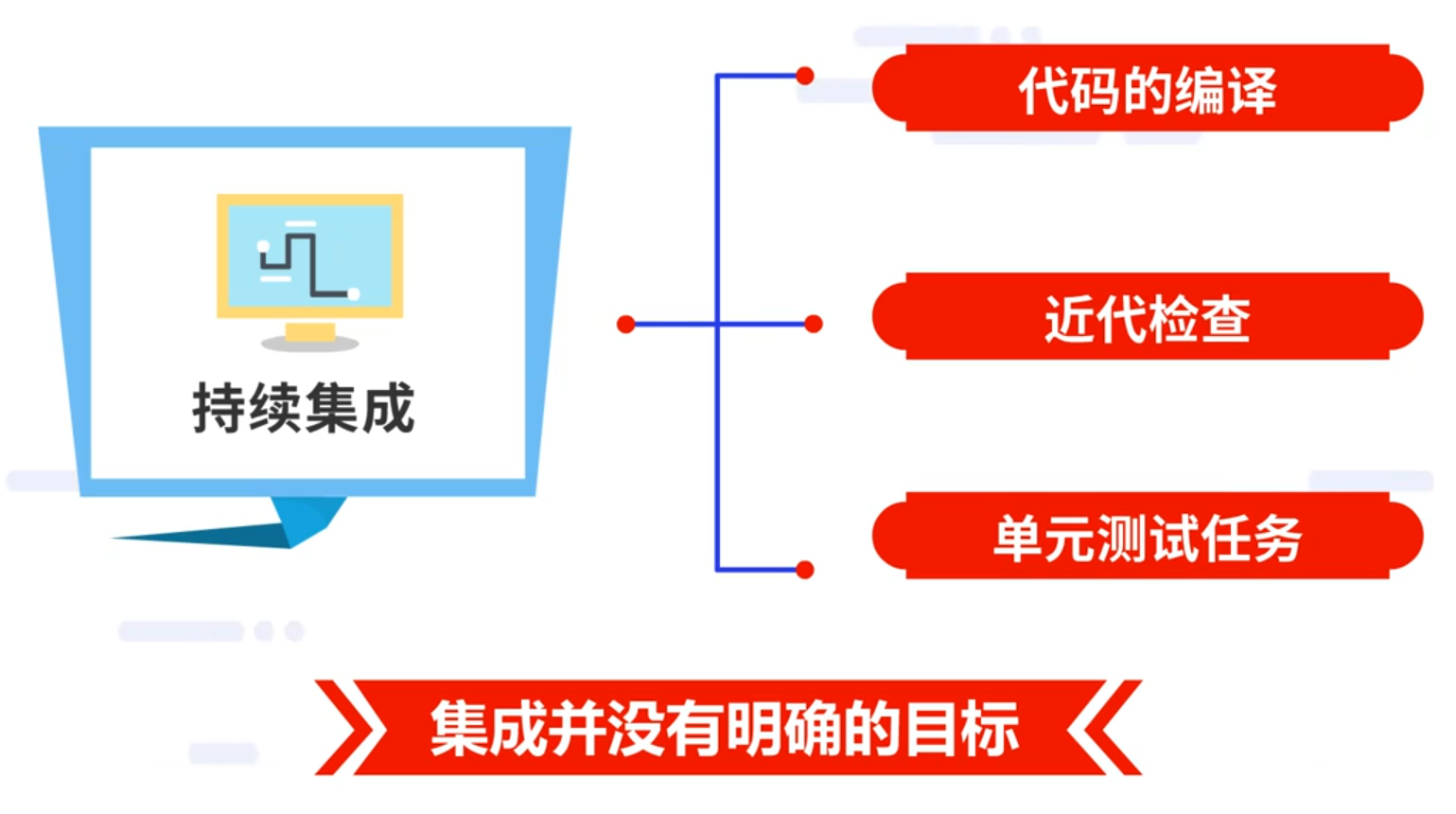
持续集成是包含了代码的编译、近代检查、单元测试任务的集成,虽然持续集成也能构成一条流水线,但是这条流水线并不完整,而且集成并没有明确的目标。
近几年得益于虚拟机技术和容器技术的迅速发展,持续部署也逐渐变得简单高效,能够运用这些工具快速将项目部署到例如准入环境、预生产环境等等各种环境中。
4.2.3 如何构建一个可靠可重复的流水线
在理清持续交付的关系后,需要通过持续交付来构建一条可靠可重复的流水线,构建这条流水线的目的是为了让开发人员、测试人员、运维人员能更好的协作完成整个项目并上线到生产环境。
通过对比传统流水线和持续交付流水线,能更加清晰地展现出持续交付流水线的强大。
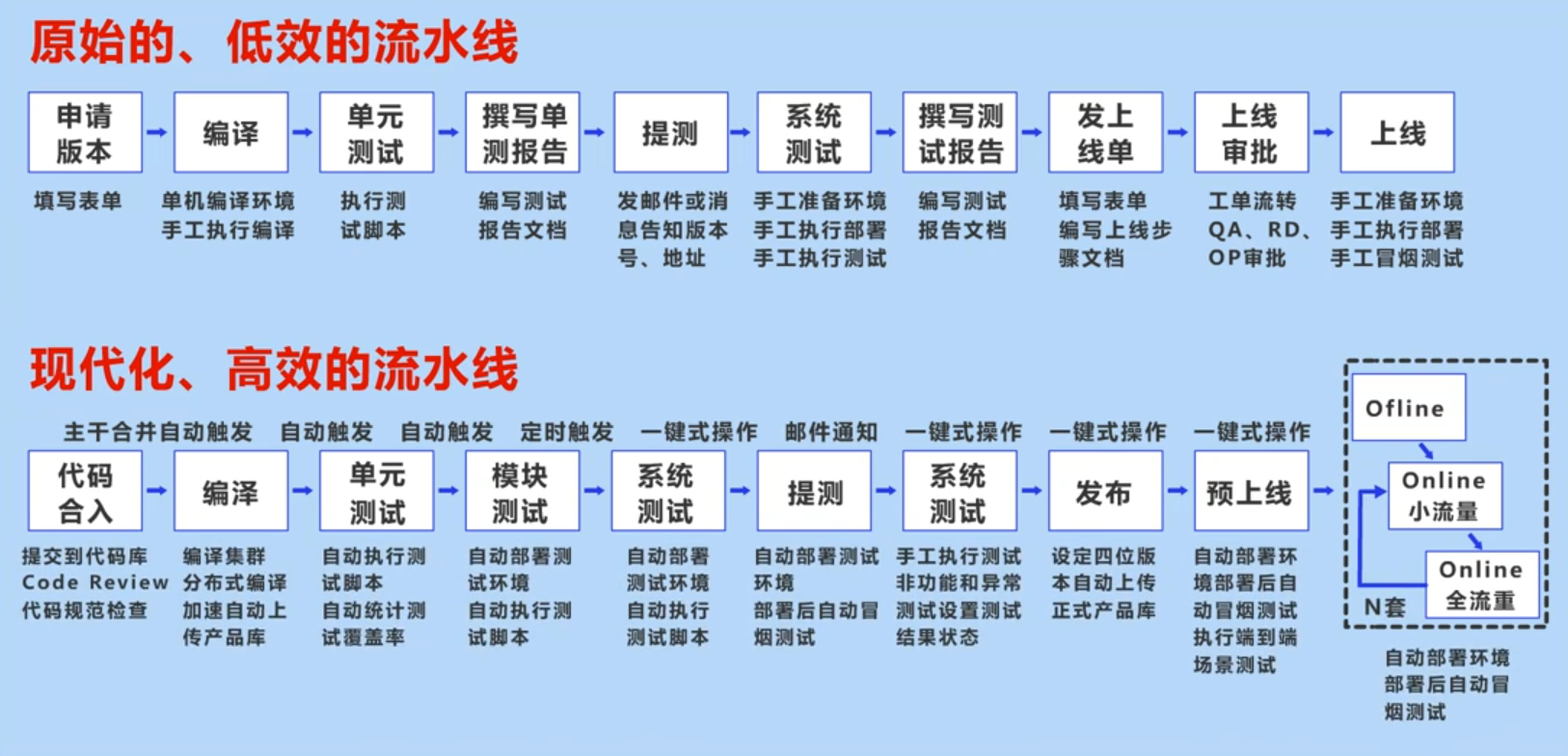
在传统流水线中,首先代码提交要用过填写表单的形式进行版本申请,然后开发人员在离线环境上手工进行代码编译和单元测试,单元测试完成后需要撰写对应的测试报告文档并且向上提测,在系统测试环节需要测试人员手动构建和部署测试环境,完成测试之后再次撰写测试报告,并且申请上线,在通过上线审批之后,在线上生产环境需要再次手动构建环境以及进行生产环境的测试,最终完成整体的开发。
在持续交付流水线中,代码合入到主干之后会直接触发自动编译,自动编译完成之后会进行初步的自动化单元测试、模块测试和系统测试,在测试过程中持续交付可以自动构建和部署环境。完成系统测试之后会将问题抛出来,解决完成后再次提测,会自动化的再次进行系统测试,通过系统测试之后可以一键操作进行项目发布,并进行预上线,在完成预上线后,可以再次进行一键操作完成正式生产环境的上线。
通过两种流水线的对比,可以看出来,持续交付的流水线有显著的优势。
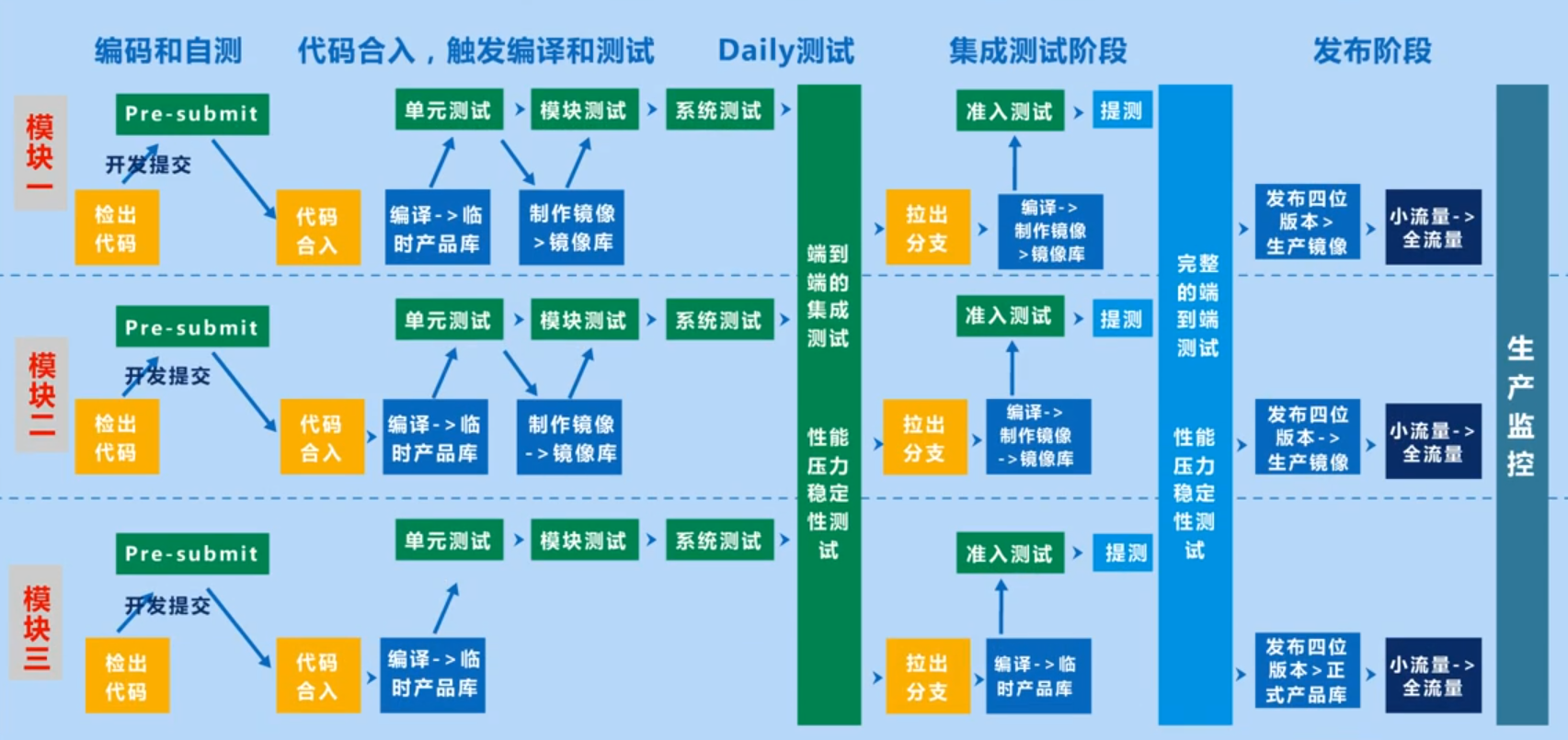
实际生产中的产品级流水线,可以视为多个模块级流水线的组合,多个模块级流水线组合成为复杂的多线并发的产品级流水线,最终可以完成整个项目的持续交付。
4.2.4 交付流水线落地工具
交付流水线的落地需要依靠落地方案和落地工具,目前常用的落地方案有GoCD,这是thoughtworks的一个产品。还有目前广泛应用的Jenkins和Spinnakeer。
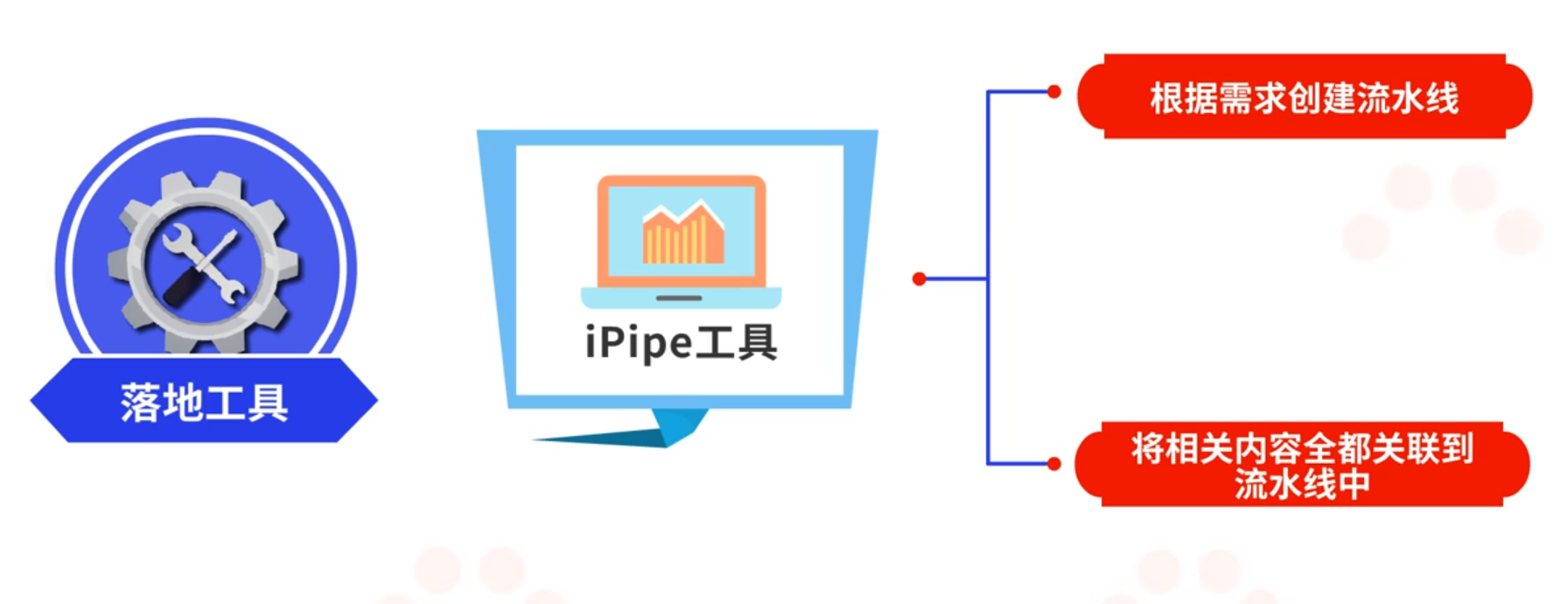
常用的交付流水线落地工具有效率云平台中的iPipe工具,在这个工具中可以根据需求创建流水线,并且将相关内容全都关联到流水线中,这样可以让开发人员、测试人员和运维人员在这个工具中直观的看到产品的状态以及质量情况。
4.3 持续部署
对于持续交付整体来说,持续部署非常重要。
4.3.1 持续部署方案
容器技术目前是部署中最流行的技术,常用的持续部署方案有Kubernetes+Docker和Matrix系统两种。容器技术一经推出就被广泛的接受和应用,主要原因是对比传统的虚拟机技术有以下几个优点:

- 容器技术上手简单,轻量级架构,体积很小。
- 容器技术的集合性更好,能更容易对环境和软件进行打包复制和发布。
容器技术的引入为软件的部署带来了前所未有的改进,不但解决了复制和部署麻烦的问题,还能更精准的将环境中的各种依赖进行完整的打包。
4.3.2 部署原则
在持续部署管理的时候,需要遵循一定的原则,内容包括以下几点:
- 部署包全部来自统一的存储库。
- 所有的环境使用相同的部署方式。
- 所有的环境使用相同的部署脚本。
- 部署流程编排阶梯式晋级,即在部署过程中需要设置多个检查点,一旦发生问题可以有序的进行回滚操作。
- 整体部署由运维人员执行。
- 仅通过流水线改变生产环境,防止配置漂移。
- 不可变服务器。部署方式采用蓝绿部署或金丝雀部署。
4.3.3 部署层次
部署层次的设置对于部署管理来说也是非常重要的。首先要明确部署的目的并不是部署一个可工作的软件,而是部署一套可正常运行的环境。
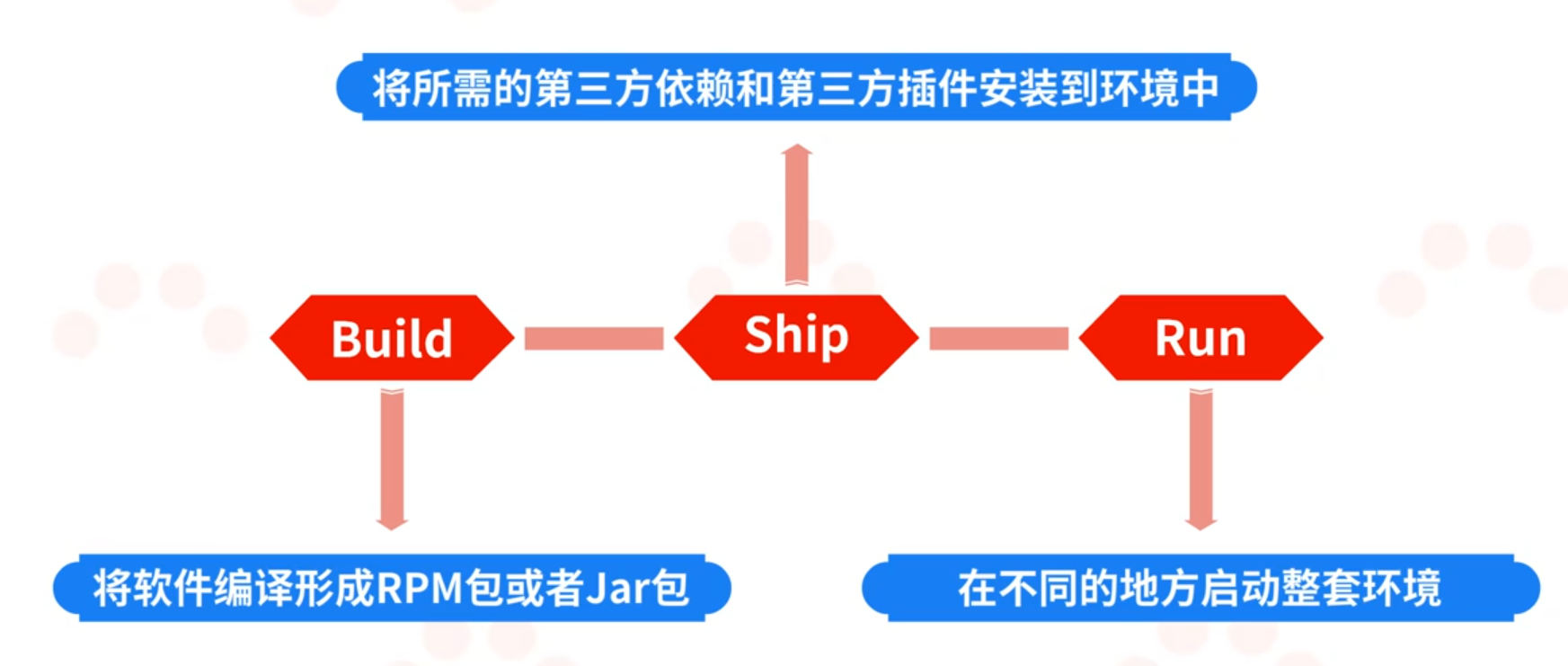
完整的镜像部署包括三个环节:Build – Ship – Run。
Build跟传统的编译类似,将软件编译形成RPM包或者Jar包。
Ship则是将所需的第三方依赖和第三方插件安装到环境中。
Run就是在不同的地方启动整套环境。
制作完成部署包之后,每次需要变更软件或者第三方依赖、插件升级的时候,不需要重新打包,直接更新部署包即可。
4.3.4 不可变服务器
在部署原则中提到的不可变服务器原则对于部署管理来说非常重要。不可变服务器是技术逐步演化的结果。
在早期阶段,软件的部署是在物理机上进行的,每一台服务器的网络、存储、软件环境都是不同的,物理机的不稳定让环境重构变得异常困难。
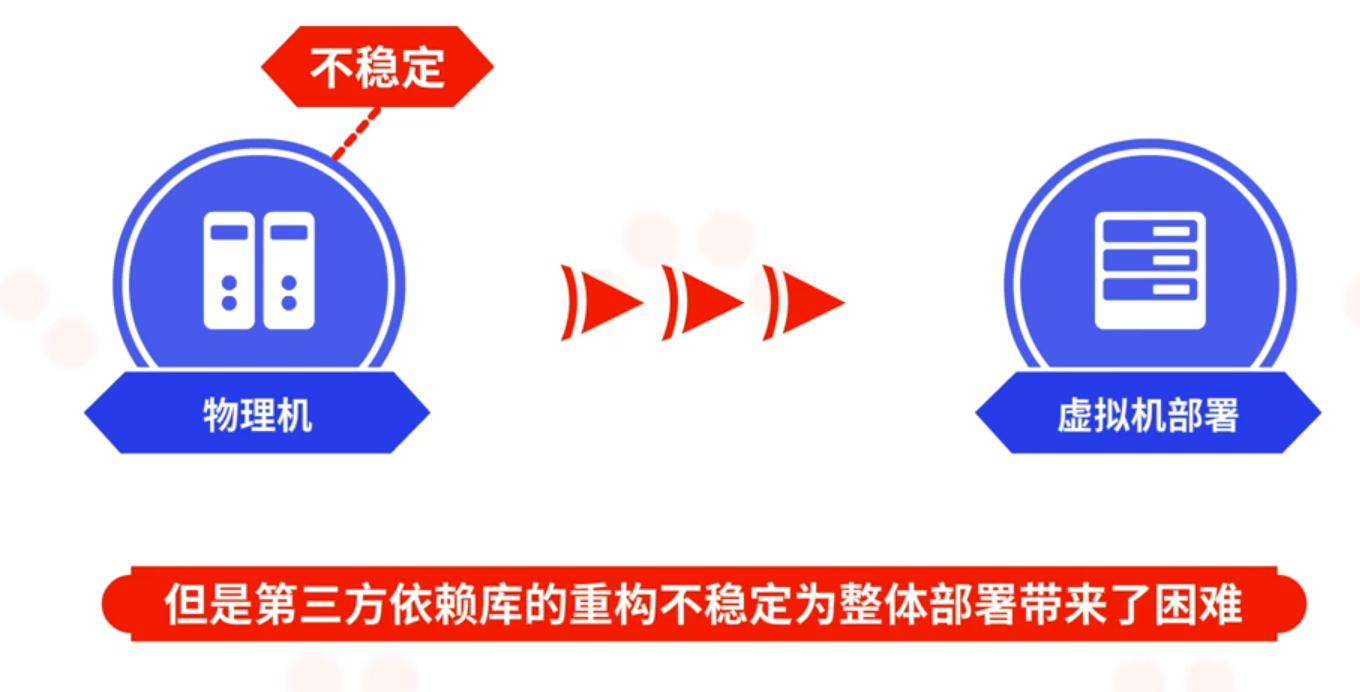
后来逐渐发展为虚拟机部署,在虚拟机上借助流程化的部署能较好的构建软件环境,但是第三方依赖库的重构不稳定为整体部署带来了困难。
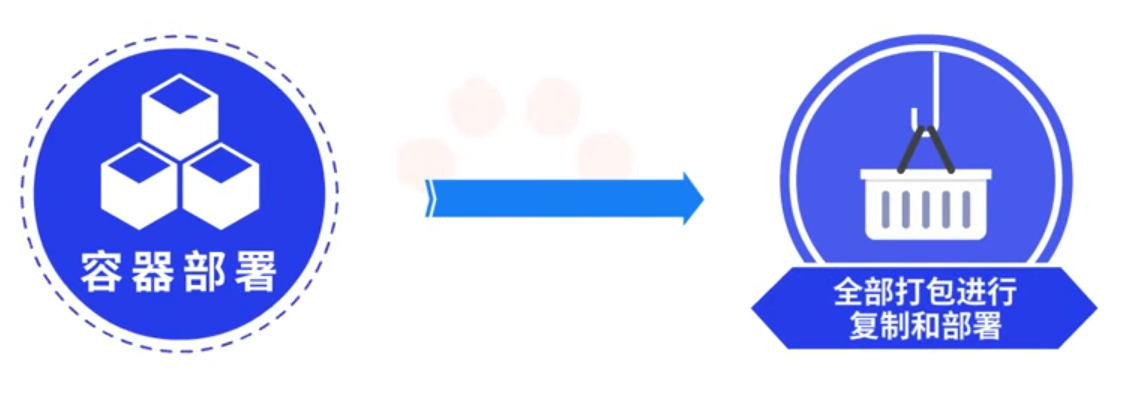
现阶段使用容器部署不但继承和优化了虚拟机部署的优点,而且很好的解决了第三方依赖库的重构问题,容器部署就像一个集装箱,直接把所有需要的内容全部打包进行复制和部署。
4.3.5 蓝绿部署和金丝雀部署
在部署原则中提到两大部署方式分别为蓝绿部署和金丝雀部署。
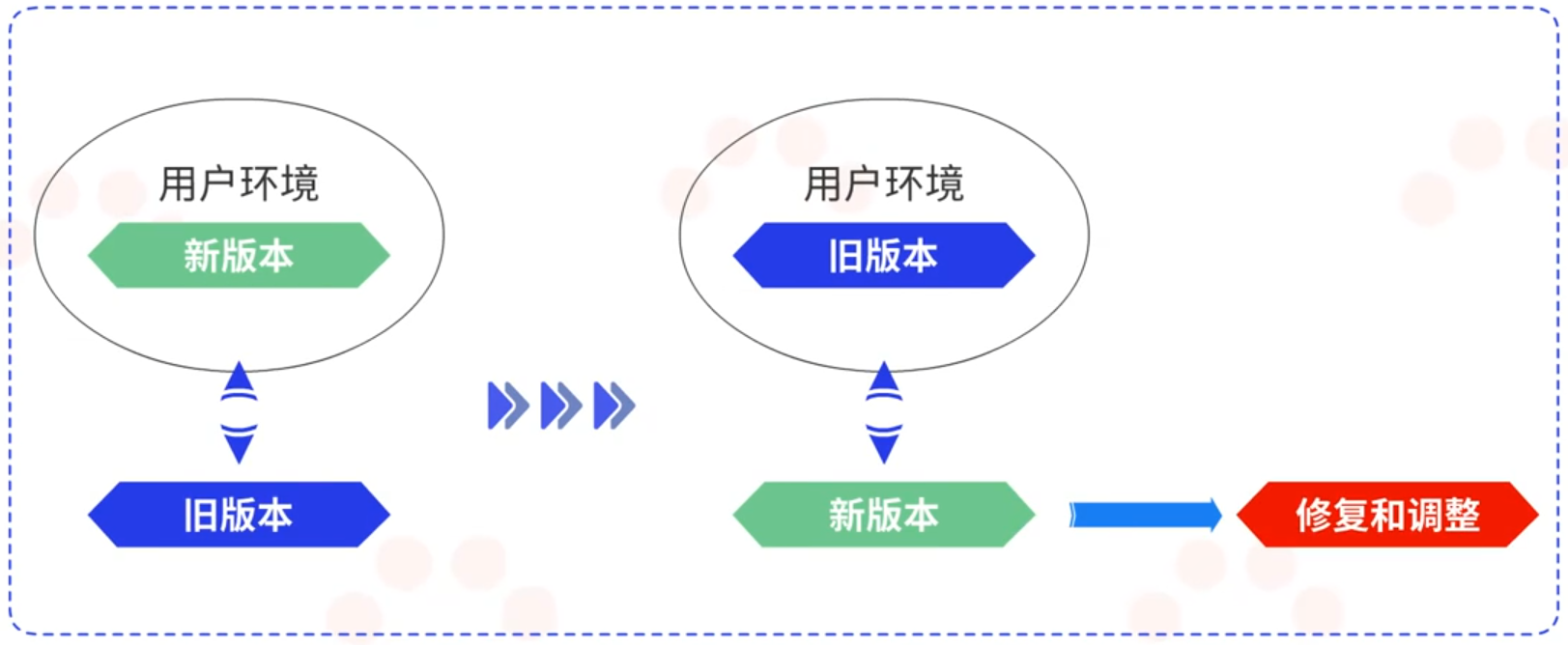
蓝绿部署是指在部署的时候准备新旧两个部署版本,通过域名解析切换的方式将用户使用环境切换到新版本中,当出现问题的时候,可以快速的将用户环境切回旧版本,并对新版本进行修复和调整。
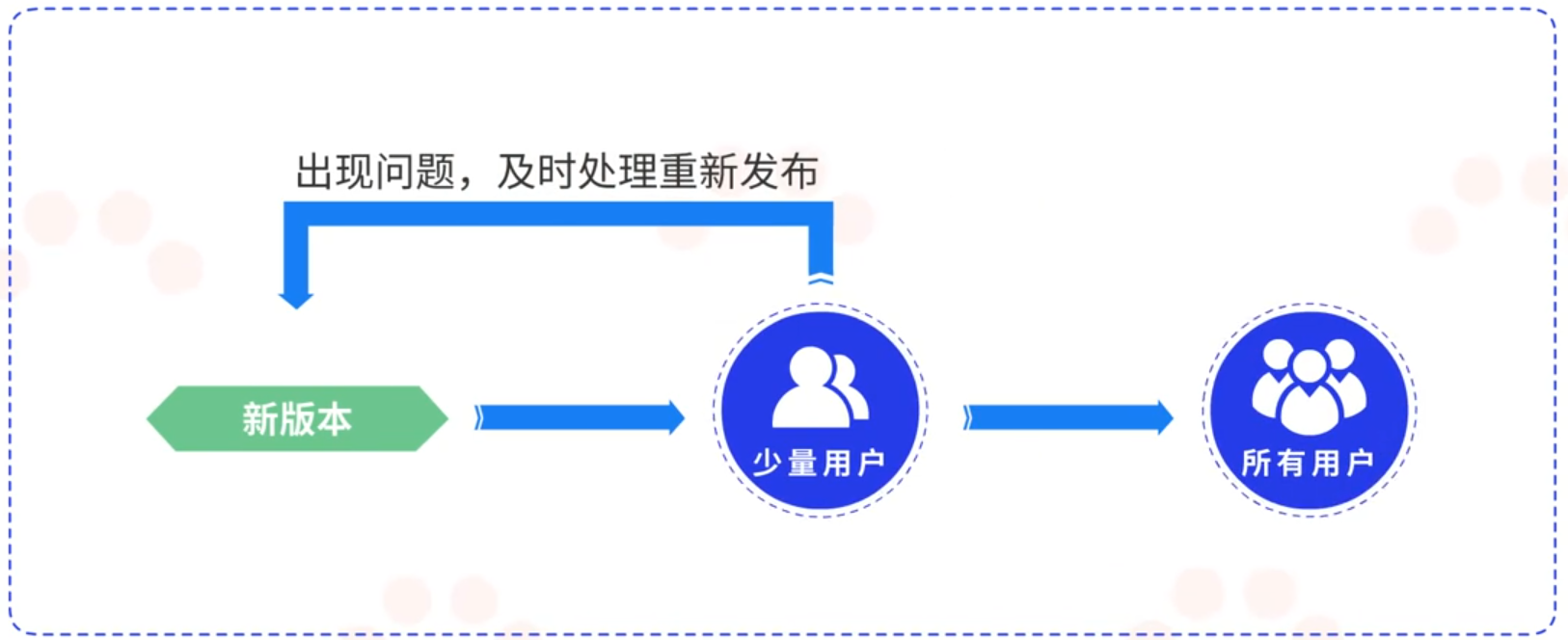
金丝雀部署是指当有新版本发布的时候,先让少量的用户使用新版本并且观察新版本是否存在问题,如果出现问题,就及时处理并重新发布,如果一切正常,就稳步的将新版本适配给所有的用户。
4.3.6 服务描述
服务描述要实现的目标是当软件部署到不同的环境中时,通过服务描述来规避环境配置的差异。

在服务描述中,通常会对不同的环境下所需的配置进行描述,例如所需要的CPU、内存、网络等。当实际部署的时候,如果出现环境差异,调度工具就可以按照服务描述的配置发放资源,使环境能够正常运行。
4.3.7 流程控制
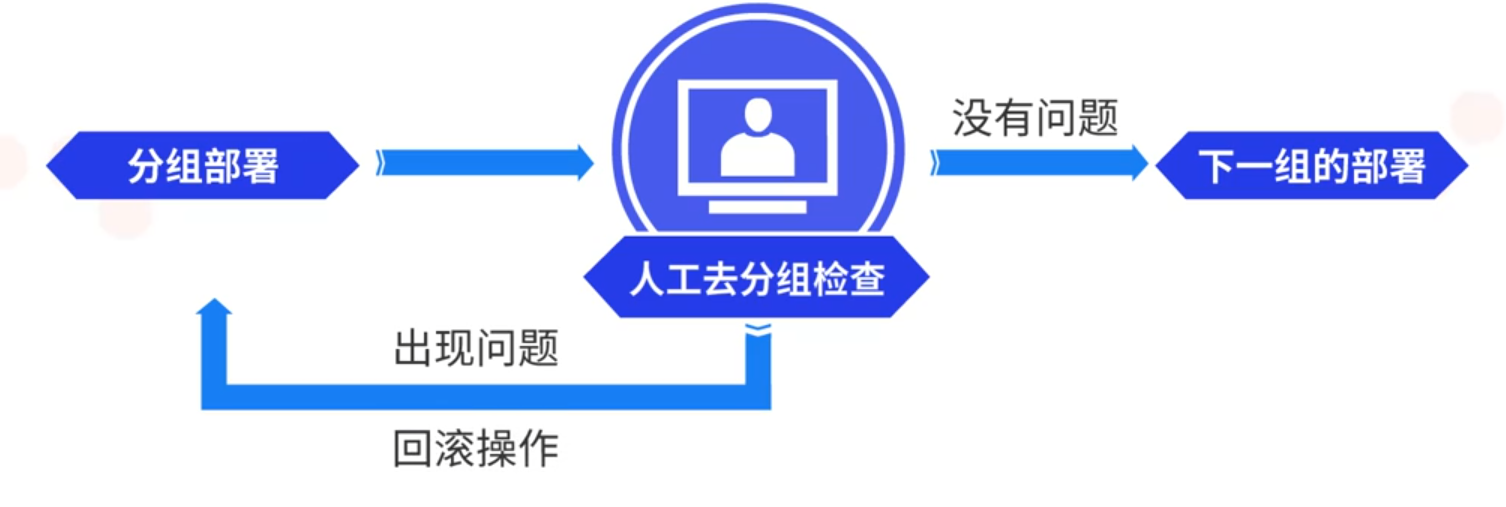
在部署阶段,为了防止意外问题的发生,会在一些环节加入人工审核。例如在灰度发布工具中,就会先对线上机器进行分组部署,然后由人工去分组检查,如果没有问题,就进行下一组的部署,如果出现问题,人工就可以及时的进行回滚操作,避免问题扩大到更多地线上环境中。
4.3.8 数据度量和分析
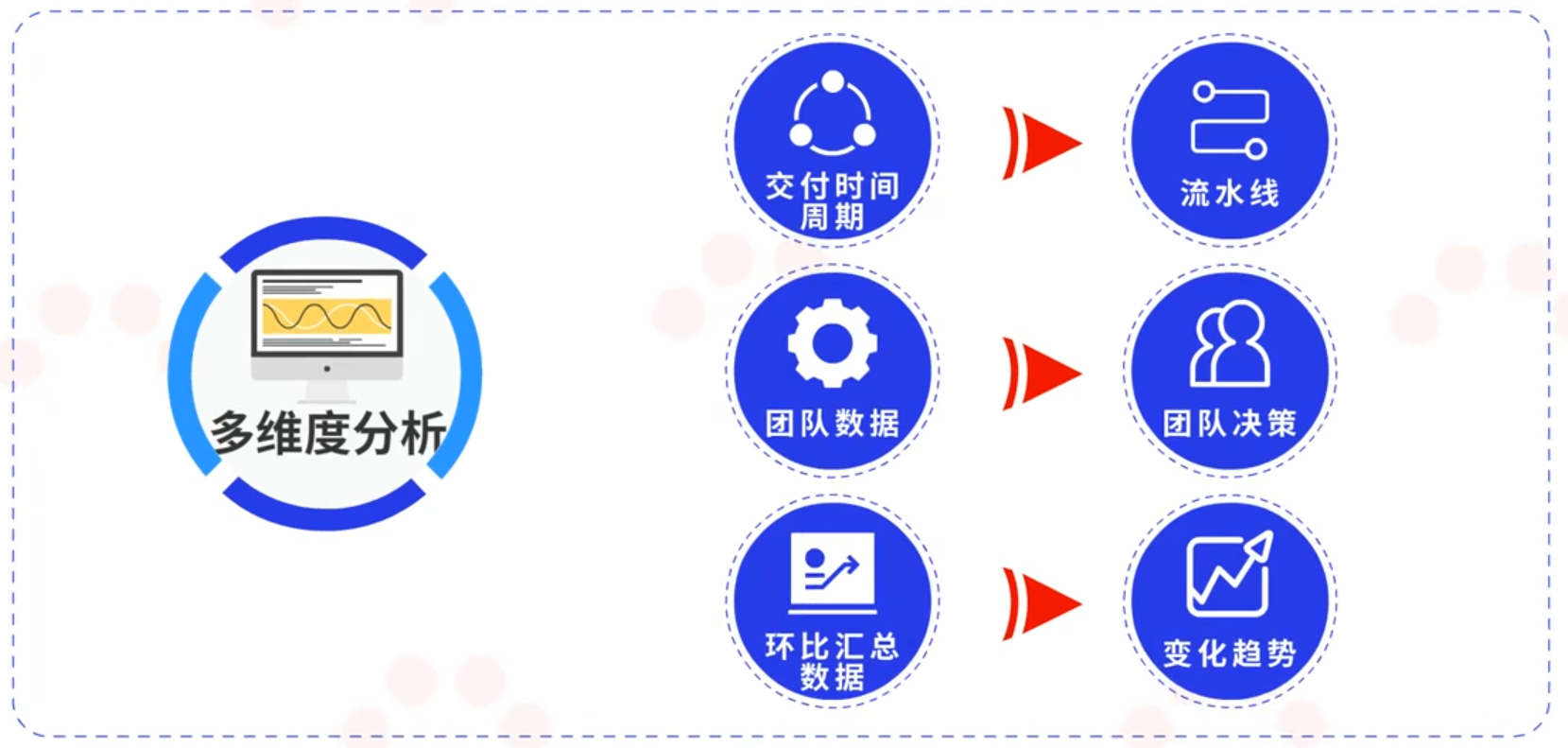
在完成持续部署或持续交付之后,需要结合多个维度的数据对项目整体的研发效率和部署效率进行分析。例如通过交付时间周期的长短变化来反映流水线为团队带来的价值。再比如通过筛选和展示团队的相关数据,方便团队来进行决策。还有通过环比汇总数据来分析变化的趋势。系统也会通过数据的自动分析和异常报表监控一些关键指标,一旦关键数据出现问题,系统能够及时联系关键人员关注。
通过以上的例子能够发现,持续交付与量化驱动改进是密不可分的,团队能够在度量中发现问题,在度量中看到进步。持续交付就是这样一个不断改进不断优化的过程,通过数据可以量化产出并且指引团队找到痛点并且进一步的深化改进。
二、百度高效研发实战训练营Step2
1 代码的艺术
1.1 《代码的艺术》目的解读
1.1.1 了解公司与学校写代码的不同
在公司写程序和在学校写程序有很大的不同。
在学校写程序时,对于代码的质量要求比较低。
当进入公司之后,做的是工业级的产品,服务用户量可能会到达亿万级,所以相对而言对于代码的质量要求比较高。一些伟大产品中的代码,甚至可以被称为艺术品。
1.1.2 消除对于程序员这个职业的误解
很多人都对程序员这个职业有误解,认为程序员就是码农,认为程序员35岁之后就写不出代码了。还有人认为程序员未来的唯一出路是以后做管理。
希望通过这门课程的学习,能使大家对于程序员有一个新的认识,消除误解。
1.1.3 建立对软件编程的正确认识

在做一件事物时,我们常说“知”与“行”要合一。即:我们需要对这件事物有一个正确的认识,才会有正确的行动。同理,写出好代码的前提,是对软件编程有正确的认识。
1.1.4 明确作为软件工程师的修炼方向
艺术品是由艺术家创造的。艺术家的修炼是有方式方法的。同样,软件工程师的修炼也是方式有方法的。希望通过这门课程,能使大家对软件工程师这个职业有一个全新的认识。
1.2 代码与艺术之间的关系
1.2.1 代码是可以被称为艺术的
艺术,是多种多样、丰富多彩的。同时艺术也是有多个层次的,其实,在我们编写代码时,我们的脑海中也会有类似的感觉。
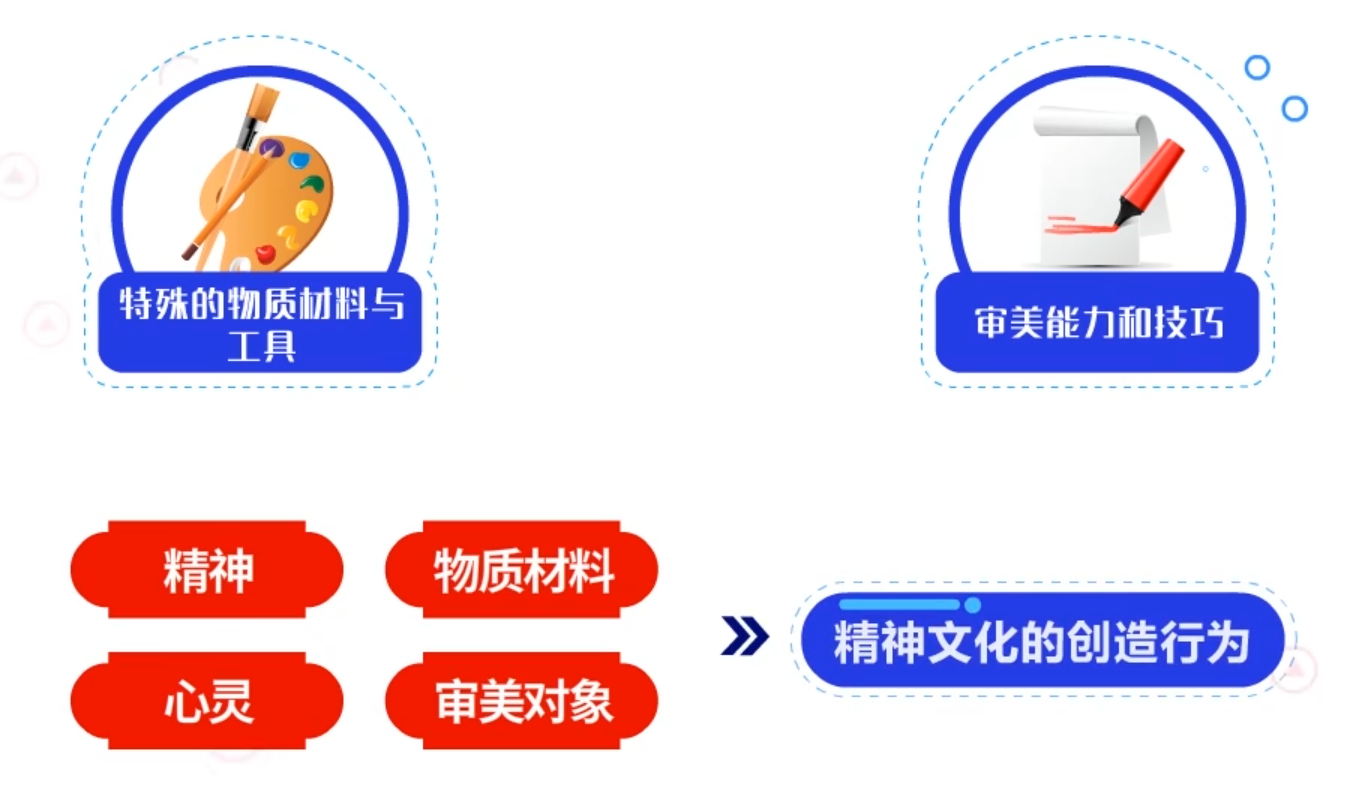
艺术就是人类通过借助特殊的物质材料与工具,运用一定的审美能力和技巧,在精神与物质材料、心灵与审美对象的相互作用下,进行的充满激情与活力的创造性劳动,可以说它是一种精神文化的创造行为,是人的意识形态和生产形态的有机结合体。
写代码也恰恰要经历这样的一个过程。
在编写代码的过程中:
我们借助的物质是计算机系统,借助的工具是设计、编写、编译、调试、测试等。
同样,编写代码需要激情。而且,编写代码是一件非常具有创造性的工作。
代码是人类智慧的结晶,代码反映了一个团队或一个人的精神。代码可以被称为是艺术的。
 1.4.2 艺术可以从不同的角度进行解读、研究与创造
1.4.2 艺术可以从不同的角度进行解读、研究与创造
达芬奇有多幅著名的画作。拿著名的《蒙娜丽莎》这幅画来举例:

站在观众的角度,可能只是在欣赏画中的人物微笑。但是对于画家来说,可能就会考虑画画的手法、构图、光线明暗、色彩对比等等方面。

在艺术方面,可以站在很多不同的角度进行解读。
但是如果要成为一名创作者,我们需要的不仅仅是欣赏的能力,更重要的是从多角度进行解读、研究与创造的能力。
1.4.3 写代码如同艺术创作
写代码的内涵是:
- 写代码这个过程是一个从无序到有序的过程。
- 写代码需要把现实问题转化为数学模型。在写代码的过程中,我们需要有很好的模型能力。
- 写代码实际是一个认识的过程。很多时候,编码的过程也是我们认识未知问题的过程。
- 在写代码的过程中,我们需要综合的全方位的能力。包括把握问题的能力、建立模型的能力、沟通协助的能力、编码执行的能力等等。
- 在写好代码之前,首先需要建立品位。品味是指我们首先要知道什么是好的代码,什么是不好的代码。这样我们才能去不断地调整自己的行为,然后去学习,去提高我们的编码能力,写出具有艺术感的代码。
1.3 软件工程师不等于码农
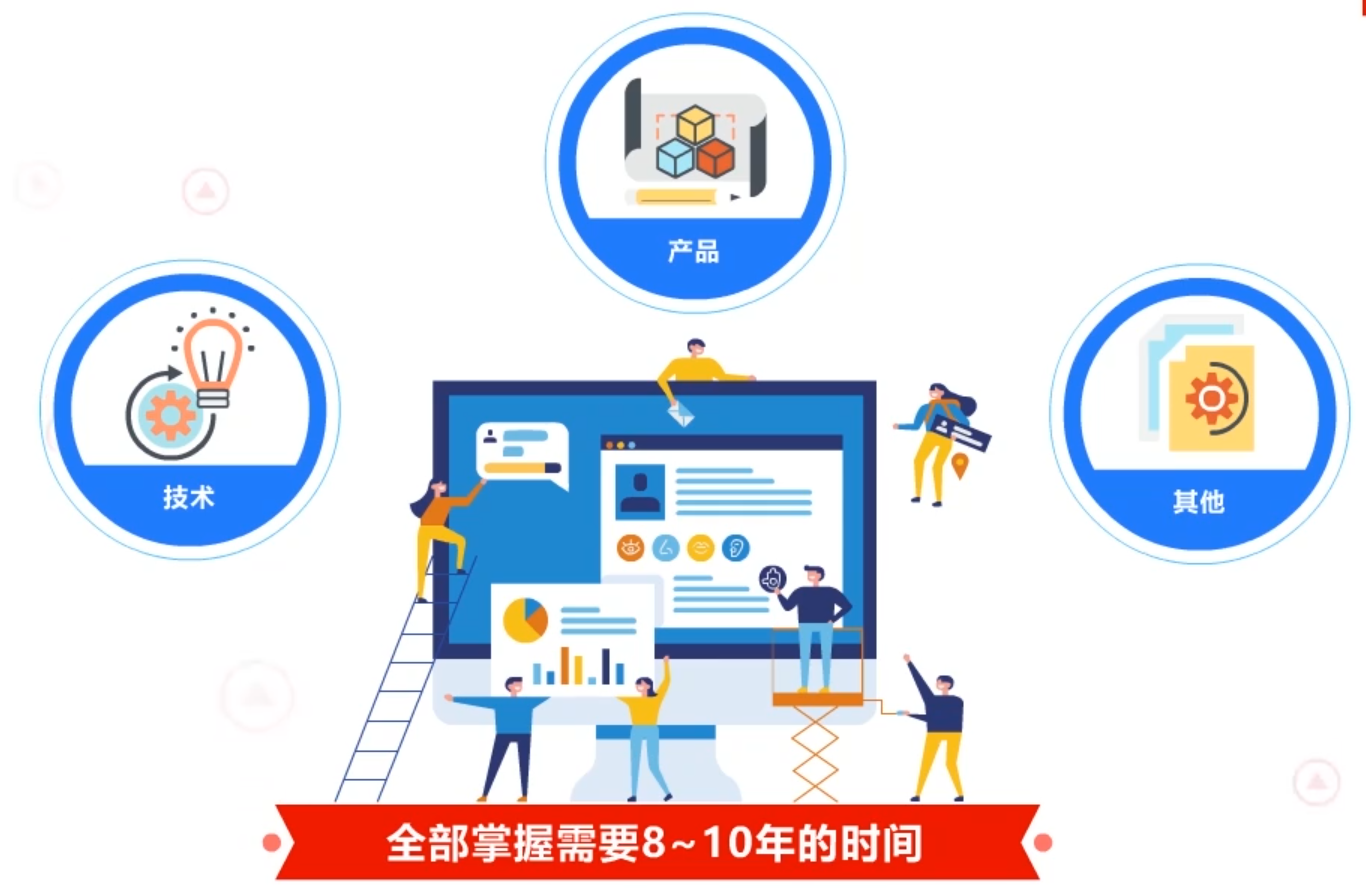
软件工程师不能只会写代码,更需要具有综合的素质。这个综合的素质包括:
1、技术
技术能力是基础。包括但不限于编码能力、数据结构和算法能力、系统结构知识、操作系统知识、计算机网络知识、分布式系统知识等等。
2、产品
要对产品业务有深刻的理解,需要了解产品交互设计、产品数据统计、产品业务运营等。
3、其他
要了解一些管理知识,需要知道项目是怎么管理的 ,如何去协调多个人一起去完成一个项目。有一些项目需要具有很强的研究与创新方面的能力。
以上这些能力素质,是一个软件工程师需要具有的综合素质。要成为一个全部掌握这些素质系统工程师至少需要8~10年的时间。
所以,软件工程师绝对不是一个只会简单编写代码就可以的职业。软件工程师不等于码农。
1.4 正确认识代码实践方面的问题
1.4.1 什么是好代码,好的代码有哪些标准
好代码的标准是:
①高效、②鲁棒、③简洁、④简短、⑤可共享、
⑥可测试、⑦可移植、⑧可监控、⑨可运维、⑩可扩展。

将以上十条标准进行总结精简,可以归纳为:
(1)代码的正确和性能;
(2)代码的可读和可维护性;
(3)代码的可运维和可运营;
(4)代码的可共享和可重用。

了解完好代码的标准,接下来我们来看一下不好的代码主要表现在哪些方面:
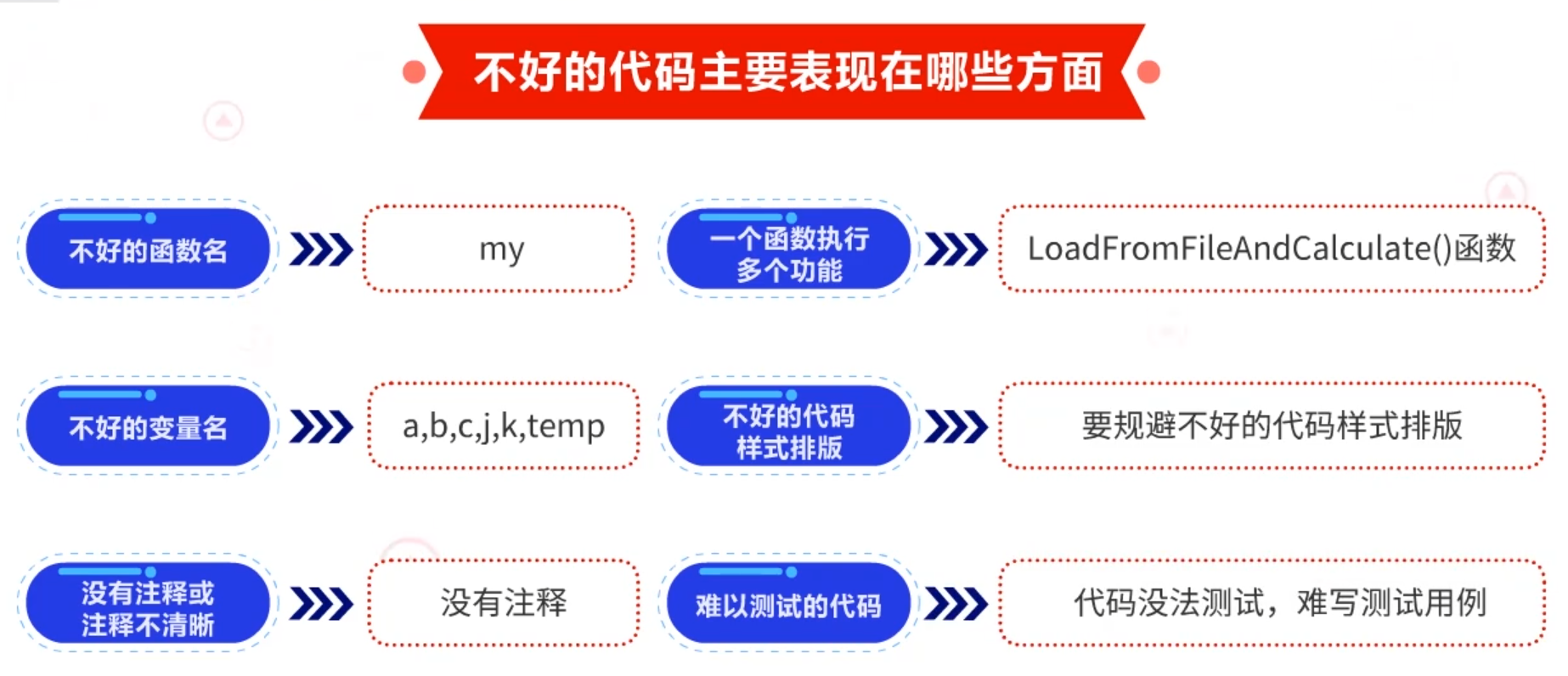
- 不好的函数名
比如,在函数名中,加my等单词,这属于很不专业的用法。
- 不好的变量名
比如,看不出任何含义的a,b,c,j,k,temp等变量名。
- 没有注释或注释不清晰
没有注释的代码是非常难读懂的。注释不清晰往往是因为文字功底或者描述能力欠缺,从而导致无法通过注释把代码的执行原理讲解清楚。
- 一个函数执行多个功能
比如LoadFromFileAndCalculate()函数,它既执行了文件中去加载数据,还执行了计算功能。像这样的函数,我们建议把它切分成两个单独的函数。
- 不好的代码样式排版
代码的样式排版在某种程度上体现了代码的一种逻辑。好的代码排版能增强代码的可读性和逻辑性。我们在写代码时,要规避不好的代码样式排版。
- 难以测试的代码
代码没法测试,难写测试用例,这些都是一些不好的表现。
1.4.2 好的代码从哪里来
代码不只是“写”出来的。实际上,在整个项目中,真正的编码时间约占项目整体时间的10%。好的代码是多个环节工作共同作用的结果。

这些环节包括:
- 在编码前,要进行需求分析和系统设计。
- 在编码过程中,要注意做单元测试。
- 在编码后,要做集成测试,要上线,要持续运营,要迭代改进。
一个好的系统或产品,是以上几个环节持续循环的结果。
接下来我们着重介绍一下重点环节——需求分析和系统设计。
1. 认识需求分析和系统设计的重要性
需求分析和系统设计在软件开发中经常被忽略或轻视,但是这两点都是非常重要的环节。
人们的直觉往往是拿到一个项目就想尽快把它写出来并运行,感觉这样的路径是最快的。
但是实际上在软件前期需求分析和系统设计投入更多的成本,会在后期节省更多的消耗。即:前期更多的投入,收益往往最大。
原因是:如果我们开始的设计做错的话,那么后期开发、测试、上线、调试这些成本都会被浪费掉。

2. 清楚需求分析和系统设计的差别
需求分析和系统设计是有泾渭分明的区别的,为了避免这两者相互混杂,我们需要清楚需求分析和系统设计各自的内涵。
需求分析主要是定义系统或软件的黑盒行为,即:外部行为。比如,系统从外部来看能够执行什么功能。
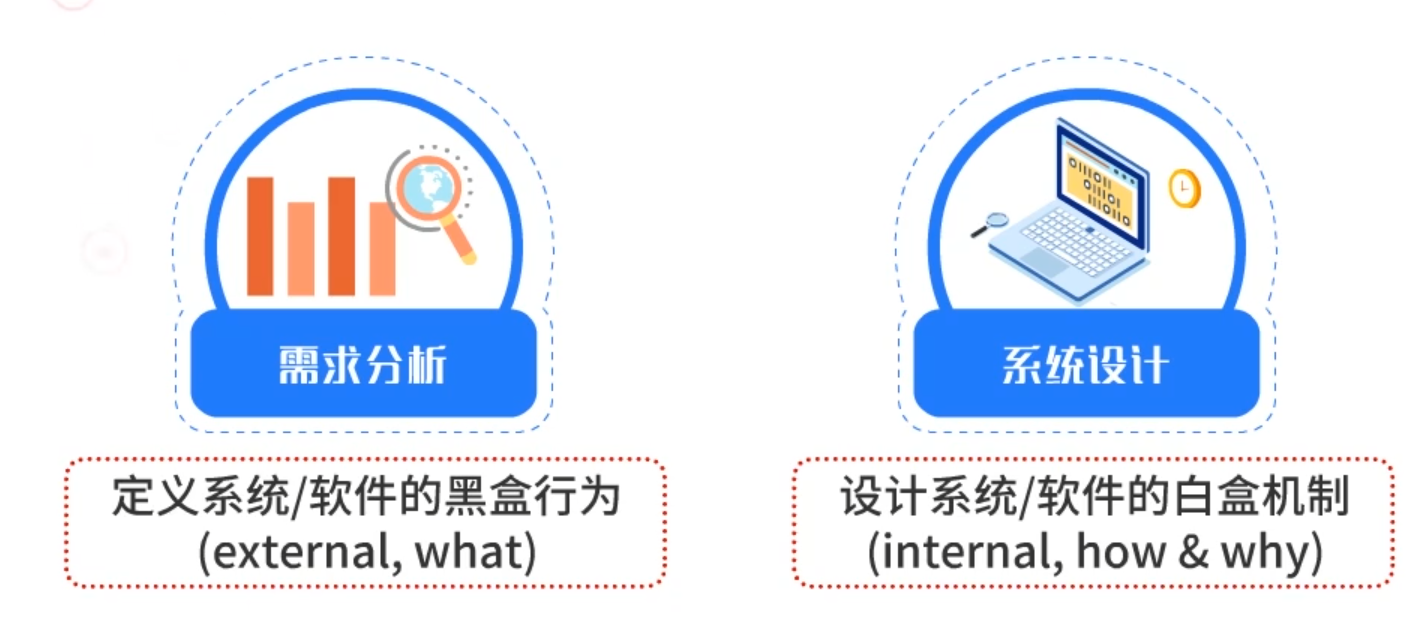
系统设计主要是设计系统或软件的白盒机制。即:内部行为。比如,系统从内部来看,是怎么做出来的,为什么这么做。
3. 需求分析的注意要点
要点一:清楚怎么用寥寥数语勾勒出一个系统的功能。
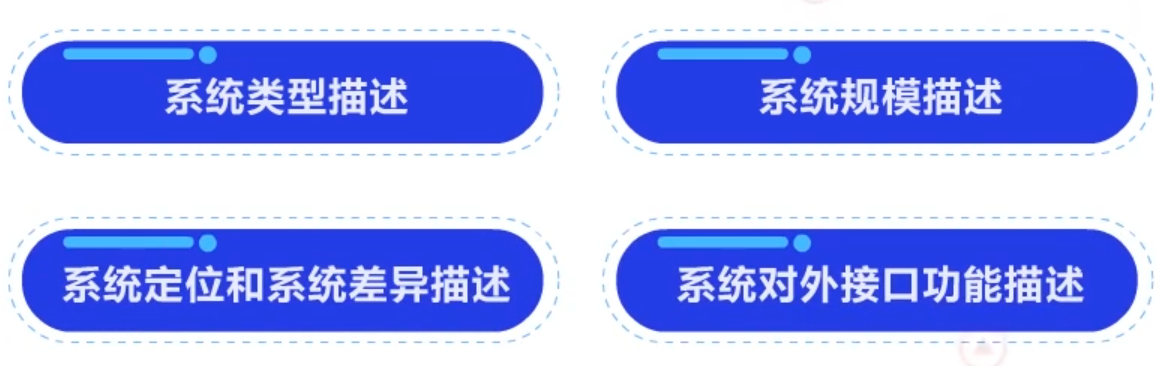
每个系统都有自己的定位,我们可以从简洁的总体描述,展开到具体的需求描述。
需求描述的内容基本包括:
系统类型描述
系统规模描述
- 系统定位和系统差异描述
- 系统对外接口功能描述
要点二:需求分析需要用精确的数字来描述。
需求分析中会涉及大量的数据分析,这些分析都需要精确的数字来进行支撑。
4. 系统设计的注意要点

要点一、清楚什么是系统架构
系统架构,英文名 System Architectrue。在wiki上有一个英文定义阐述了系统架构是一个概念的模型,它定义了系统的结构、行为、更多的视图。
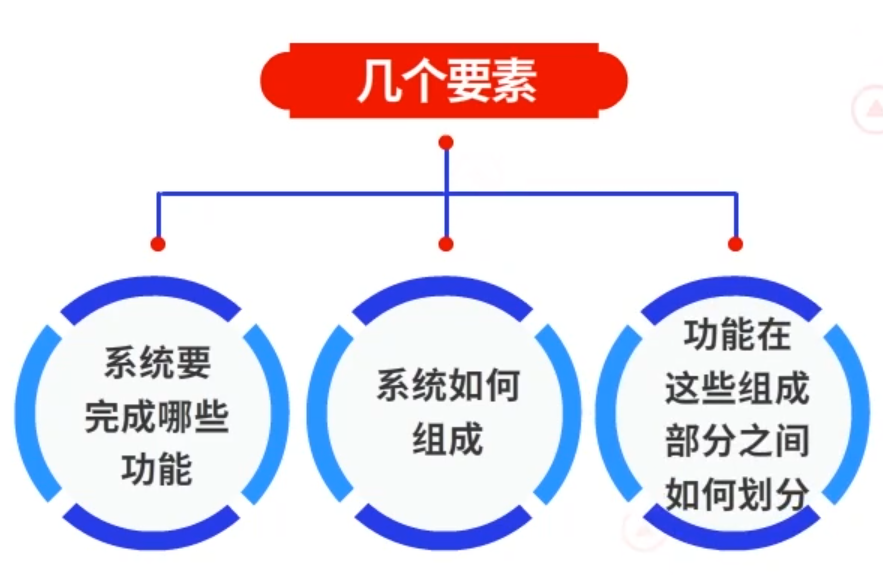
进一步解读系统架构,它的几个要素是:
①系统要完成哪些功能
②系统如何组成
③功能在这些组成部分之间如何划分
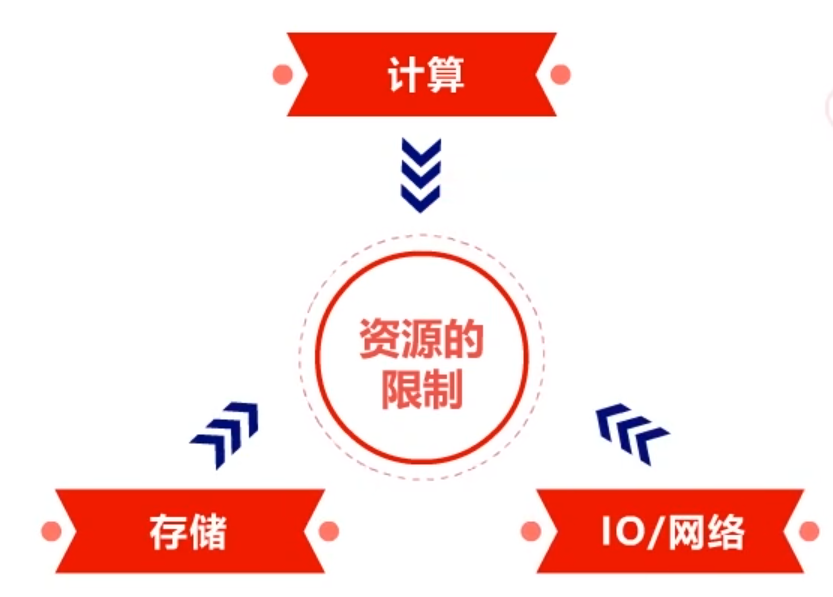
要点二、注意系统设计的约束
重点是资源的限制。比如,计算的资源限制,存储的资源限制,IO网络的资源限制等。
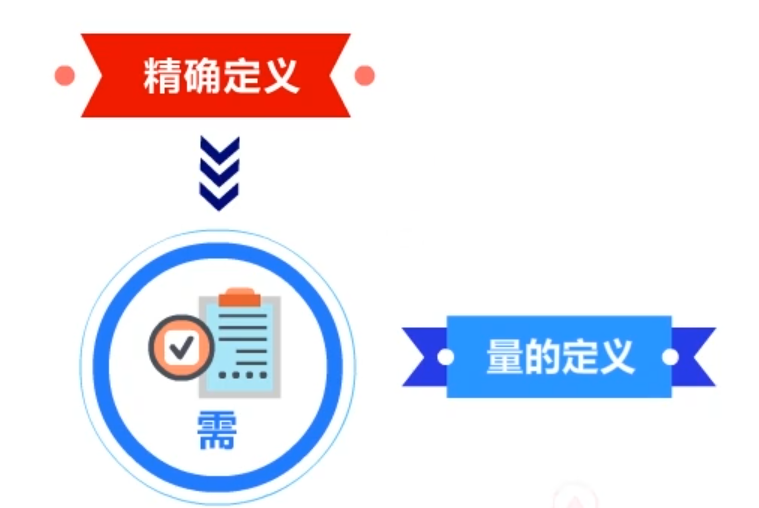
要点三、清楚需求是系统设计决策的来源
精确定义需求中的各个细节,以及量的定义,对系统设计的决策起着重要的作用。
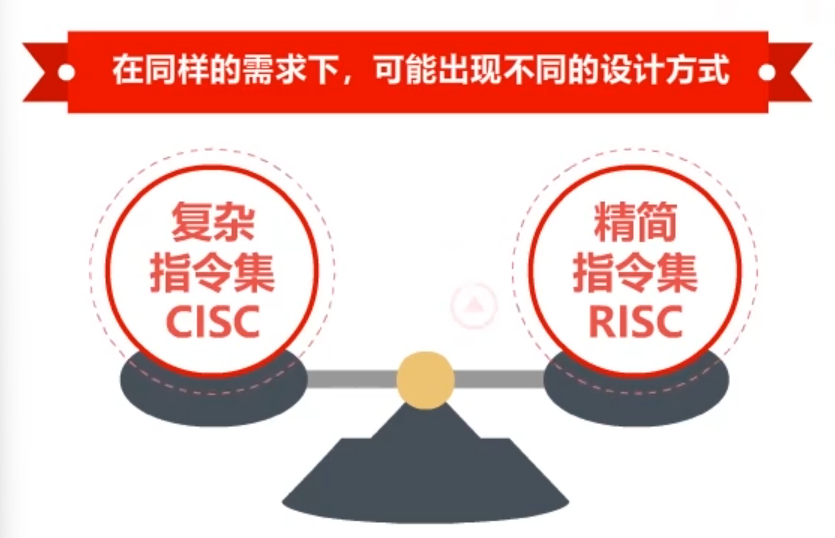
要点四、系统设计的风格与哲学
在同样的需求下,可能出现不同的设计方式。即目的相同,设计不同。比如:复杂指令集和精简指令集的设计差异。
一个好的系统是在合适假设下的精确平衡。一个通用的系统在某些方面是不如专用系统的。每个系统每个组件的功能都应该足够的专一和单一。每个组件是指子系统或模块等。功能的单一是复用和扩展的基础。倘若不单一,未来就有可能很难进行复用和扩展。
子系统或模块之间的关系应该是简单而清晰的。软件中最复杂的是耦合,如果各系统之间的接口定义非常复杂,那么未来便很难控制系统的健康发展。
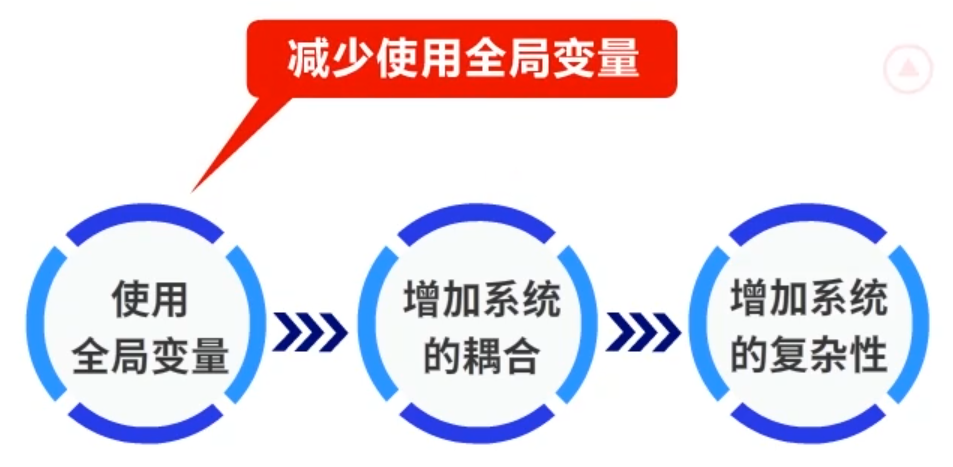
值得注意的是,使用全局变量就是在增加系统的耦合,从而增加系统的复杂性,所以在系统中需要减少使用全局变量。
要点五、清楚接口的重要性
接口,英文名Interface。系统对外的接口比系统实现本身还要更加重要,接口的设计开发不容忽视。
接口主要包括:
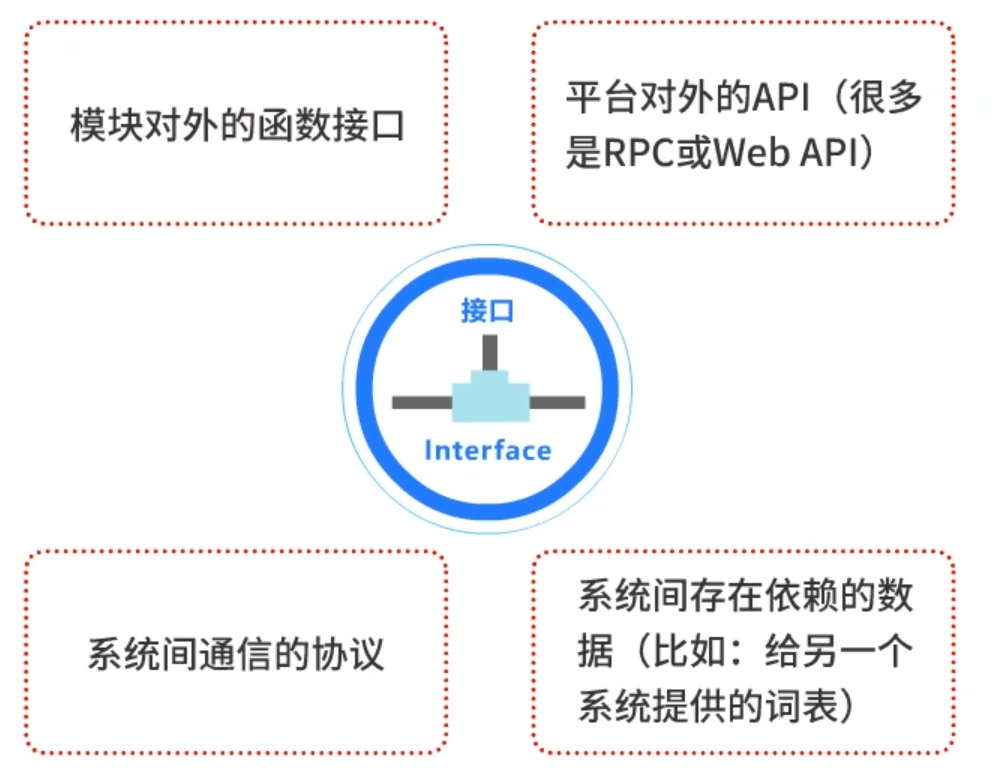
接口重要的原因在于:
①接口定义了功能。如果定义的功能不正确,那么系统的可用性与价值便会大打折扣。
②接口决定了系统和系统外部之间的关系。相对于内部而言,外部关系确定后非常难以修改。
接口的修改需要非常慎重且要考虑周全。
后期接口修改时主要注意两点:
- 合理好用。新改的接口应该是非常合理好用的。不能使调度方感觉我们做的接口非常难以使用。
- 修改时需要向前兼容。新改的接口应该尽量实现前项的兼容。不能出现当新接口上线时其他程序无法使用的情况。
1.4.3 如何写好代码
1 代码也是一种表达方式
在一个项目中,软件的维护成本远远高于开发成本,而且超过50%的项目时间都是用于沟通。
常规意义的沟通方式主要有面对面交流、Email、文档或网络电话会议等。但是其实 代码也是一种沟通方式。
在计算机早期,我们使用机器语言或汇编语言,更多的是考虑代码如何更高效率地执行。
然而,随着技术的进步,代码编译器的逐渐完善,我们写代码时更多的是要考虑如何让其他人看得懂、看得清楚。于是,编程规范应运而生。
编程规范主要包含:
- 如何规范的表达代码。
- 语言使用的相关注意事项。
基于编程规范,看代码的理想场景是:
- 看别人的代码,感觉和看自己的代码一样。
- 看代码时能够专注于逻辑,而不是格式方面。
- 看代码时不用想太多。
2 代码书写过程中的细节问题
1. 关于模块
模块,是程序的基本组成单位。在一个模块内,会涉及它的数据、函数或类。对于Python、Go、C语言这样的程序来说,一个后缀名为.py 、 .c或.go的文件就是一个模块。
每一个模块需要有明确的功能。需要符合紧内聚,松耦合。模块切分的是否合理对于软件架构的稳定起着至关重要的左右。
切分模块的方法:
先区分数据类的模块和过程类的模块。
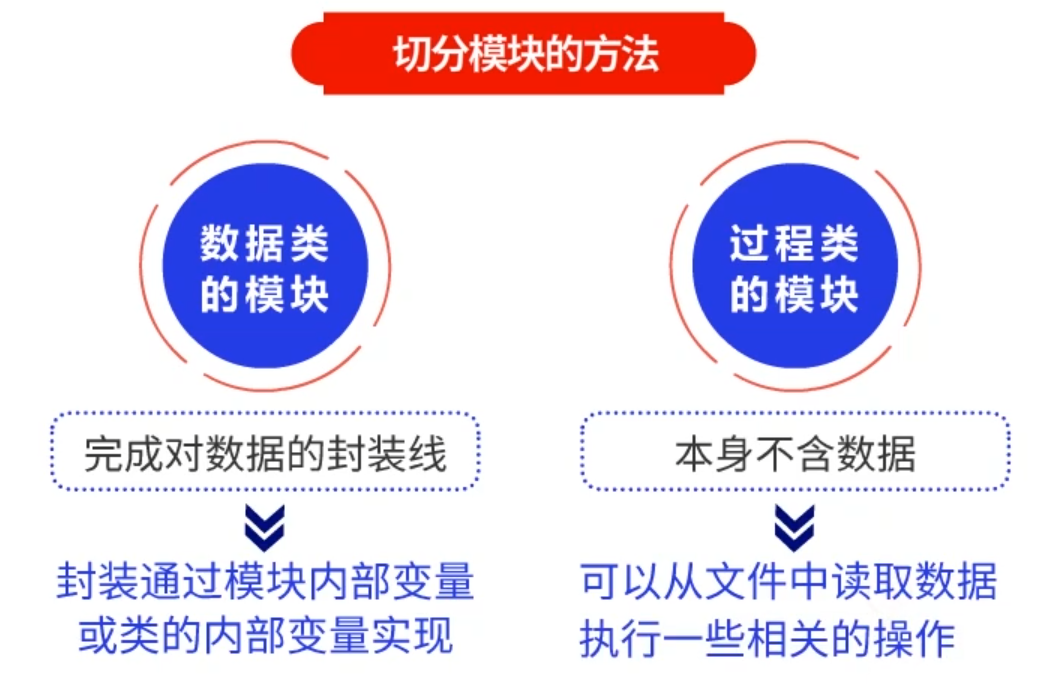
数据类的模块:主要是要完成对数据的封装。封装往往是通过模块内部变量或类的内部变量来实现的。
过程类的模块:本身不含数据。过程类模块可以从文件中去读取一个数据,或者执行一些相关的操作。过程类模块可以调用其他数据类模块或过程类模块。

编写程序时,我们需要注意减少模块间的耦合。*减少模块间的耦合,有利于降低软件复杂性,明确接口关系。*
2. 关于类和函数
类和函数是两种不同的类型,有他们各自适用的范围。另外,遇见和类的成员变量无关的函数时,可以将该函数抽出来,作为一个独立的函数使用,这样便于未来的复用。
3. 关于面向对象
面向对象,是一个优秀的编程方法和范式,但是真正理解的人并不多。
面向对象的本质是数据封装。这就要求我们在写程序的过程中应该从数据的角度开始想问题,而不是从执行过程的角度开始想问题。
我们需要注意一个普遍的错误认知,即:C语言是面向过程的,C++是面向对象的。
实际上,C语言是基于对象的,它和C++的区别主要是没有多态和继承。
C++是一个经常被滥用的语言。因为C++有太强的功能。
作为软件工程师,我们最重要的任务是去实现出我们所需要的功能,语言只是我们的工具。

另外,在系统中,我们应该谨慎地使用多态和继承。如果一个系统中,类的继承超过三层,那么这个系统的复杂度便很难把握。
有这样一个悖论:很好的继承模型是基于对需求的准确把握,而在我们在初始设计阶段往往对需求理解的不透彻。系统在初始阶段可能只是一个很简单的原型,然后通过不断地迭代完善,才逐步发展起来变好的。
4. 关于模块内部的组成
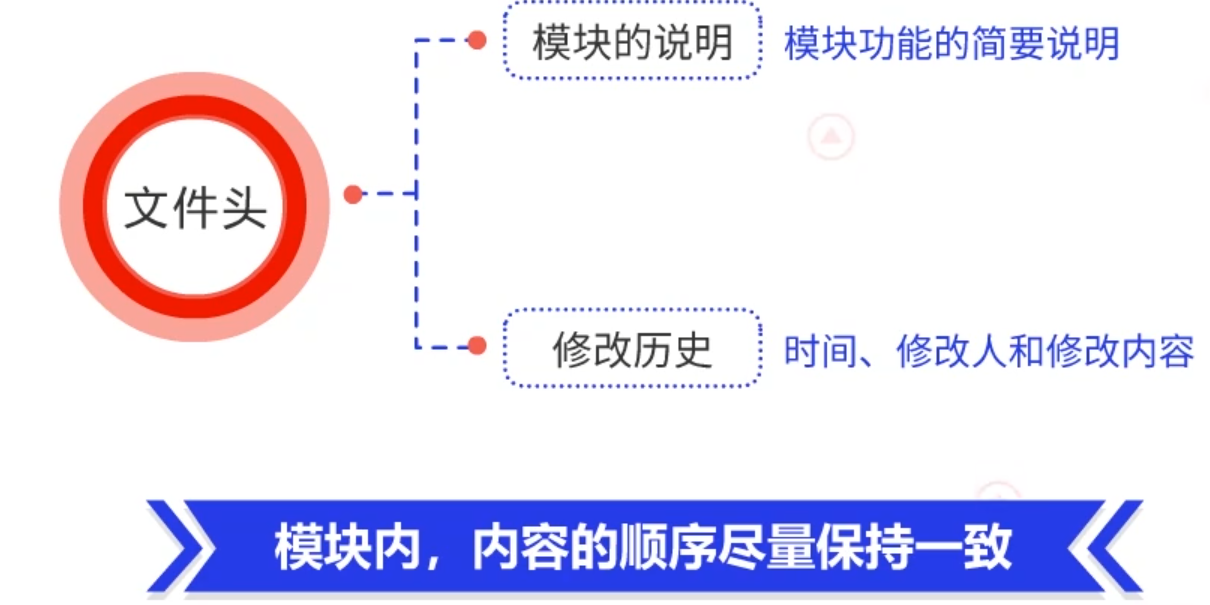
一个模块,比如.py、.c或.go这样一个模块,它的内部组成主要是:在文件头中,需要对模块的功能进行简要说明。需要把文件的修改历史写清楚,包括修改时间、修改人和修改内容。在模块内,内容的顺序尽量保持一致,以方便未来对内容的搜索查询。
5. 关于函数
函数的切分同样是非常重要的。对于一个函数来说,要有明确的单一功能。
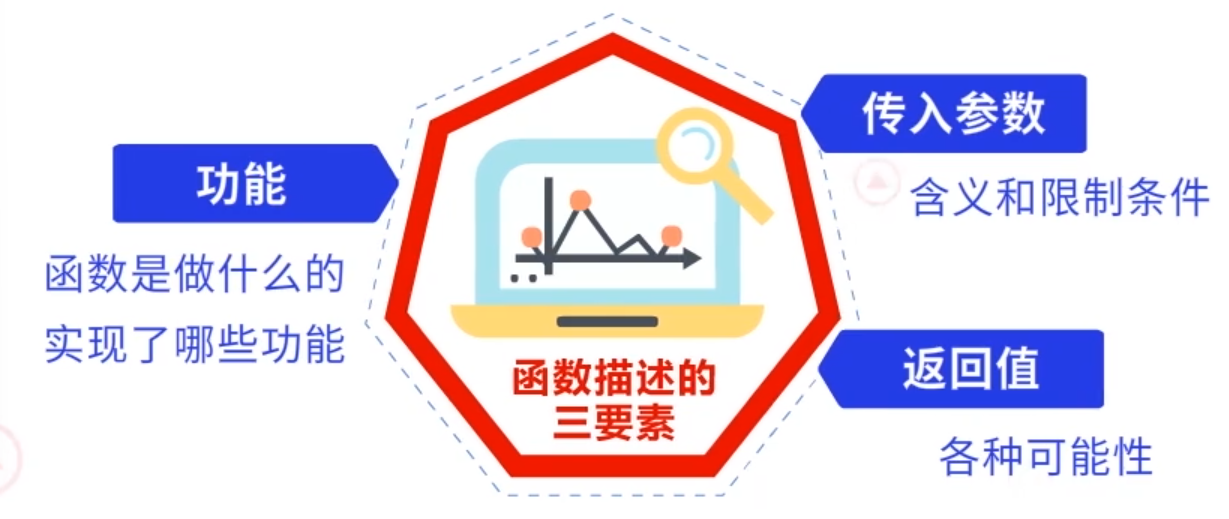
函数描述三要素包括功能、传入参数和返回值。
- 功能描述是指描述这个函数是做什么的、实现了哪些功能。
- 传入参数描述是指描述这个函数中传入参数的含义和限制条件。
- 返回值描述是指描述这个函数中返回值都有哪些可能性。
函数的规模要足够的短小,这是写好程序的秘诀之一。bug往往出现在那些非常长的函数里。
在函数头中,需要对函数的语义做出清晰和准确的说明。我们需要注意函数的返回值。在写函数时,要判断函数的语义,确定返回值的类型。
基于函数的语义,函数的返回值有三种类型。
第一种类型:在“逻辑判断型”函数中,返回布尔类型的值——True或False,表示“真”或“假”。
*第二种类型:*在“操作型”函数中,作为一个动作,返回成功或失败的结果——SUCCESS或ERROR。
*第三种类型:*在“获取数据型”函数中,返回一个“数据”,或者返回“无数据/获取数据失败”。
以“单入口、单出口”的方式书写的方式能够比较清晰地反映出函数的逻辑。尤其是在实现多线程的数据表中,推荐使用一个内部函数来实现“单入口单出口”的方式。
6. 关于代码注释
要重视注释,书写注释要做到清晰明确。在编写程序的过程中,先写注释,后写代码。
7. 关于代码块
代码块的讨论范围是在一个函数内的代码实现。书写代码块的思路是先把代码中的段落分清楚。文章有段落,代码同样有段落。代码的段落背后表达的是我们对于代码的逻辑理解。包括代码的层次、段落划分、逻辑。代码中的空行或空格是帮助我们表达代码逻辑的,并非可有可无。好的代码可以使人在观看时做过一眼明了。
8. 关于命名
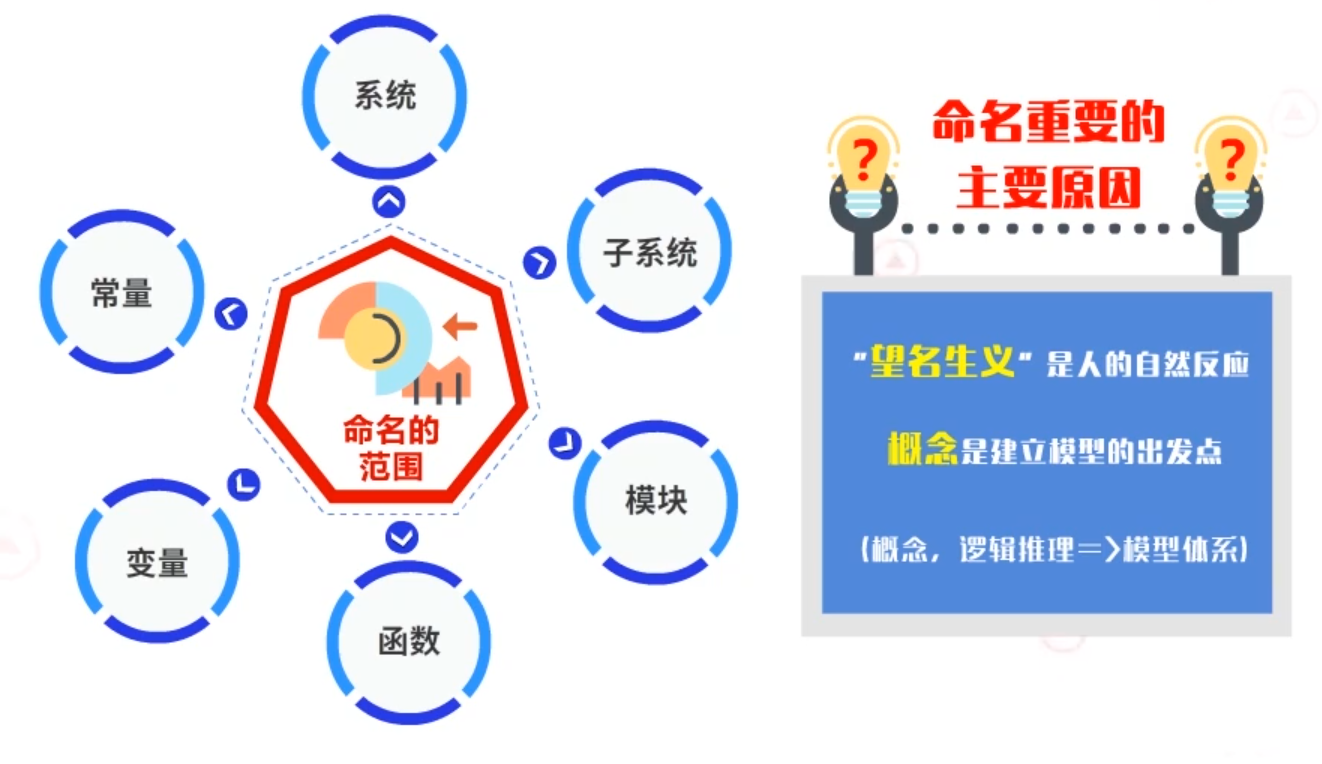
命名包括系统命名、子系统命名、模块命名、函数命名、变量命名、常量命名等。
我们要清楚命名的重要性。命名重要的主要原因为:
一是“望名生义”是人的自然反应。不准确的命名会使人产生误导。
二是概念是建立模型的出发点。好的命名是系统设计的基础。
命名中普遍存在的问题有:
一是名字中不携带任何信息。
二是名字携带的信息是错误的。
命名关系着代码的可读性,需要仔细思考。命名的基本要求是准确、易懂。提高代码命名可读性的方式之一是:在名字的格式中加入下划线、驼峰等。
9. 关于系统的运营
在互联网时代,系统非常依赖运营。并不是我们把代码写完调试通了就可以。
在系统运营过程中,代码的可监测性非常重要。很多程序都是通过线上的不断运行、不断监测、不断优化而迭代完善的,所以我们在编写代码的过程中,要注意尽可能多地暴露出可监控接口。
对于一个系统来说,数据和功能同等重要。
数据收集很重要,数据量够大才能知道这个项目或这个系统的具体收益。

关于系统的运营,我们在设计和编码阶段就需要考虑。即:在设计和编码阶段,提供足够的状态记录,提供方便的对外接口。
1.5 怎样修炼成为优秀的软件工程师
通常人们在判断一名软件工程师的水平时,都会用工作时间、代码量、学历、曾就职的公司等等这类外部因素作为评判标准。
修炼成为优秀的软件工程师,重要的因素有三点:
- 学习-思考-实践
- 知识-方法-精神
- 基础知识是根本
1.5.1 学习-思考-实践
(1)多学习
软件编写的历史已经超过半个世纪,有太多的经验可以借鉴学习。要不断的学习进步。
(2)多思考
学而不思则罔,思而不学则殆。对于做过的项目要去深入思考,复盘写心得。
(3)多实践
要做到知行合一,我们大部分的心得和成长其实是来自于实践中的经历。在学习和思考的基础之上,要多做项目,把学到的理论运用到真正的工作中。
1.5.2 知识-方法-精神
互联网的发展日新月异,对于软件开发来说,知识永远在增加,所以在变化快速的知识世界中,最好的方式是找到方法。
方法就是用来分析问题和解决问题的。虽然说起来简单,但是适合每个人的方法都需要自己去寻找和总结。
在大多数人的成长过程中,并不单单只是鲜花和掌声,更多的时候是在和困难荆棘做斗争。而真正能做出成就的人,都有着远大理想和宏伟志向。所以,光有知识和方法往往是不够的,还需要有精神作为支撑。
几个精神理念:
- 自由精神、独立思想。
人一定要有自己的思考。不要人云亦云,不要随波逐流。
- 对完美的不懈追求。
不要做到一定程度就满意了,而是要去不断的追求一个更好的结果。
1.5.3 基础知识是根本
唐朝著名宰相魏征曾经对唐太宗说过:“求木之长者,必固其根本;欲流之远者,必浚其泉源”,充分表达了基础乃治学之根本。
对于一个软件工程师来说,需要掌握的基础是非常全面的。
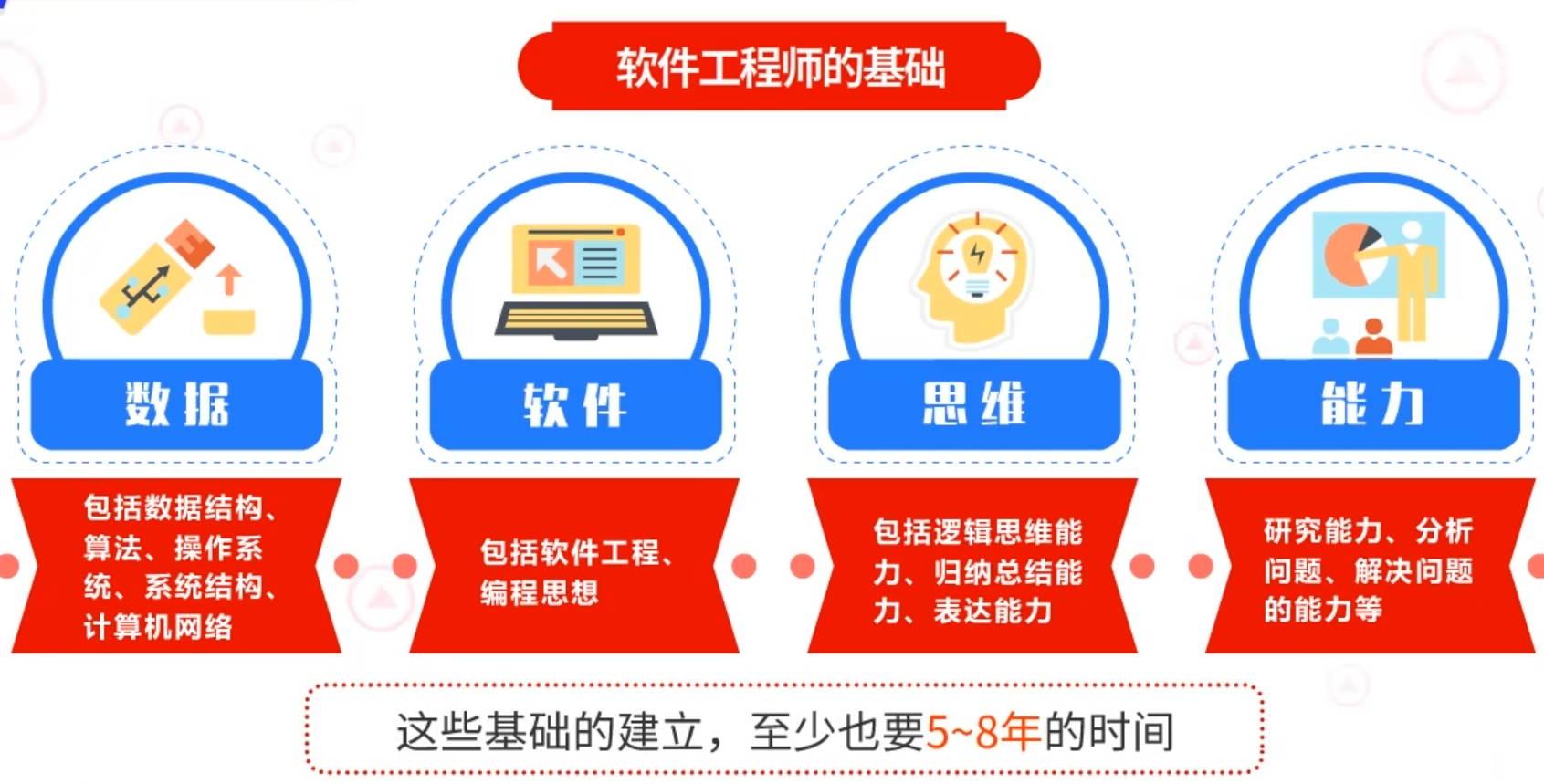
包括数据结构、算法、操作系统、系统结构、计算机网络。包括软件工程、编程思想。包括逻辑思维能力、归纳总结能力、表达能力。还包括研究能力、分析问题、解决问题的能力等。这些基础的建立,至少也要5~8年的时间。
2 Mini-Spider实践
2.1 多线程编程
2.1.1 数据互斥访问
多线程中数据互斥访问的情况非常常见,在真实生产的环境中,经常有开发人员会将一张表的“添加”和“判断是否存在”分为两个接口,这是一种非常常见的错误。
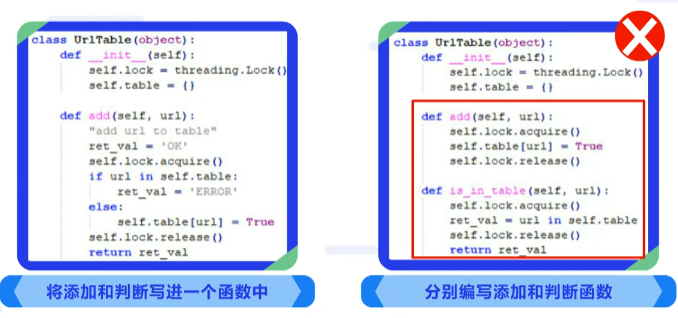
以图中的代码为例,左边的代码是正确的写法,将添加和判断写进一个函数中。右边的代码是典型的错误代码,编写了两个函数,分别是添加和判断函数。
事实上,这种将添加和判断写进一个函数并且运行的实现机制是同8086的底层指令集支持密不可分的。
2.1.2 临界区的注意事项
在代码中,有锁来保护的区域被称为临界区。以图中代码为例,临界区为self.lock.acquire()和self.lock.release()两句话之间的区域。在使用临界区的时候要注意,不要把耗费时间的操作放在临界区内执行。
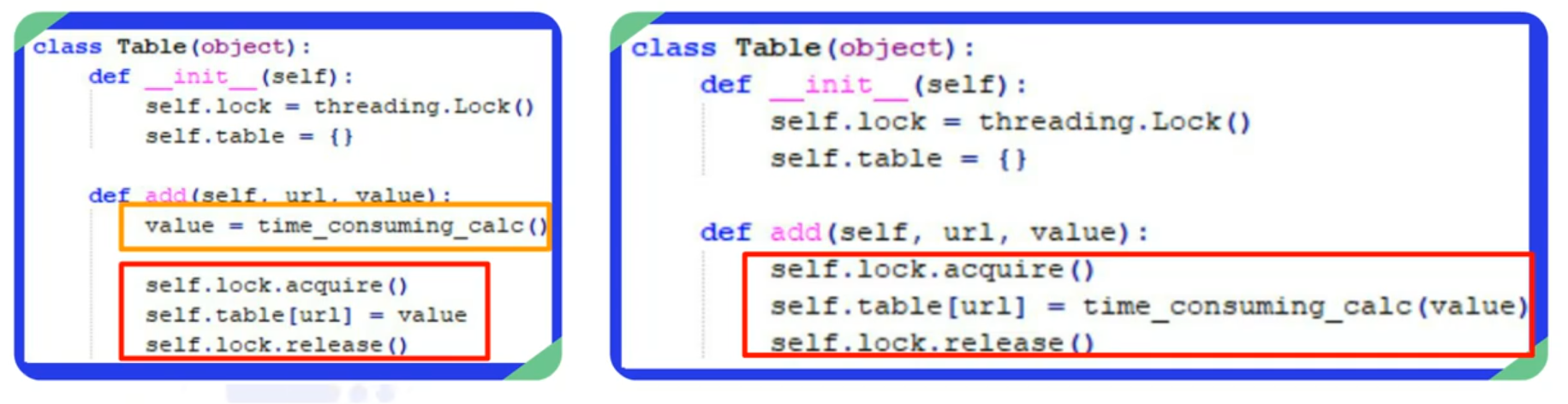
很多开发人员在编写多线程的时候会将耗费时间很多的逻辑放入临界区内,这样会导致无法发挥多线程对于硬件资源最大化利用的优势。
2.1.3 I/O操作的处理
在多线程编程中还要注意对于I/O操作的处理。首先在编写代码的时候要注意不能出现无捕捉的exception,以图中最左边的代码为例,如果不对异常进行捕捉,那么一旦出现问题就不会执行self.lock.release()语句,进而导致死锁的发生。
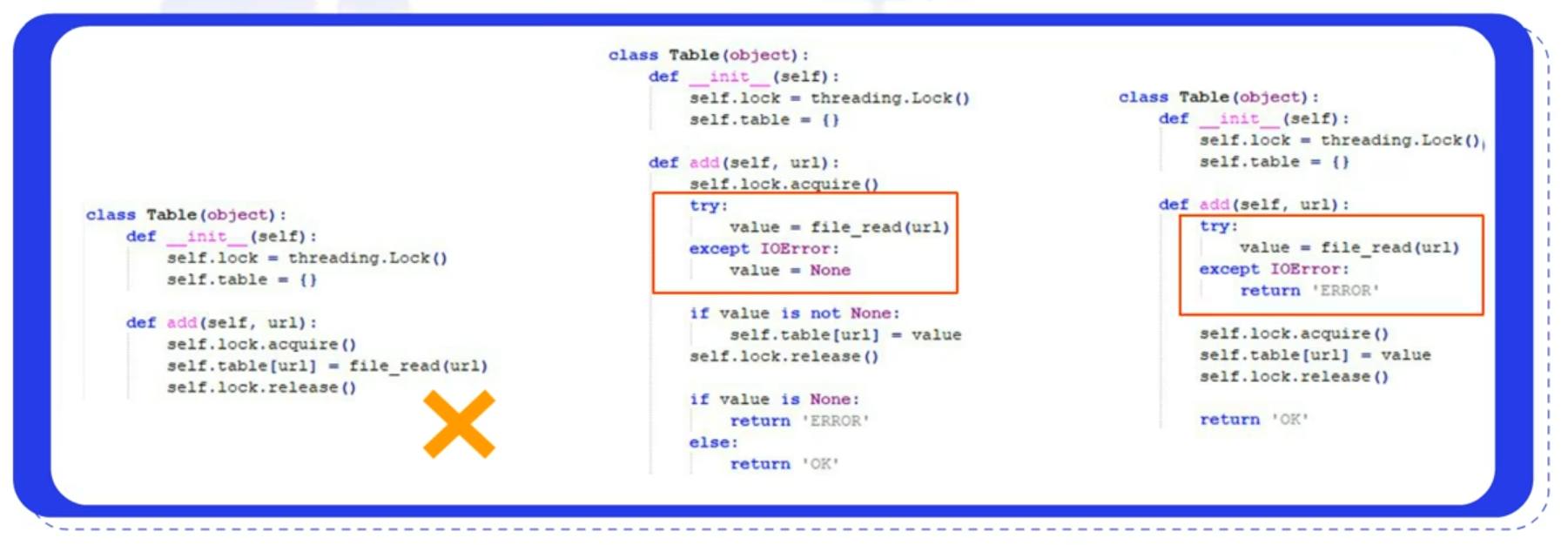
其次,因为异常处理是非常消耗资源的,所以我们也不能像图中中间的代码一样,将异常放在临界区内,要像最右边的代码一样处理。
2.2 细节处理
2.2.1 种子信息的读取
很多开发人员会将种子信息读取的逻辑和其他逻辑耦合在一起,这样是错误的。以图中代码为例,虽然通过_get_seeds函数直接读取文件中的信息并没有书写错误,但是如果后续的开发中文件的格式发生了变化,那就需要重新回来修改这部分的代码。
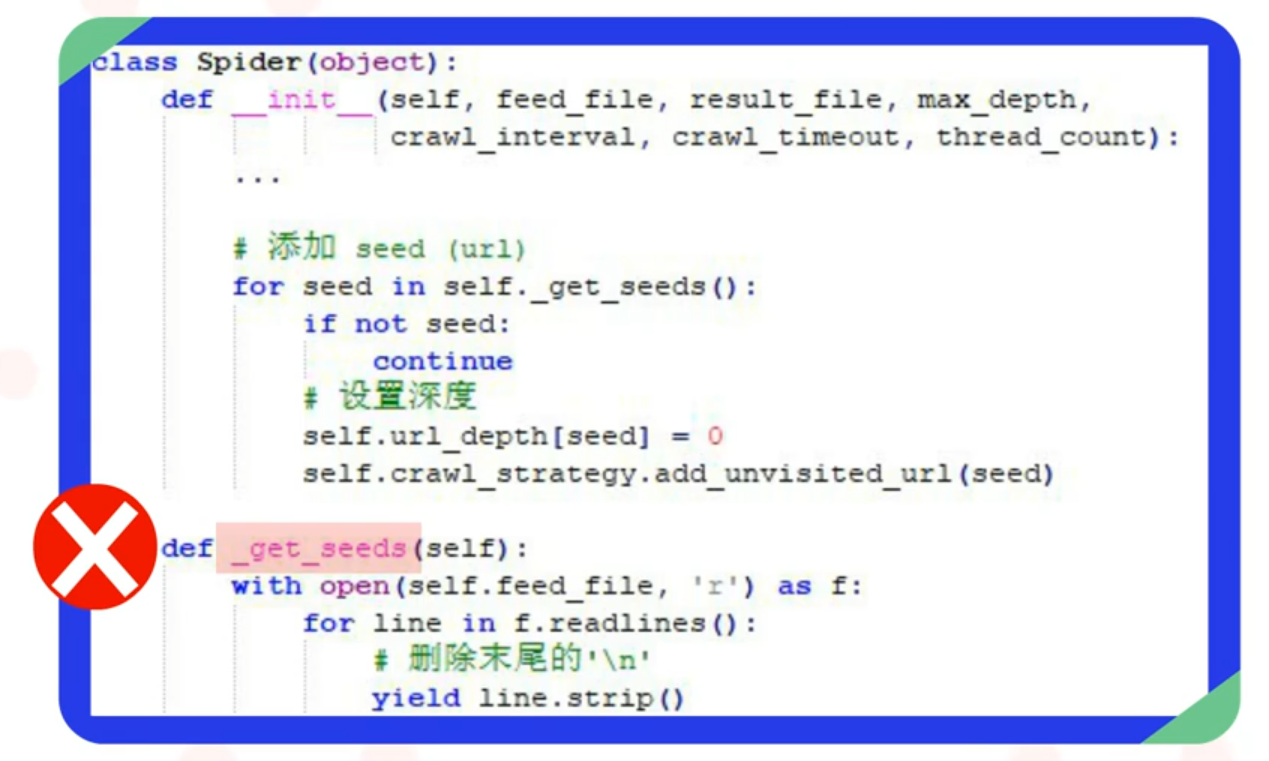
通过上述代码可以发现,模块划分和逻辑的复杂程度是没有关系的。即使是逻辑简单的代码,如果没有做好模块划分,也会变得难于维护。
2.2.2 程序优雅退出
在真实应用中,很多开发人员在实现程序退出功能的时候使用了非常复杂的机制,导致后期维护难度较高。

在实际应用中可以使用python系统库中关于队列的task_done()和join()的机制。
以图中代码为例,左边的代码就是使用了task_done(),中间的代码是主程序中的一种常规逻辑使用。右边是对中间主程序的一种优化,增加了spider.wait(),让整个逻辑可读性更强,更容易被理解。
2.2.3 爬虫的主逻辑编码
很多开发人员编写的主逻辑非常的复杂且难懂。事实上,图中的代码就是一个爬虫的主逻辑的所有代码。可以看到,里面包含了六个步骤。

第一步,从队列中拿到任务。
第二步,读取内容。如果读取失败,则重新读取。如果读取成功,则执行第三步。
第三步,存储数据。
第四步,检查数据深度。
第五步,如果数据深度不足,就进一步解析,并且放到队列中。
第六步,结束任务。
3 代码检查规则背景及总体介绍
3.1 代码检查的意义
- 提高代码可读性,统一规范,方便他人维护,长远来看符合公司内部开源战略。
- 帮助发现代码缺陷,弥补人工代码评审的疏漏,节省代码评审的时间与成本。
- 有助于提前发现问题,节约时间成本,降低缺陷修复成本。
- 促进公司编码规范的落地,在规范制定后借助工具进行准入检查。
- 提升编码规范的可运营性,针对反馈较多的不合理规范进行调整更新。
3.2 代码检查场景及工具
3.2.1 代码检查场景
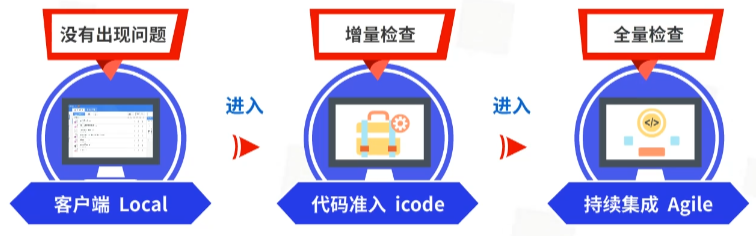
首先是本地研发环节,借助客户端工具,在push发起评审之前进行检查。
若本地代码扫描没有出现问题,就进入第二个环节:代码准入环节,即Code Review,这一环节进行增量检查,属于公司强制要求。
第三个环节:持续集成环节,当代码合入到代码库之后,进行全量检查,业务线根据自身需求来配置。
3.2.2 代码检查工具与服务

代码检查的产品,客户端、SCM(icode)、CI(Agile)之间具有交互性,共同构成整个代码检查环节。
3.2.3 代码检查覆盖范围
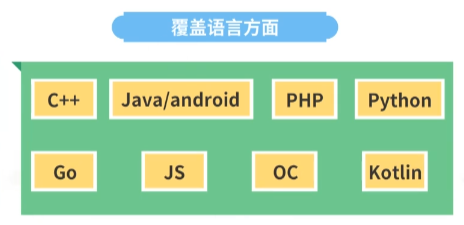
在覆盖语言方面,代码检查目前已经覆盖了包括C++,Java/android, PHP, Python, Go, JS, OC, Kotlin在内的几乎所有主流语言。
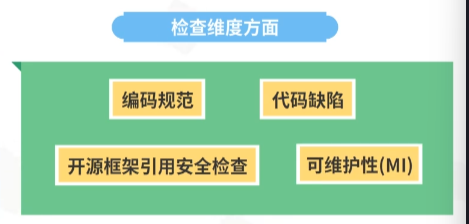
在检查维度方面,代码检查包括编码规范 代码缺陷,开源框架引用安全检查,可维护性(MI)。
3.2.4 代码检查速度
编码规范:只扫描变更文件,检查代码变更行是否符合规范,速度较快。
缺陷检查:需考虑文件依赖、函数调用关系、代码上下文等,相对耗时。
3.3 代码检查规则分级
3.3.1 规则等级梳理
Code Review阶段,所有维度扫描出的问题可以分为以下3个等级:
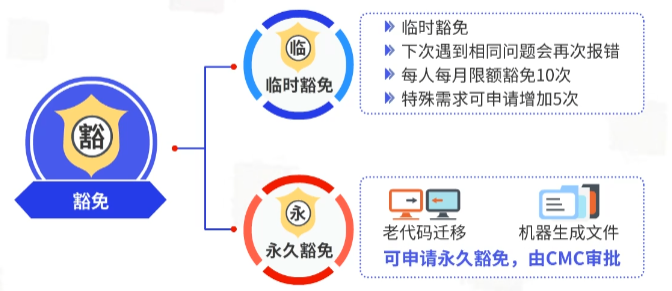
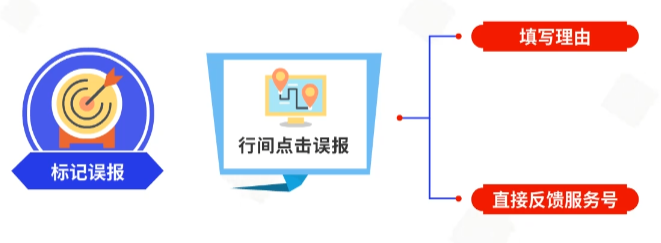
Error:属于需要强制解决的类型,影响代码合入,应视具体情况不同采取修复、临时豁免、标记误报等措施及时处理;
Warning:非强制解决类型,不影响代码含入,很可能存在风险,应尽量修复;
Advice:非强制解决类型,级别相对较低,不影响代码含入,可以选择性修复。
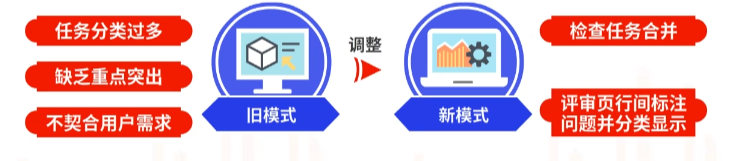
3.3.2 机检任务统一
3.3.3 评审页行间提示

3.3.4 针对豁免、误报、咨询的说明

4 代码检查规则:Python语言案例详解
4.1 Python的代码检查规则

Python代码检查规则主要分为四个大类,分别是代码风格规范、引用规范、定义规范和异常处理规范。
4.1.1 代码风格规范
(1)程序规模规范:
每行不得超过 120 个字符。
定义的函数长度不得超过 120 行。
这意味着,在编写代码时,需要时刻注意自己的程序规模,避免冗余,确保写出简洁而高效的代码。
(2)语句规范
因为Python与其他语言不同,可以不需要明确的标识符表示语句的结尾,所以规定:
禁止以分号结束语句。
在任何情况下,一行只能写一条语句。
(3)括号使用规范
- 除非用于明确算术表达式优先级、元组或者隐式行连接,否则尽量避免冗余的括号。
(4)缩进规范
- 禁止使用Tab进行缩进,而统一使用4个空格进行缩进
需要将单行内容拆成多行写时规定:
- 与首行保持对齐;或者首行留空,从第二行起统一缩进4个空格。
(5)空行规范
- 文件级定义(类或全局函数)之间,相隔两个空行;类方法之间,相隔一个空行。
(6)空格规范
括号之内均不添加空格。
参数列表、索引或切片的左括号前不应加空格。
逗号、分号、冒号之前均不添加空格,而是在它们之后添加一个空格。
所有二元运算符前后各加一个空格。
关键字参数或参数默认值的等号前后不加空格。
(7)注释规范
- 每个文件都必须有文件声明,每个文件声明至少必须包括以下三个方面的信息:版权声明、功能和用途介绍、修改人及联系方式。
另外在使用文档字符串(docstirng)进行注释时,规定:
使用docstring描述模块、函数、类和类方法接口时,docstring必须用三个双引号括起来。
对外接口部分必须使用docstring描述,内部接口视情况自行决定是否写docstring。
接口的docstring描述内容至少包括以下三个方面的信息:功能简介、参数、返回值。如果可能抛出异常,必须特别注明。
4.1.2 引用规范

严格而具体的规定:
- 禁止使用 from……import…… 句式直接导入类或函数,而应在导入库后再行调用。
- 每行只导入一个库。
- 按标准库、第三方库、应用程序自有库的顺序排列import,三个部分之间分别留一个空行。
4.1.3 定义规范
(1)在变量定义方面,我们有强制的规范规定:
- 局部变量使用全小写字母,单词间使用下划线分隔。
- 定义的全局变量必须写在文件头部。
- 常量使用全大写字母,单词间使用下划线分隔
(2)函数的定义规范主要体现在函数的返回值以及默认参数的定义上。
为提高代码可读性,对于函数的返回值,规范要求为:
- 函数返回值必须小于或等于3个。若返回值大于3个,则必须通过各种具名的形式进行包装。
为了保障函数的运行效率以及降低后期维护和纠错的成本,对于函数默认参数的定义有如下要求:
- 仅可使用以下基本类型的常量或字面常量作为默认参数:整数、bool、浮点数、字符串、None。
(3)类定义的规范包括了四个方面的内容:
- 类的命名使用首字母大写的驼峰式命名法。
- 对于类定义的成员:protected成员使用单下划线前缀;private成员使用双下划线前缀。
- 如果一个类没有基类,必须继承自object类。
- 类构造函数应尽量简单,不能包含可能失败或过于复杂的操作。
4.1.4 异常处理规范
在代码编写中应该尽量避免出现代码异常状态,然而错误有时在所难免,对于这些异常状态的处理,有着明确的规范要求:
- 禁止使用双参数形式或字符串形式的语法抛出异常。
- 如需自定义异常,应在模块内定义名为 Error 的异常基类。并且,该基类必须继承自 Exception 。其他异常均由该基类派生而来。
- 除非重新抛出异常,禁止使用 except:语句捕获所有异常, 一般情况下,应使except……:语句捕获具体的异常。
- 捕捉异常时,应当使用 as 语法,禁止使用逗号语法。
4.2 Python编码惯例
4.2.1 让模块既可被导入又可被执行
python不同于编译型语言,而属于脚本语言,是动态的逐行解释运行,没有统一的程序入口。所以,为了方便模块之间的相互导入,我们通常自定义一个 main 函数,并使用一个if 语句, if 内置变量 name == ‘main’ ,在这个if 条件下,再去执行 main函数。这样,我们就能够实现,让模块既可被导入又可执行。
4.2.2 in运算符的使用
in一种简洁而高效的运算符,很多时候,合理的使用in运算符,可以代替大量的重复判断过程,降低时间复杂度,提高代码的运行效率。
4.2.3 不使用临时变量交换两个值
Python有更简洁而高效的语句可以实现交换两个值的操作,并无必要引入临时变量来交换两个值。
4.2.4 用序列构建字符串
对于一个字符串列表、元组等,可以用序列来构建字符串,利用一个空字符串和join函数,就可以避免重复,高效完成相应字符串的构建。
三、百度高效研发实战训练营Step3
1 质量意识
1.1 质量的基本概念
1.1.1 质量重要性的认识
随着技术更新,市场竞争的加剧,质量问题成为困扰不少企业的一大难题,也给一些企业造成了巨大的损失,这就使得项目质量的重要性不断凸显。
通过对于这些失败案例的分析不难发现,项目的质量保证是一个需要项目全体成员参与的重要工作,只有在项目团队的共同努力下,才能有效保证项目的质量,为企业和社会创造价值。
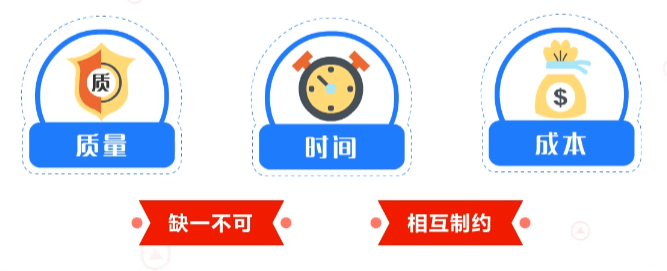
项目管理三要素为质量、时间、成本,三个要素缺一不可、相互制约,一味追求某一要素的做法是不明智的。一个成功的项目必然是在三者的取舍间达成了一个平衡。
1.1.2 质量保证和测试的关系
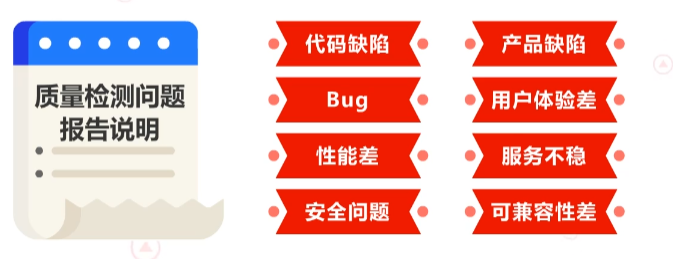
质量问题有很多种,常见的有代码缺陷、产品缺陷、Bug、用户体验差、性能差、服务不稳、安全问题、可兼容性差等。我们经常通过测试来发现问题,并将发现的问题分功能性测试类问题和用户体验评估类问题。
测试工作是质量保证工作中的重要一环,但是我们应该认识到,质量保证工作不能只依靠测试的反馈,而应该贯穿项目开发的整个过程。
1.1.3 Bug的基本认识
Bug是程序中的缺陷和问题,属于功能性测试类问题的范畴, Bug是一种很常见的质量问题,也是我们在项目开发中应该尽量减少或避免的质量问题。
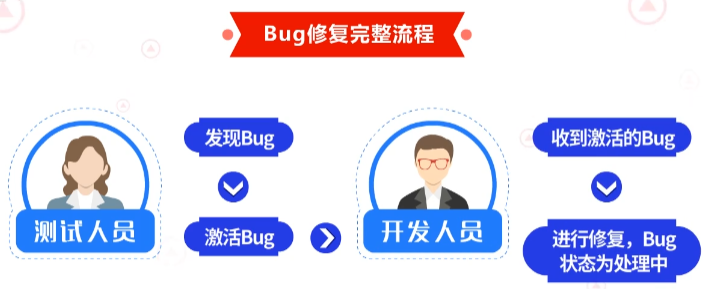
Bug的修复有一套完整的规定流程。
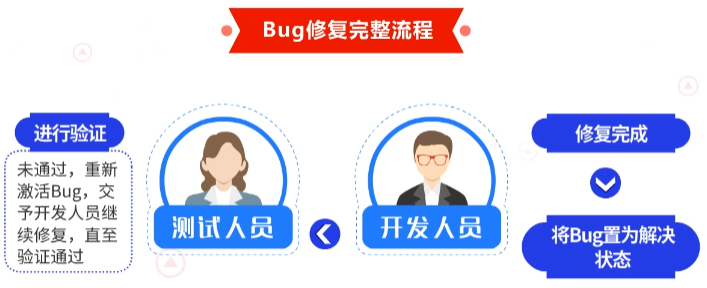
首先,测试人员或者用户发现Bug后,将其置为激活状态;开发人员收到激活状态的Bug后,对其进行修复,修复过程中, Bug状态为处理中;修复完成后,开发人员将其置为解决状态;测试人员再对其进行验证,若通过,则将其关闭,否则,重新激活Bug即重启状态,交予开发人员继续修复,直至验证通过。
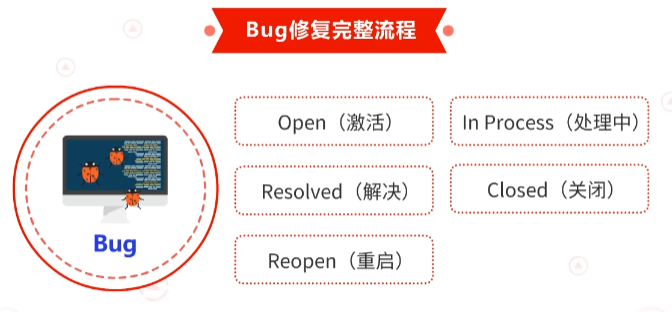
从这一流程可以看到,Bug有五种状态,Open(激活)、In Process(处理中)、Resolved(解决)、closed(关闭)、Reopen(重启)。
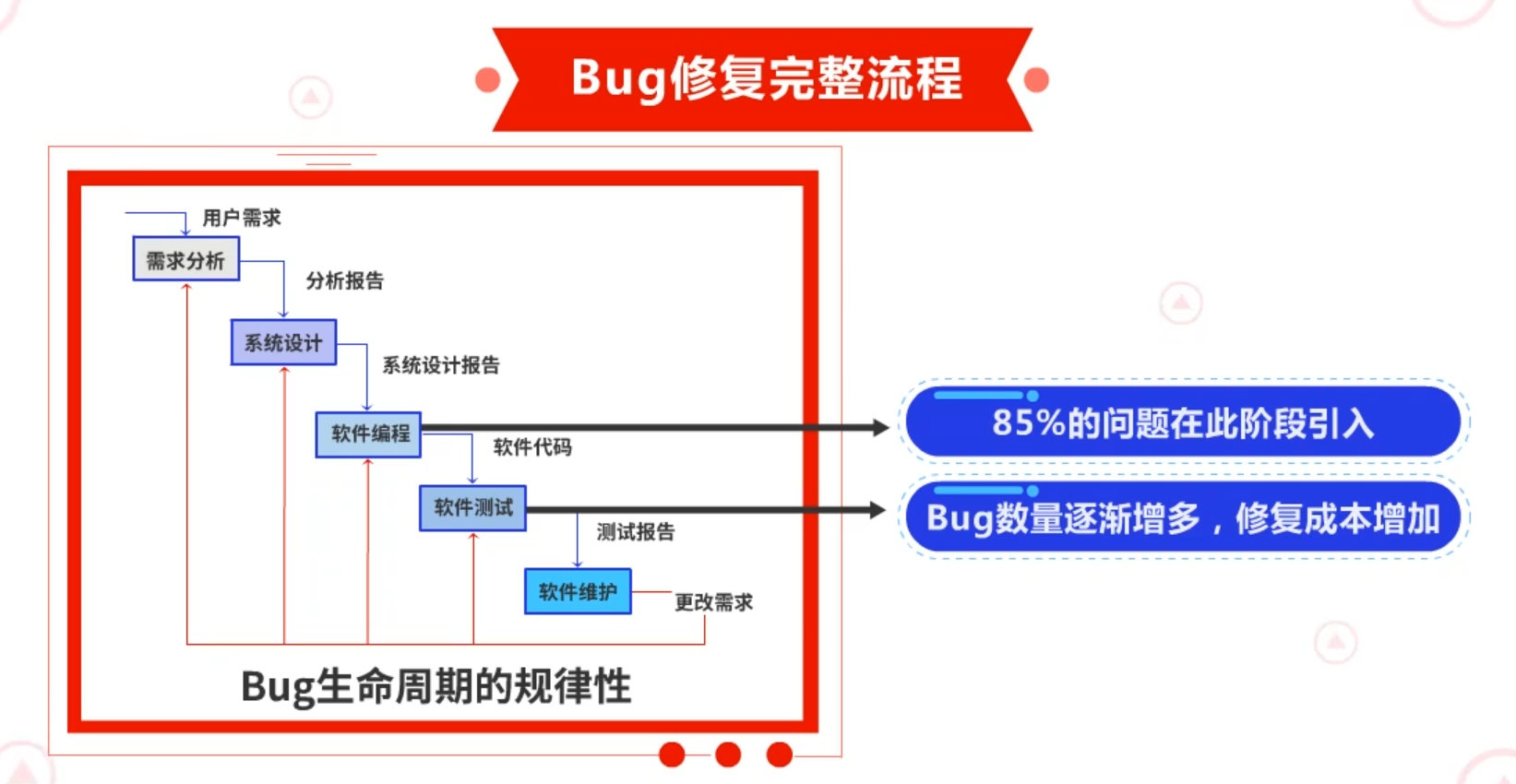
Bug生命周期有一定规律性。以传统软件中的瀑布模型举例,85%的问题在项目初期的编码阶段引入,在后期测试阶段,发现Bug的数量会逐渐增多,与之对应的修复成本也会急剧增加。可见,降低修复成本最有效的方式,就是在Bug引入的阶段就及时发现并修复Bug。
1.2 Bug提交方法
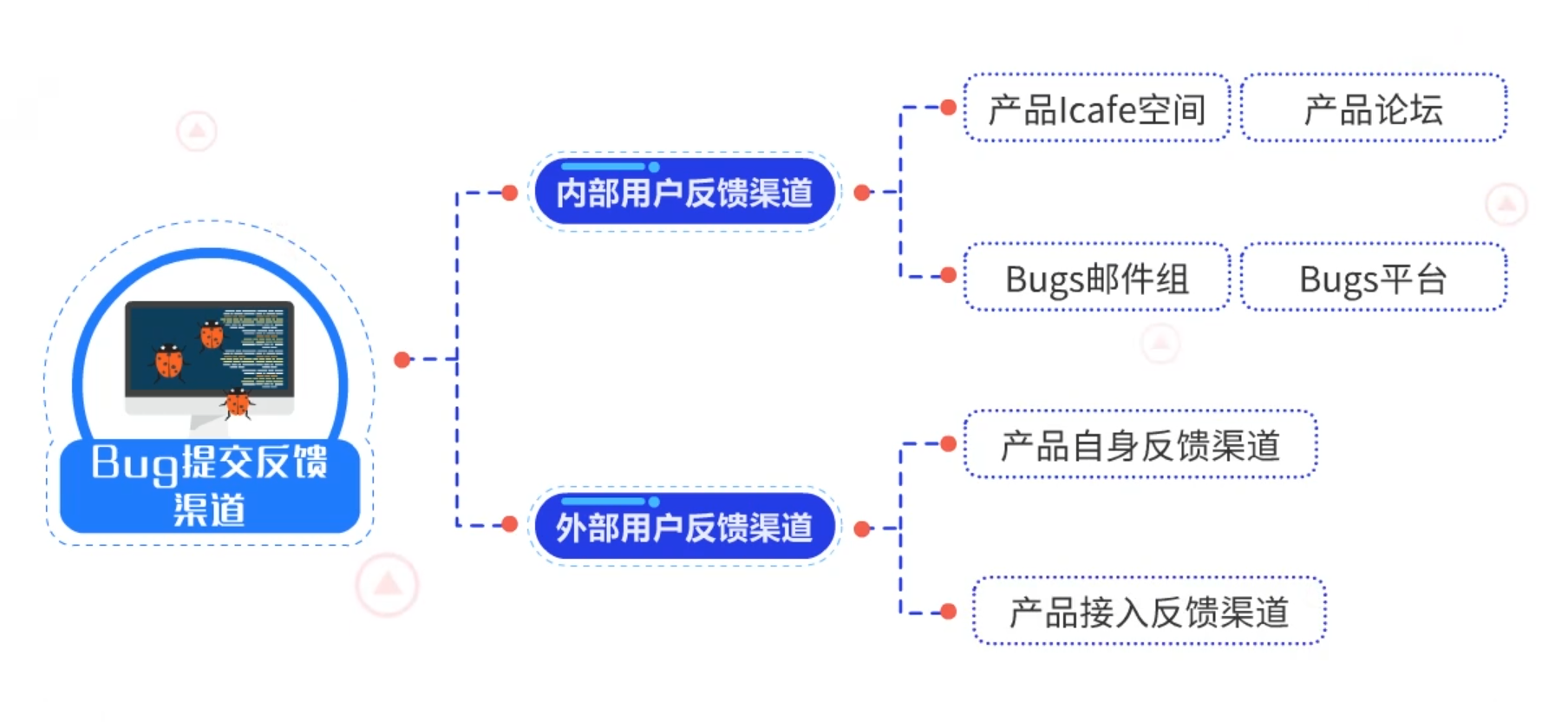
Bug提交需要反馈渠道,Bug的反馈渠道分为内部用户反馈渠道和外部用户反馈渠道两种。
- 内部用户反馈渠道包括:产品Icafe空间、产品论坛、Bugs邮件组、Bugs平台。
- 外部用户反馈渠道包括:产品自身反馈渠道和产品接入反馈平台。
Bug的提交有严格的格式要求,提交的Bug反馈应包括以下七个方面的内容:
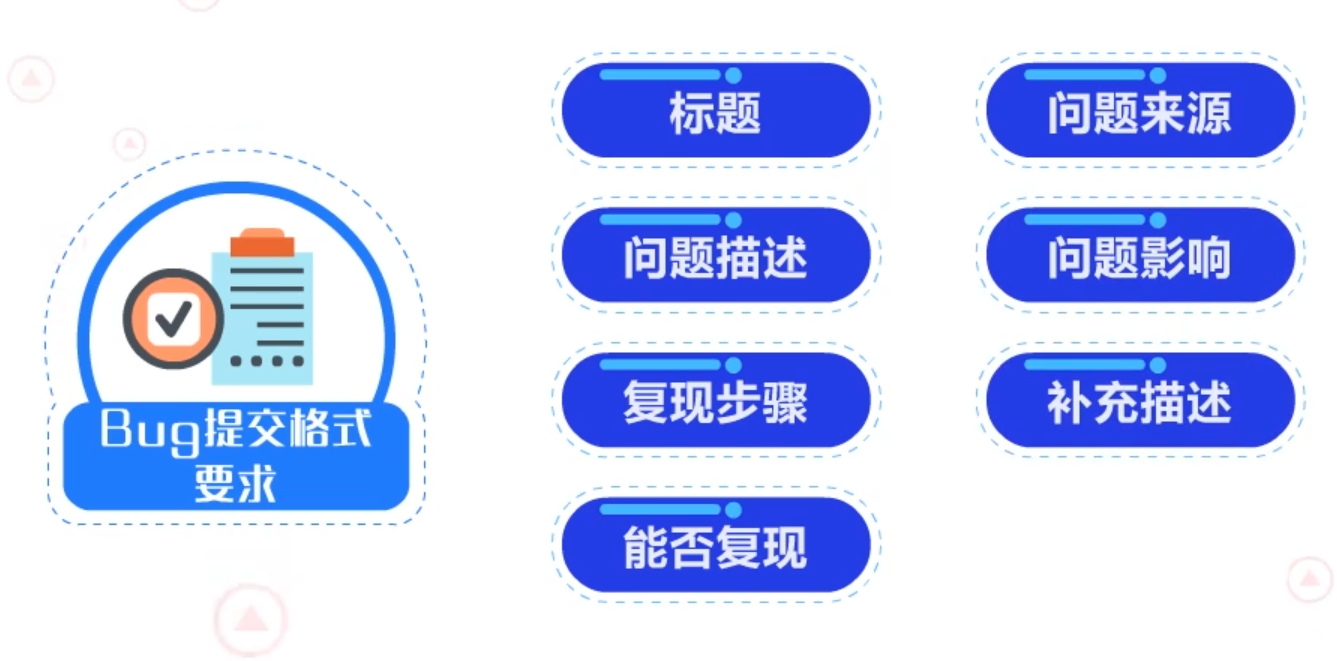
正确提交Bug能确保负责人能够清晰了解问题,直接进行数据挖掘,找到Bug所有的属性,便于后续维护工作的开展。
1.3 质量保证在项目各阶段的实现
质量的保证不能仅仅依靠测试人员,而是需要贯穿项目的各个阶段。
Bug的发现和修复是项目质量保证的一个重要方面,但质量保证工作绝不仅仅是修复Bug这么简单。
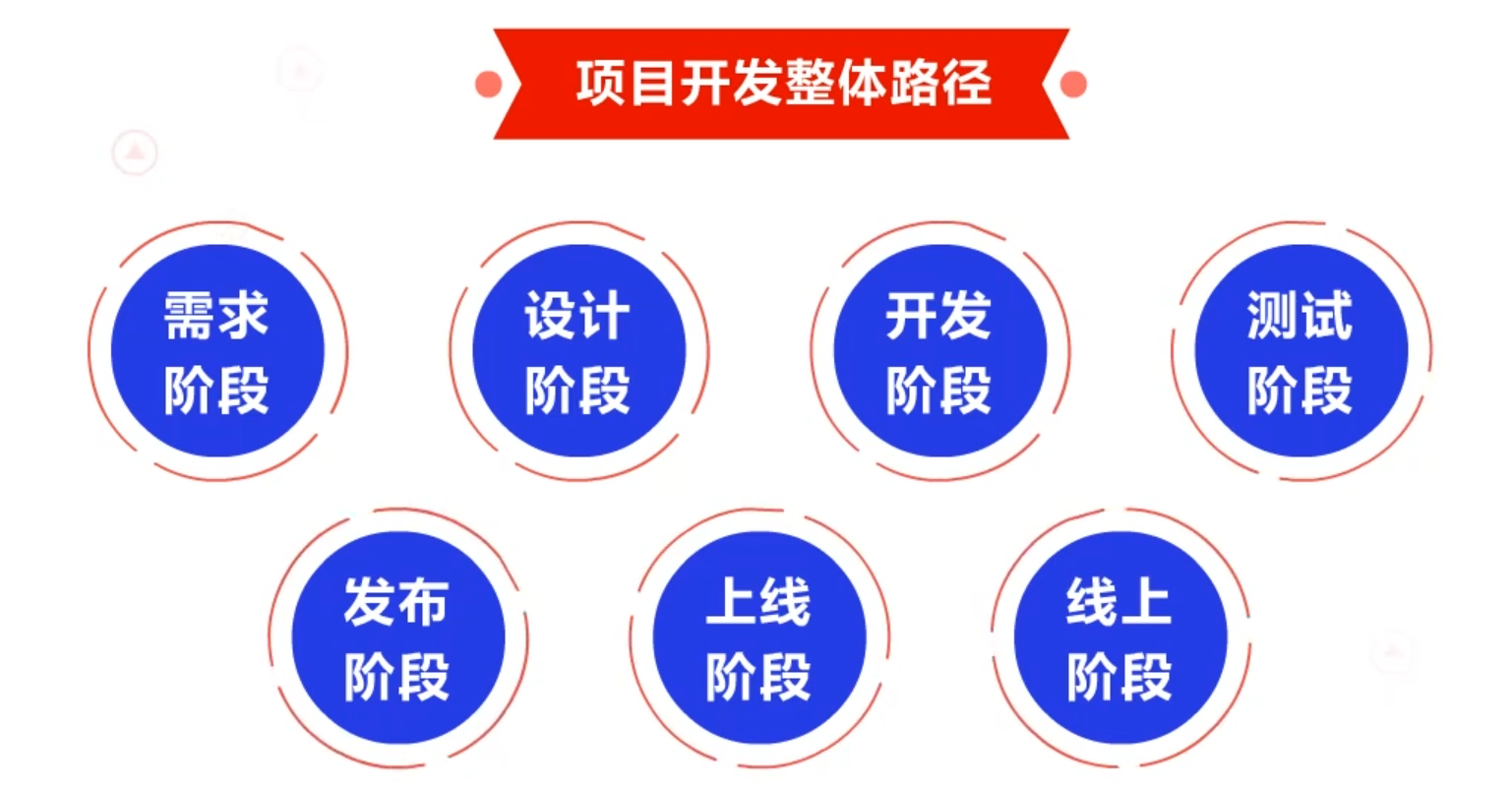
项目的开发整体路径包括:需求阶段、设计阶段、开发阶段、测试阶段、发布阶段、上线阶段以及线上阶段。
在一个项目开发的各个不同阶段,质量保证工作的要求和思路均有一定的不同,下面我们来展现质量保证工作在各个阶段的具体实现。
1.3.1 需求与设计阶段的质量保证工作
需求与设计阶段是项目开始的重要阶段,只有从客户真正的需求出发,才能设计出真正令客户满意的产品。
在一阶段,质量保证工作的关键点有三:
需求评审:站在用户的角度思考和挖掘需求,是设计和开发的前提性条件。
需求的变更管理:用户的需求始终在改变,建立一套完善机制去及时适应需求的变更十分重要。
- 设计评审:通过评审需求的可行性和设计的相关风险,可以极大降低设计风险,避免人力浪费。
1.3.2 开发与测试阶段的质量保证工作
在开发阶段,质量保证工作最重要的有两点:单元测试和代码评审。

单元测试的作用很多,主要有:
(1) 调试代码,确保代码实时可编译。
(2) 验证逻辑,减少代码中的Bug。
(3) 作为一个最细粒度回归测试,实时反馈代码的质量。
代码评审也同样十分重要,它的作用主要为:
(1) 保持代码风格的一致和可读性,利于贯彻编程规范。
(2) 提高代码质量,减少Bug。
(3) 促进互相交流学习,提升团队的整体研发能力,进而提高企业的整体竞争力。
而在测试阶段,我们的主要任务是测试功能性测试类问题。
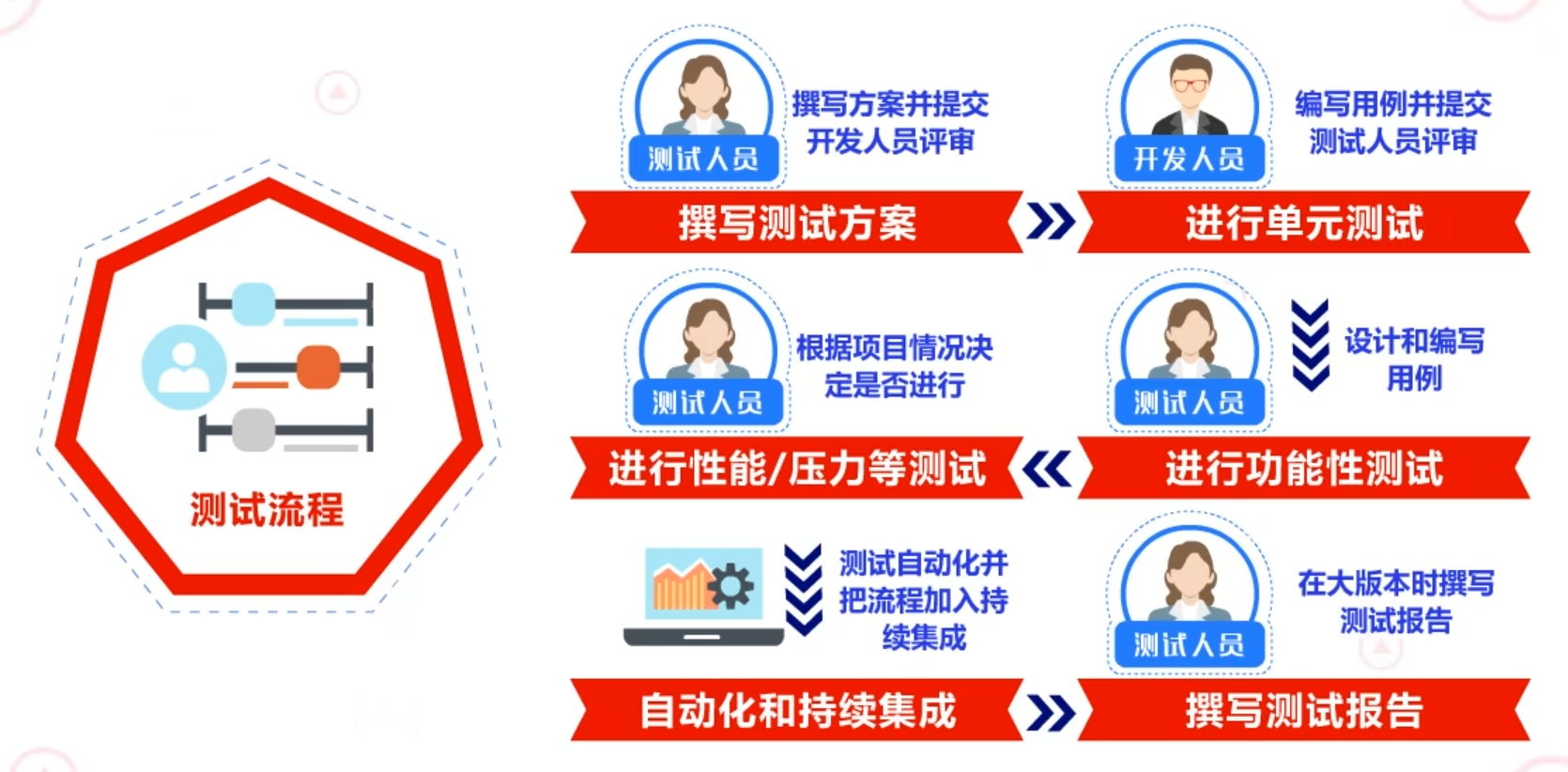
测试阶段一般流程为:
第一步:撰写测试方案。由测试人员编写方案并提交开发人员评审。
第二步:进行单元测试。由开发人员编写用例,并交给测试人员评审。
第三步:进行功能性测试。由测试人员设计和编写用例。
第四步:进行性能/压力等测试。测试人员根据项目情况决定是否进行。
第五步:自动化和持续集成。将测试自动化,并把流程加入持续集成。
第六步:撰写测试报告。测试人员要在大版本时编写测试报告。
测试环节涉及很多的内容,包括了:
(1)测试方案。
(2)自动化/持续集成。
(3)测试报告。
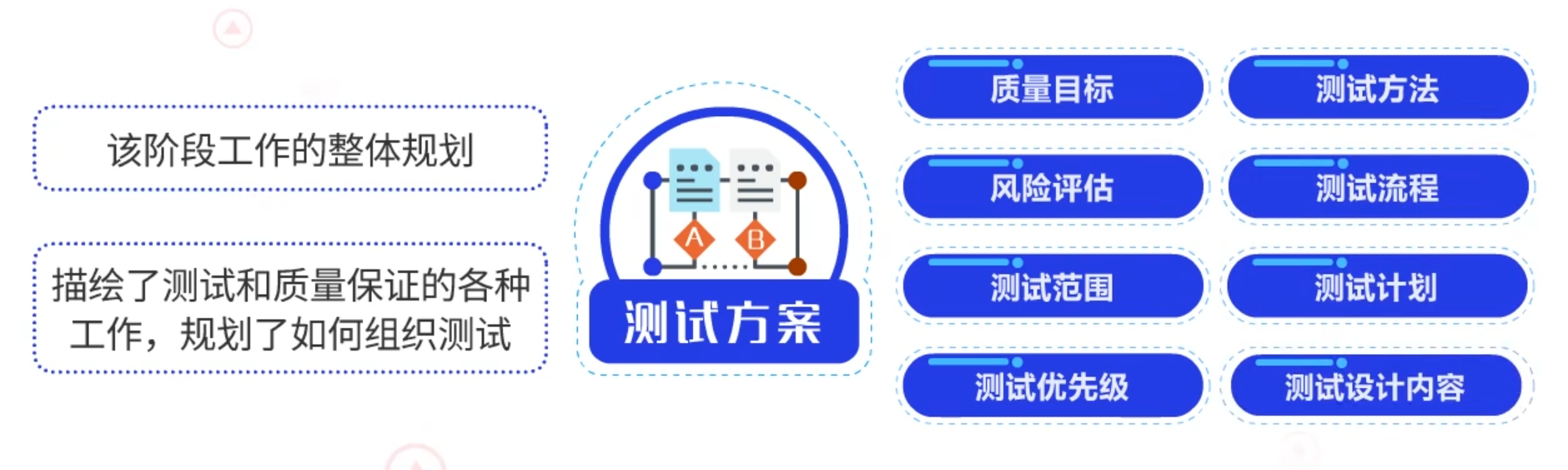
在这一环节中,撰写测试方案是对该阶段工作的整体规划。测试方案描绘了测试和质量保证的各种工作,规划了如何组织测试,方案中包括了:质量目标、风险评估、测试范围、测试优先级、测试方法、测试流程、测试计划和测试设计的内容。

常用的测试方法有:黑盒/白盒、静态测试/动态测试、自动化测试/手工测试、验收测试/α测试/β测试、单元测试/模块测试/集成测试/联调测试/系统测试、功能性测试/性能测试/压力测试/异常测试/安全测试、接口测试/用户场景测试、回归测试、探索性测试等。

不同的测试方法有不同的特点和擅长解决的问题。测试的侧重点不同,发现的问题也不同。我们需要根据测试方案,来选择合适的测试方法,提高测试的效率。为此,在前期的测试和设计方案评审时要及早发现问题,避免无效劳动,提高测试效率。
同样,自动化和持续集成也是有效提高测试效率的方法。
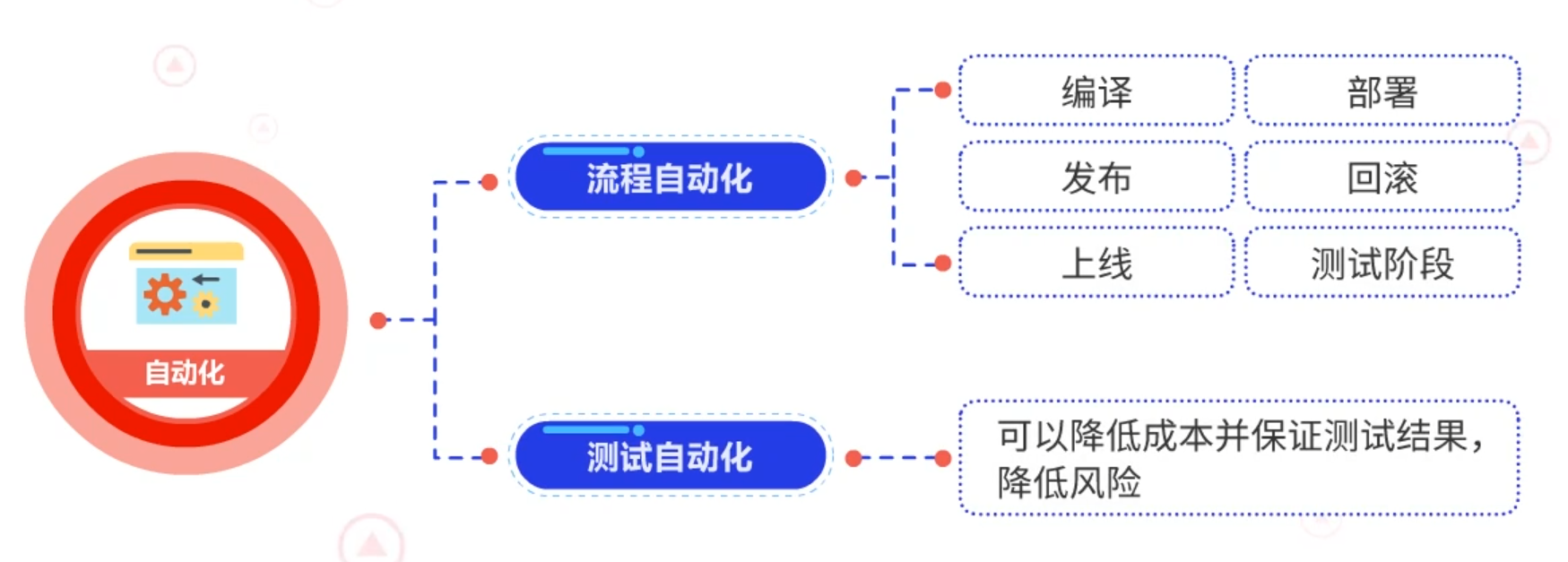
自动化包括流程自动化和测试自动化。流程自动化包括编译、部署、发布、回滚、上线和测试阶段。测试自动化可以降低成本并保证测试结果,降低风险。
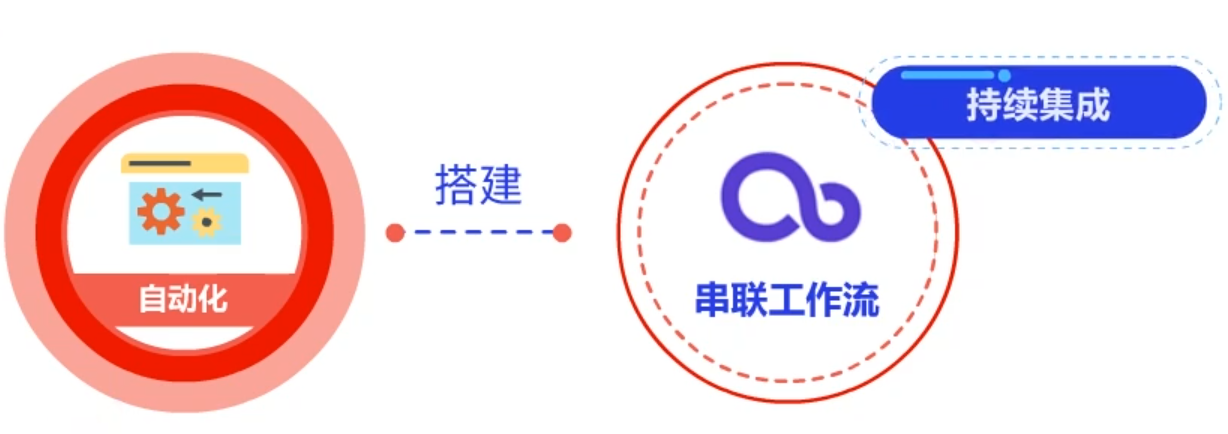

而基于自动化,我们可以搭建串联工作流,即持续集成,可以将代码提交、编译、模块测试、部署、系统测试、发布这一循环性流程集成在一起,从而提高工作效率,保证持续的质量反馈。
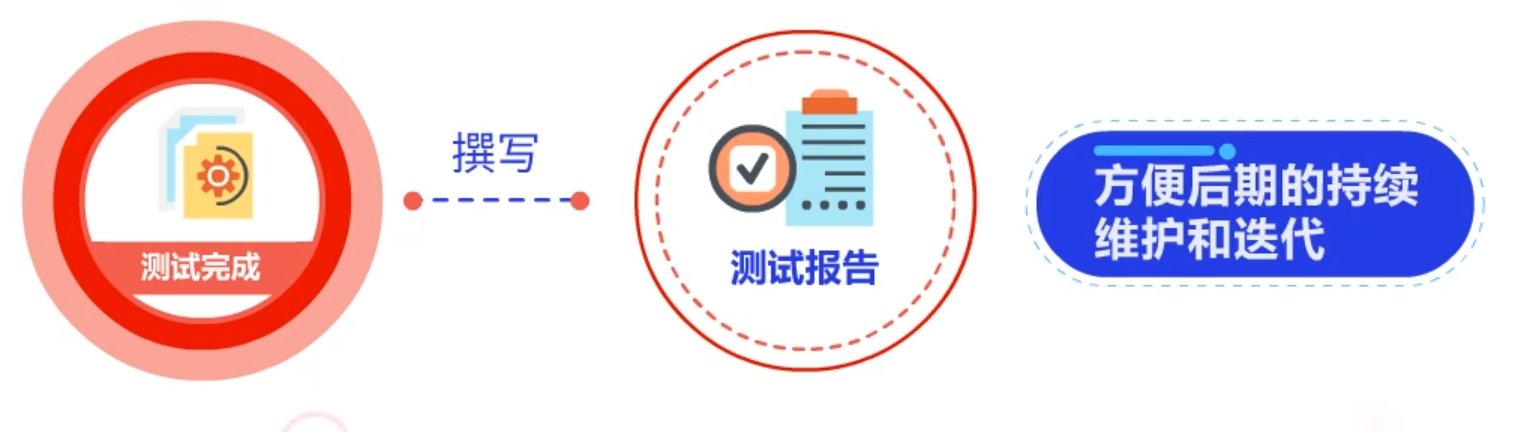
测试完成后需要撰写详细的测试报告,以方便后期的持续维护和迭代,其内容包括:
测试结果、质量风险评估、质量评估、测试过程描述、缺陷分析、评估改进意见、测试版本/测试人员/测试时间。
1.3.3 上线与线上阶段的质量保证工作

上线阶段包括上线过程和回滚过程。
上线阶段的上线方案需要经过评审和测试,对于重点项目,还应有回滚方案和相应的评审和测试工作。
上线后,我们需要进行线上测试,常用的线上测试有三类:众包测试、用户反馈和业务监控、产品评测。
(1)众包测试:
众包测试的目的是使更多的用户参与测试,降低测试成本。众测服务分为四类:测试类(包括探索性测试、用例组合爆炸测试),产品体验(包括产品建议、Badcase收集)、评估评测(包括大数据量评估标注、降低成本)、用户调研(产品需求调研、用户反馈)。一个众测平台:http://test.baidu.com
(2)用户反馈和业务监控:
目的则是为了实现线上问题闭环,通过用户反馈和业务监控可以解决大部分的线上问题。步骤分为收集、分发、定位和解决。主要平台有反馈平台、Bugs平台和 Monitor平台。
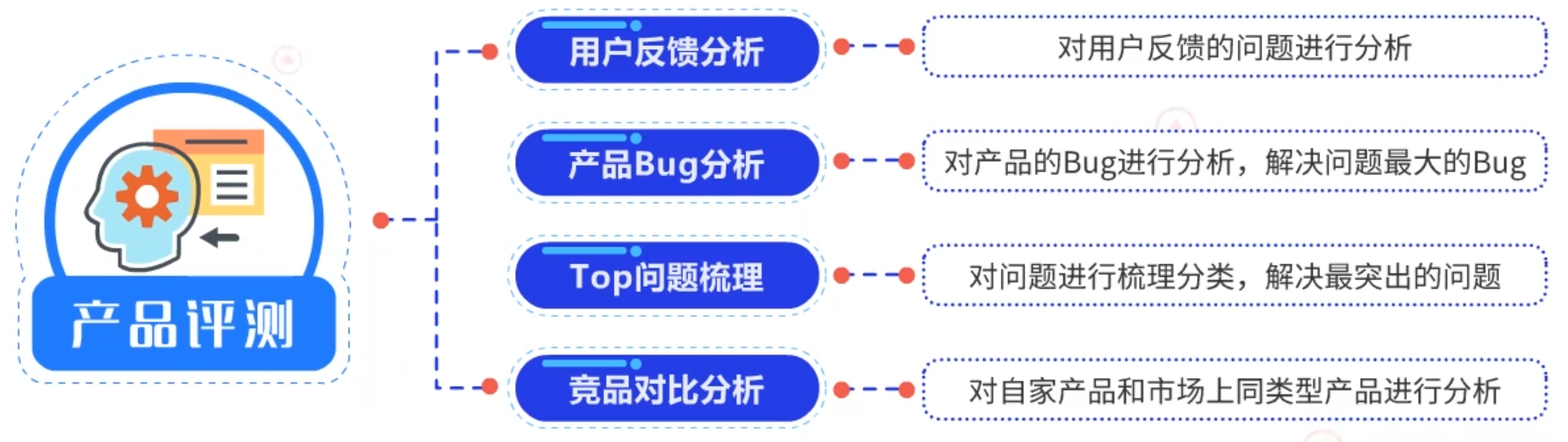
(3)产品评测:
包括用户反馈分析、产品Bug分析、Top问题梳理和竞品对比分析。
→ 用户反馈分析是指对用户反馈的问题进行分析。→ 产品Bug分析是指对产品的Bug进行分析,然后解决问题最大的Bug。
→ Top问题梳理是指,对问题进行梳理分类,解决最突出的问题。
→ 竞品对比分析是指对自家产品和市场上同类型产品进行分析。

从对各个阶段质量保证工作的分析中,我们不难看出,每一个阶段的质量保证工作都需要多方角色的共同参与。可见,项目的出色质量来源于每个环节的严格把控和每个成员的共同参与,这是团队质量意识的两大核心。
1.4 质量保证意识的4个核心内容
1.4.1 质量保证工作存在于每一个环节
1.4.2 每一个成员都需要对质量负责

1.4.3 测试是一种核心的质量保证工作

1.4.4 尽早发现问题,尽早解决问题

2 代码单元测试总体介绍
2.1 单元测试基础
2.1.1 单元测试的误区
单元测试存在一些认识上的误区,包括:
- 开发单元测试代码的工作量大。
- 做单元测试不属于开发人员的职责。
- 代码正确率高,进行单元测试必要性不大。
- 后期有集成测试,前期进行单元测试必要性不大。
- 单元测试无法带来显著收益,效率不高。
2.1.2 单元测试的概念
在维基百科中,单元测试的定义为:一段代码调用另一段代码,随后检验一些假设的正确性。
在百度百科中,单元测试是指对软件中的最小可测试单元进行检查和验证。
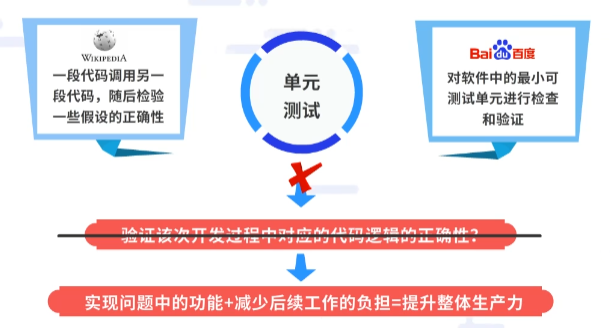
那么我们不禁要问:一次编写的单元测试是否只是为了验证该次开发过程中对应的代码逻辑的正确性?
其实不然,单元测试不仅在于实现问题中的功能,优秀的单元测试作用长久,可以减少后续工作的负担,从而提升整体生产力。
2.1.3 常见的单元测试问题
目前单元测试中存在一些常见的问题:
- 使用System.out输出测试结果,依赖人去判断测试是否正确。
- 不使用Assert(断言)对测试结果进行判断。
在以上两种情形都需要依赖人与电脑的交互来判断此case是否成功,人的工作量较大;**在实际的单元测试中,应当使用断言进行判断,使 case运行时自动输出结果。
- 没有边界检查。
- 多个测试分支放入一个单元测试方法中。
这种情况会导致一旦出现运行失败时,难以判断出现错误的分支所在。
- 测试case环境相关(依赖已知库表、时间)。
对于这种情况,应当做出修改,使输入参数为确定的值。
- 测试方法执行有先后顺序。
在实际测试过程中,由于不同的用于运行单元测试的测试框架对于case执行顺序有自己的行为,故单元测试实际执行顺序存在不确定性。
2.1.4 优秀的单元测试
优秀的单元测试需要以下原则:
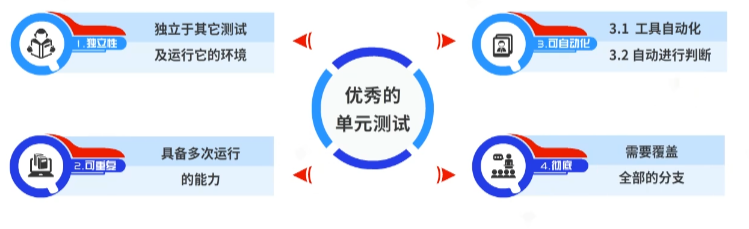
- 单元测试彼此之间应具备独立性。一个单元测试应独立于其它测试及运行它的环境。
- 一个优秀的单元测试是可重复的。它需要具备多次运行的能力,若不可重复,则不能算作优秀的单元测试。
- 优秀的单元测试可自动化。自动化具备双重含义:第一,单元测试可依赖于现有工具自动化运行;第二,单元测试执行成功与否可自动进行判断,而不依赖于人为判断。
- 优秀的单元测试是彻底的。单元测试对于被测试对象而言需要覆盖全部的分支。
2.2 单元测试的意义与建议
2.2.1 什么情况下做单元测试
(1)单元测试的好处
①带来更高的测试覆盖率:有些分支问题在集成测试过程中很难发现,但在单元测试中极易发现。
②提高团队效率:单元测试在开发完后立即执行,将测试提前一步,不必等集成测试时才发现问题。
③自信的重构和改进实现。
④将预期的行为文档化:完整的单元测试是产品代码的最好文档。
(2)不当的单元测试会降低生产力
单元测试并不是越多越好,不当的单元测试会降低生产力。
①单元测试的工作量与普通代码的工作量的比例介于1:1~1.5:1。
②整体项目的单元测试运行时间随着单元测试case增多线性增长,测试的执行速度影响每次变更等待的时间。
③单元测试的代码,也需要长期维护。
(3)如何选择单元测试的对象
不写单元测试不好,单元测试写多了也不好,这就要求我们要细心选择单元测试的对象。
在进行单元测试的时候,应重点关注核心业务逻辑代码、重用性高的代码与调用频繁的代码,后两者较为相近。
2.2.2 不同场景下的单元测试tips
1)Java Web项目底层的BO\DAO大体都是工具自动生成,无需额外单测,但是Action(Controller)层不含有较多的业务逻辑,需要通过集成测试发现问题。要注意的是java web项目的核心业务逻辑主要存在于Service层代码中,需要着重进行单元测试。
(2)平台类Java项目虽然在单独的场景下几乎不会出现问题,但是交叉混合时可能存在问题。而且由于平台类项目更多的兼顾不同的复杂的应用场景,所以在测试时要尽量做到全面。值得注意的是平台类Java项目的分支较多,所以要求在单元测试时要做到覆盖分支全面。
(3)组件类Java项目和平台类项目类似,也需要侧重分支覆盖全面,包括异常调用情况的覆盖。
(4)Hadoop的MR任务属于特殊的JAVA程序,集成测试成本高,主要体现在时间成本上。在进行单测时,可以将核心逻辑代码抽取出来,单独测试。
3 Python单元测试
3.1 单元测试的概念、工具与方法
3.1.1 单元测试的概念
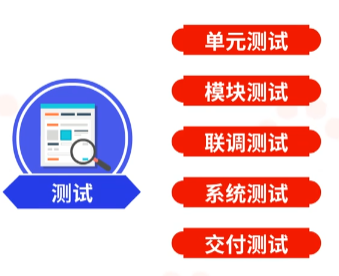
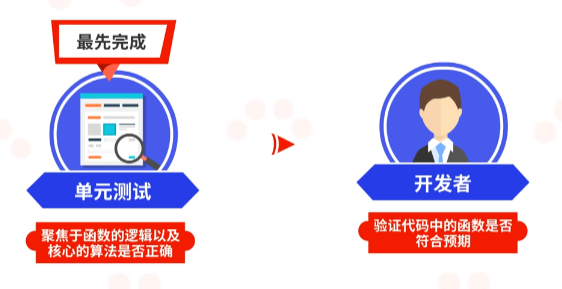
测试具有许多种不同的类型,比如说单元测试、模块测试、联调测试、系统测试、交付测试等。在这些测试之中,单元测试是最先要完成的。单元测试通常是由开发者去完成,用来验证代码中的函数是否符合预期。因此,它聚焦于函数的逻辑以及核心的算法是否正确。通常而言,一个单元测试用例是用于判断在某个特定条件或场景下,某个特定函数的行为。
3.1.2 单元测试的意义
单元测试的意义包括两个方面。
(1)质量
①单元测试主要针对函数,颗粒度小、测试针对性强,bug更容易暴露;
②由于单元测试覆盖面较窄,无需考虑其它函数或者所依赖的模块,所以它的场景易构造,核心功能验证更充分;
③进行单元测试保证整体代码结构良好,使代码就具有较高的可测性和可维护性。
(2)效率
单元测试能够提高开发效率,主要表现在:
①单元测试进行的时间较早,测试场景构建快,可有效减少调试时间。
②由于单元测试只针对修改的代码展开测试,无需考虑额外内容,所以在较短时间内即可把预期的逻辑测试充分。
③单元测试能够在项目开发初期发现的bug,bug发现的时间越早,所带来的收益越大。由于尽早发现bug能够节省整个项目开发的时间,所以单元测试可加快开发效率,缩短开发周期。
3.1.3 单元测试框架
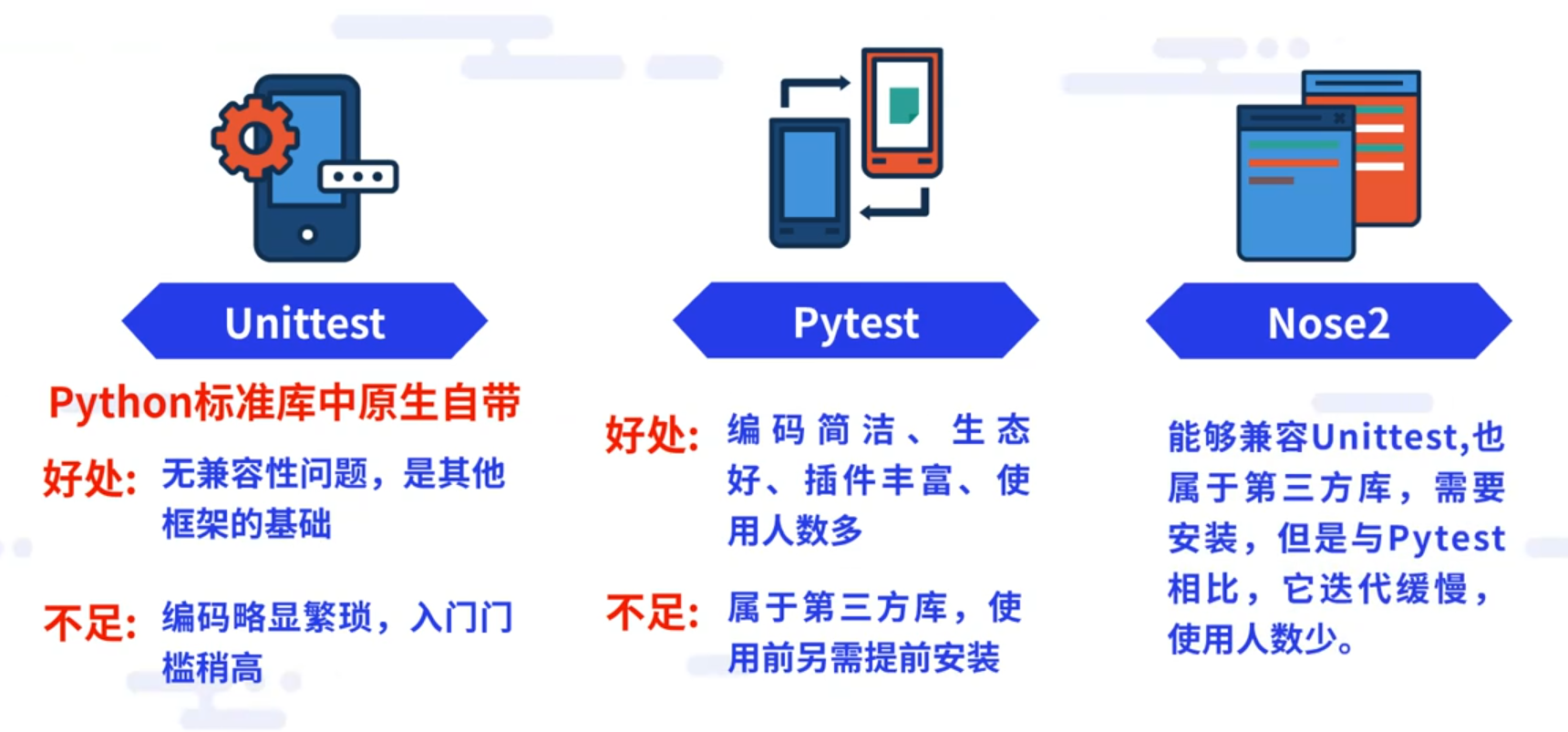
Unitest的基础概念
在做单元测试之前,需要先了解一下Unittest的几个基础概念。
①Test(测试用例),针对一个特定场景,特定目的具体测试过程。
比如说一个函数通过一组输入测试它,就是一个测试用例;如果一个函数通过三组输入来测试,即为三个测试用例。
②TestCase(测试类),可以包含同一个测试对象的多个测试用例。
如果一个函数通过三组输入来测试,也就是三个测试用例,这三个测试用例可以合成为一个测试类。
③TestSuite(测试集),可以包含多个测试类的多个测试用例。
④Assertion(断言),必须使用断言判断测试结果。
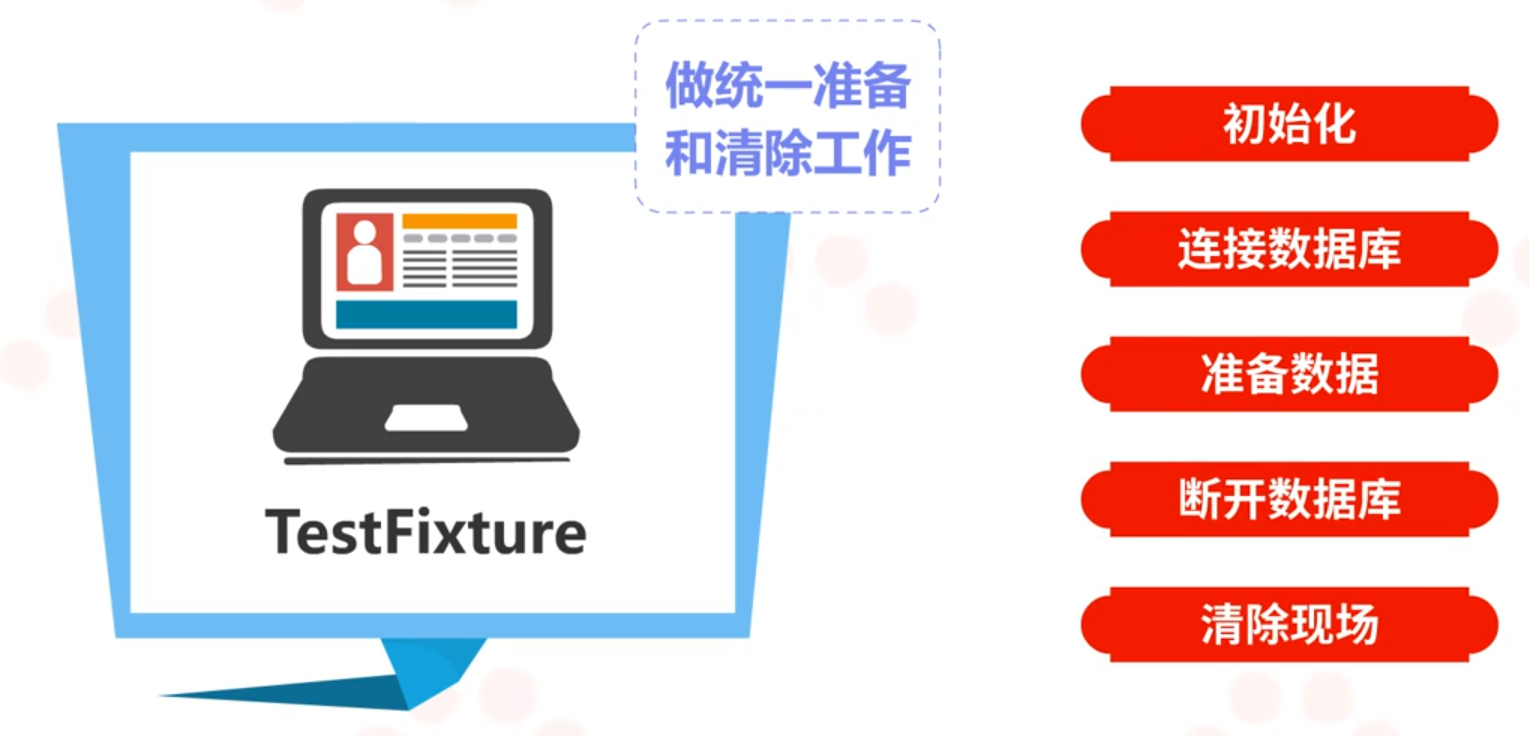
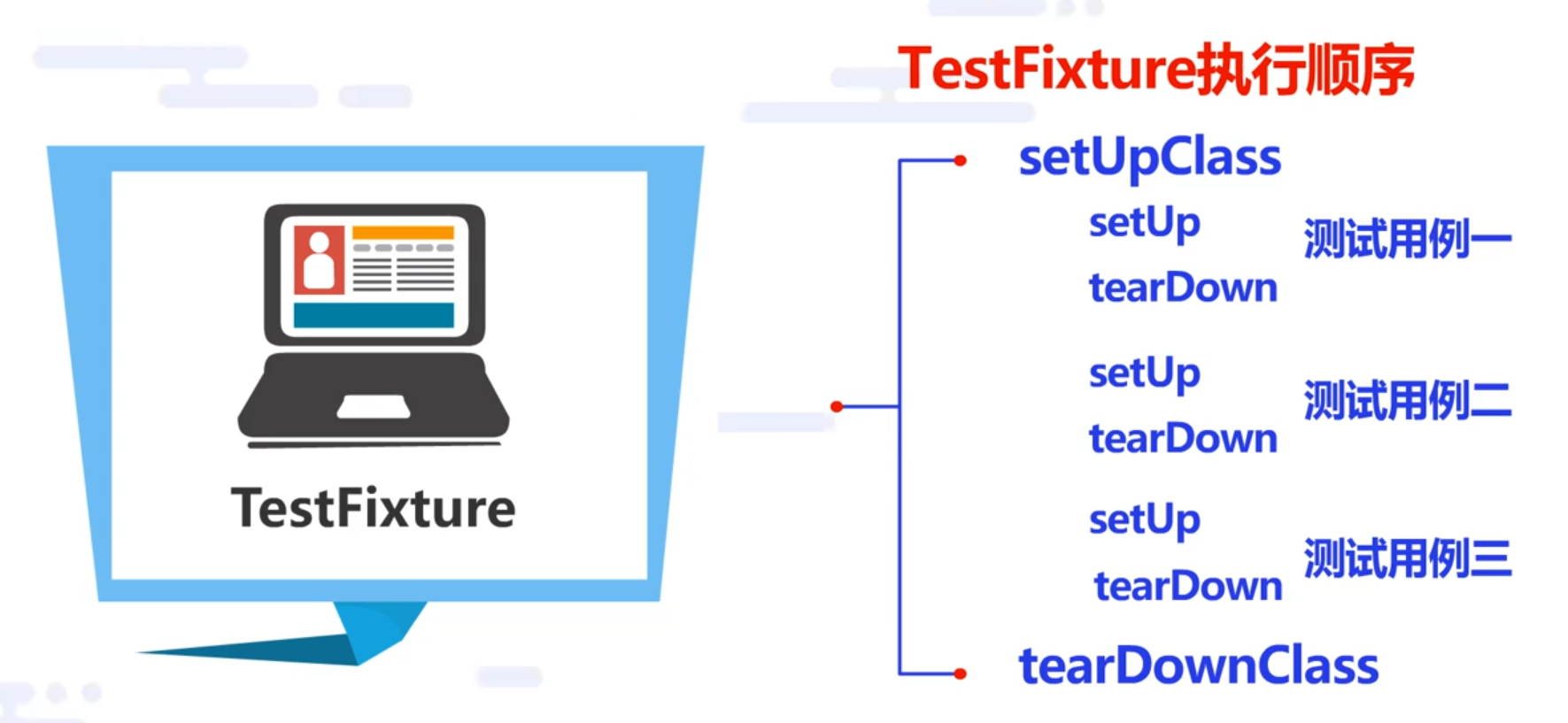
⑤TestFixture,为测试做统一的准备和清除工作,通常是初始化,连接数据库,准备数据,断开数据库,清除现场等。
扩展来说,TestFixture有四种最常使用的作用范围,分别为:
- setUp:在测试类的每个测试用例执行前执行。
- teardown:在测试类的每个测试用例执行后执行。
- setUpClass:在测试类的第一个测试用例执行前执行。
- tearDownClass:在测试类的最后一个测试用例执行后执行。
TestFixture可以让单元测试代码更简单,但并非必须使用,也不要求配对出现。
3.1.4 单元测试的规范
如下是单元测试涉及的规范。
(1)所有的单元测试必须使用断言(assert)判断结果,禁止出现无断言的测试用例;

使用断言,不但有利于他人理解,而且一旦出现不符合预期的情况,可以立即找出问题。
可以使用assertEqual, assertNotEqual 来判断相等或不相等,assertTrue,assertFalse 来判断Boolean, assertRaises 判断抛出的异常是否符合预期。
(2)测试用例需要具有自表述能力,达到见名知意。
比如命名testlogin_with_invalid_password(),通过它的名字便可知它是用一个非法的密码去测试登录功能,具有自表述能力;但是如果命名为 test_login_case(),名字减少了很多信息,难以得知它具体在做什么,不具有自表述能力。

(3)测试用例之间相互独立,不应相互依赖、相互调用。
(4)一个测试用例只测一个函数。一个测试用例里面可以包含这一个函数的多个场景,但不能包含有多个参数的函数。原因在于,复杂测试用例出现错误时,无法定位问题的出处。
3.1.5 单元测试对编码的要求
单元测试中代码需保持一致性,尽量不要出现结果不一致的情况。假设有的代码会带来不一致性,导致单元测试无法稳定运行。针对这种情况,有两种解决方案:
第一,将带来不一致性的代码抽取出来,把它作为一种变量传入我们需要调用或使用一致性变量的时候;
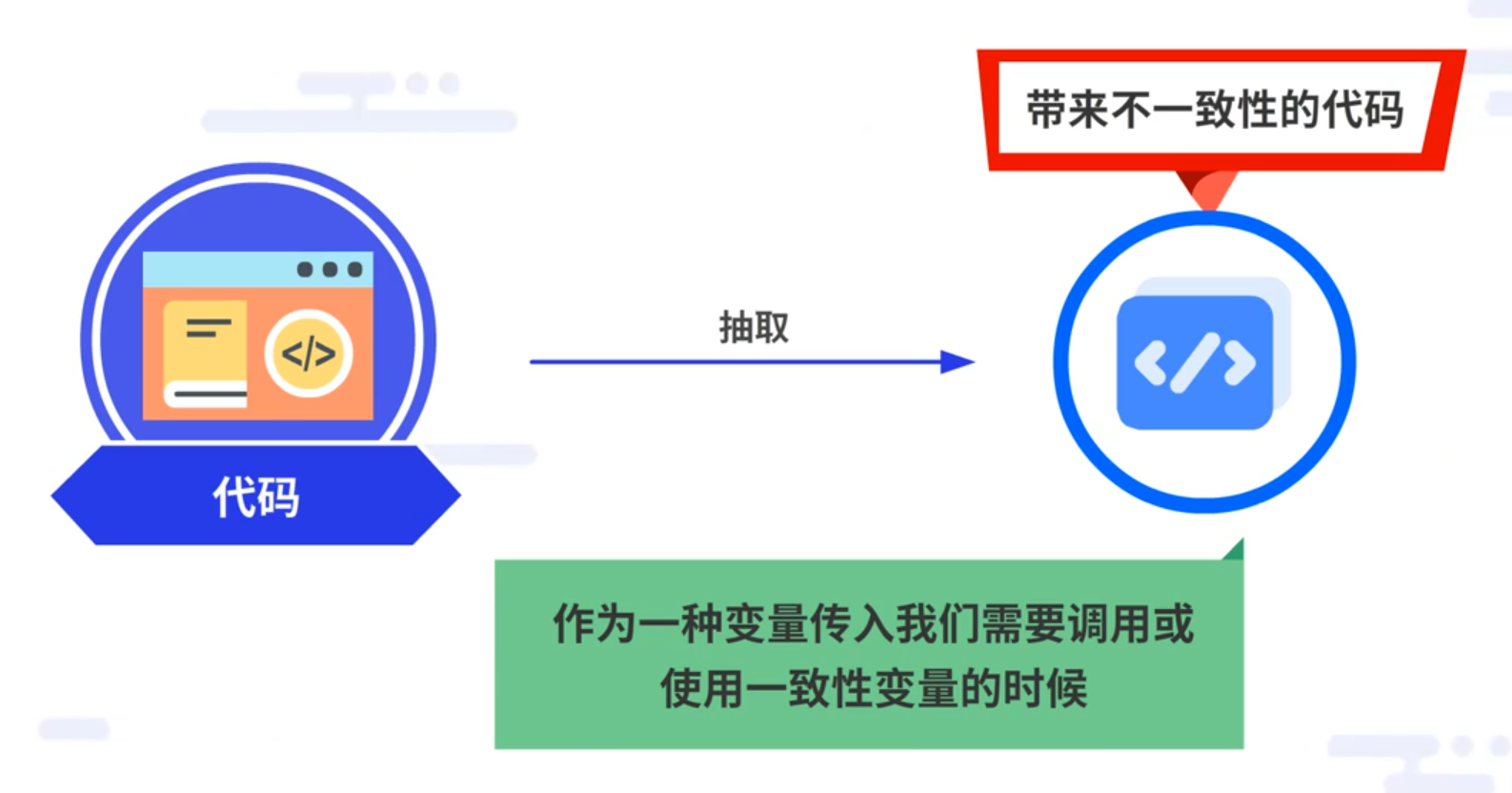
第二,借助第三部分即将讲到的一个工具——mock——来解决这种问题。
3.2 Coverage 统计单元测试覆盖率的工具
单元测试做完之后如何评价我们单元测试的效果。此时需要用到覆盖率工具,即Coverage。Coverage是一个第三方的工具,需要提前下载安装。
3.2.1 统计覆盖率方法
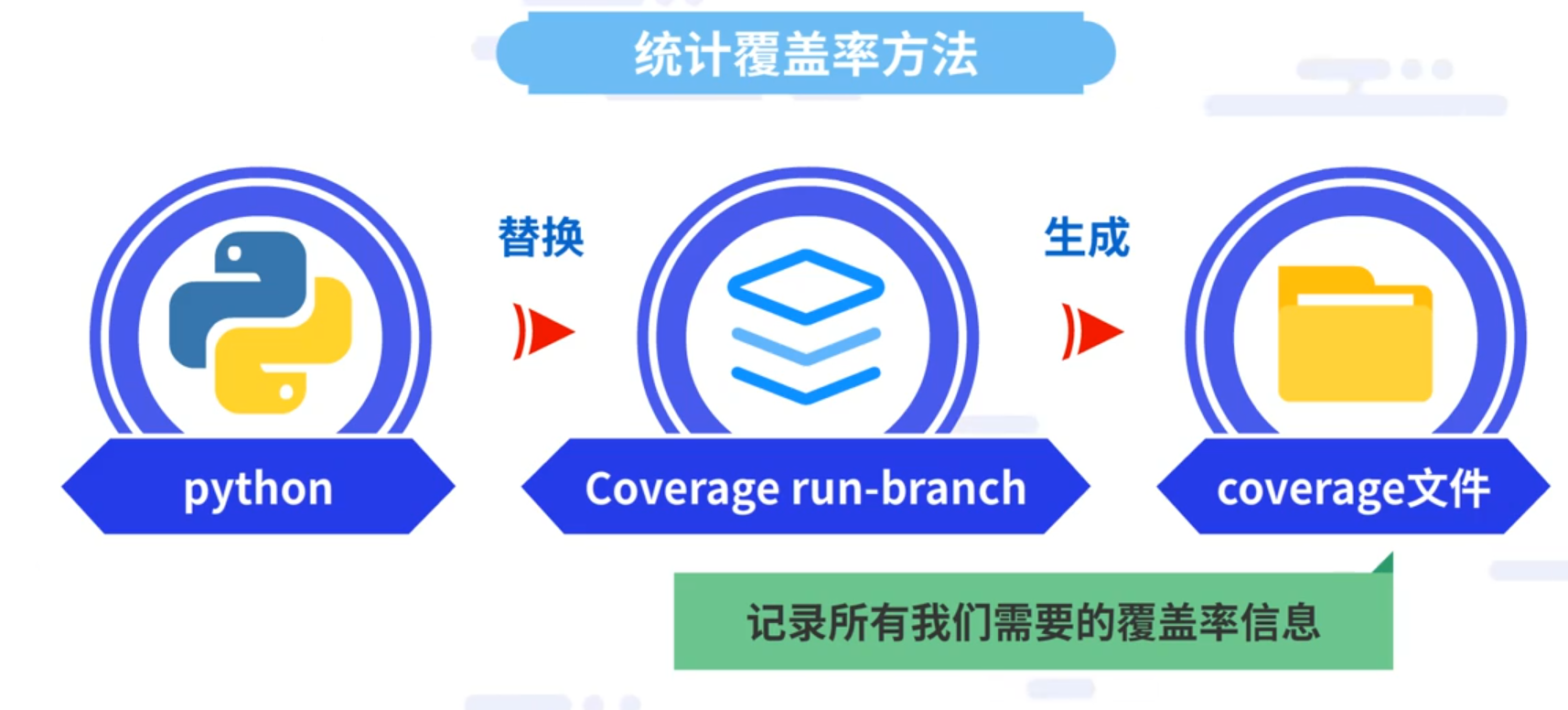
把python替换为coverage run-branch,然后会生成coverage文件,文件里会记录所有我们需要的覆盖率信息。
3.2.2 打印覆盖率信息
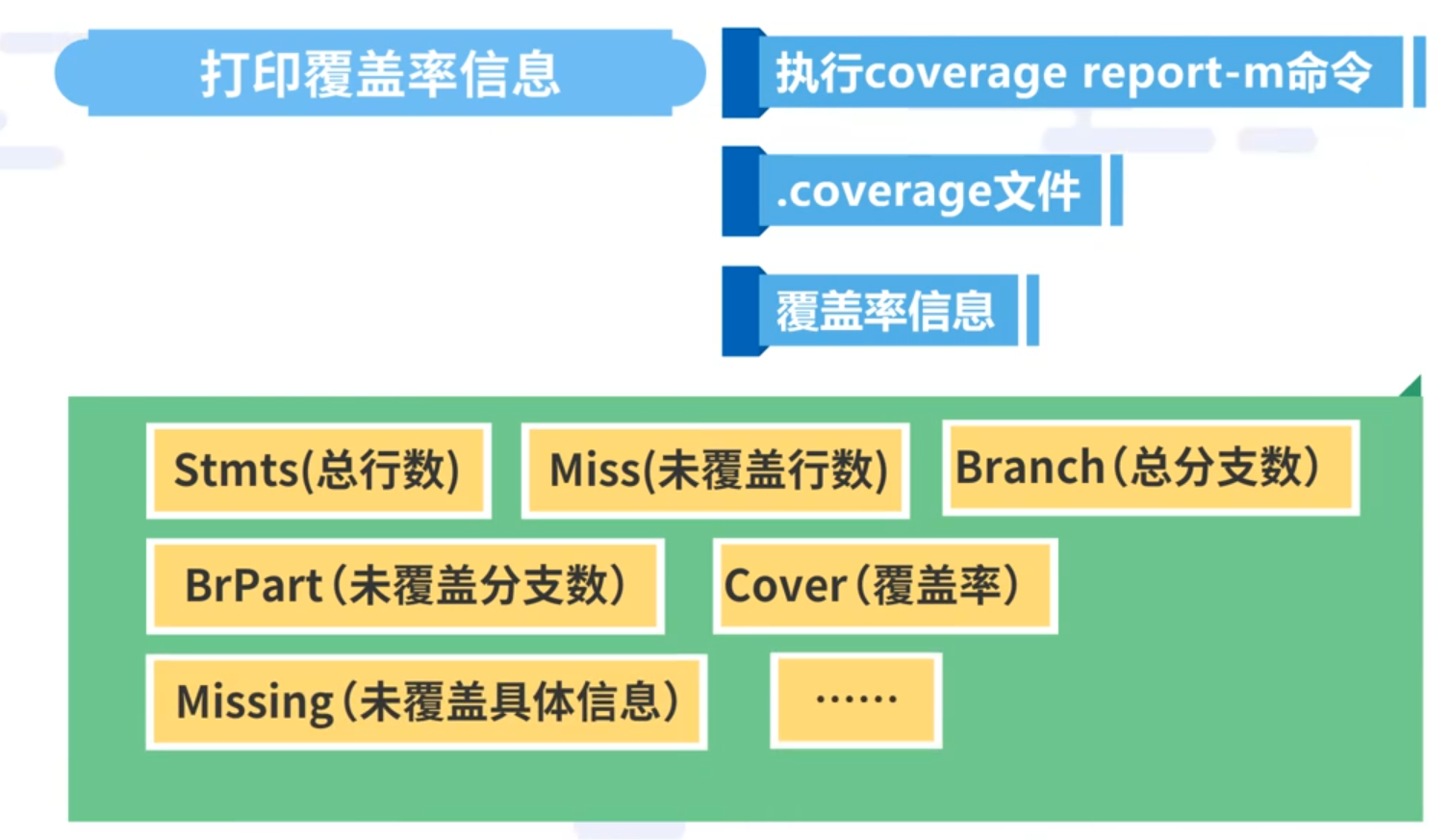

执行coverage report-m 命令,读取当前目录下.coverage文件,打印覆盖率信息。输出Stmts(总行数), Miss(未覆盖行数), Branch(总分支数), BrPart (未覆盖分支数), Cover(覆盖率) , Missing(未覆盖具体信息)等信息。
3.2.3 覆盖率中排除某些文件

执行coverage report-m—omit=file 1[,file 2,……] 命令, 在统计并打印覆盖率时,排除某些文件。若有多个文件用逗号分隔。
3.2.4 生成HTML格式的覆盖率信息

针对代码量较大,查找覆盖率信息难度较大、耗时较长的情况,执行coverage html [—omit=file1[,file2,……]]命令,将覆盖率信息以html格式显示。
3.3 Mock 简化单元测试的工具
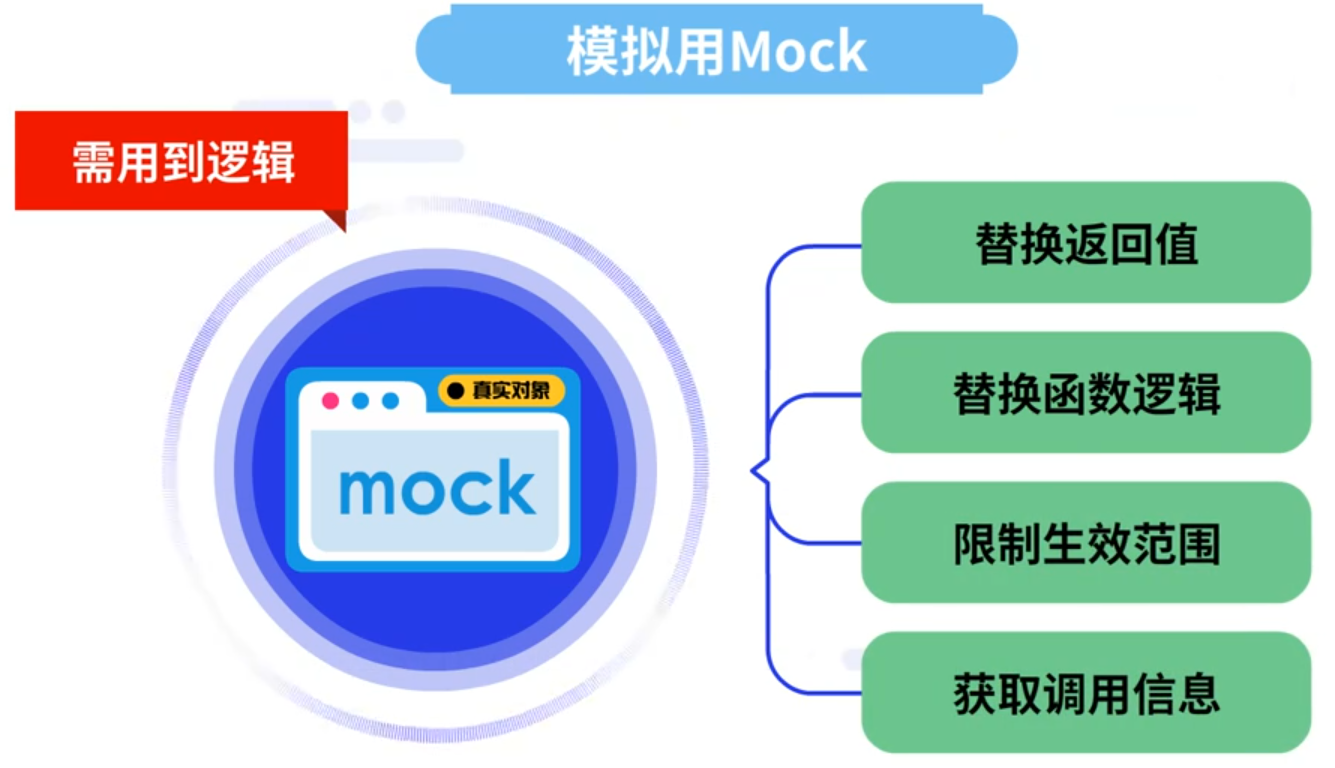
3.3.1 使用mock工具的原因与其功能
Mock基于实际进行单元测试的场景而产生,以下三类场景非常具有代表性:
构造模块。
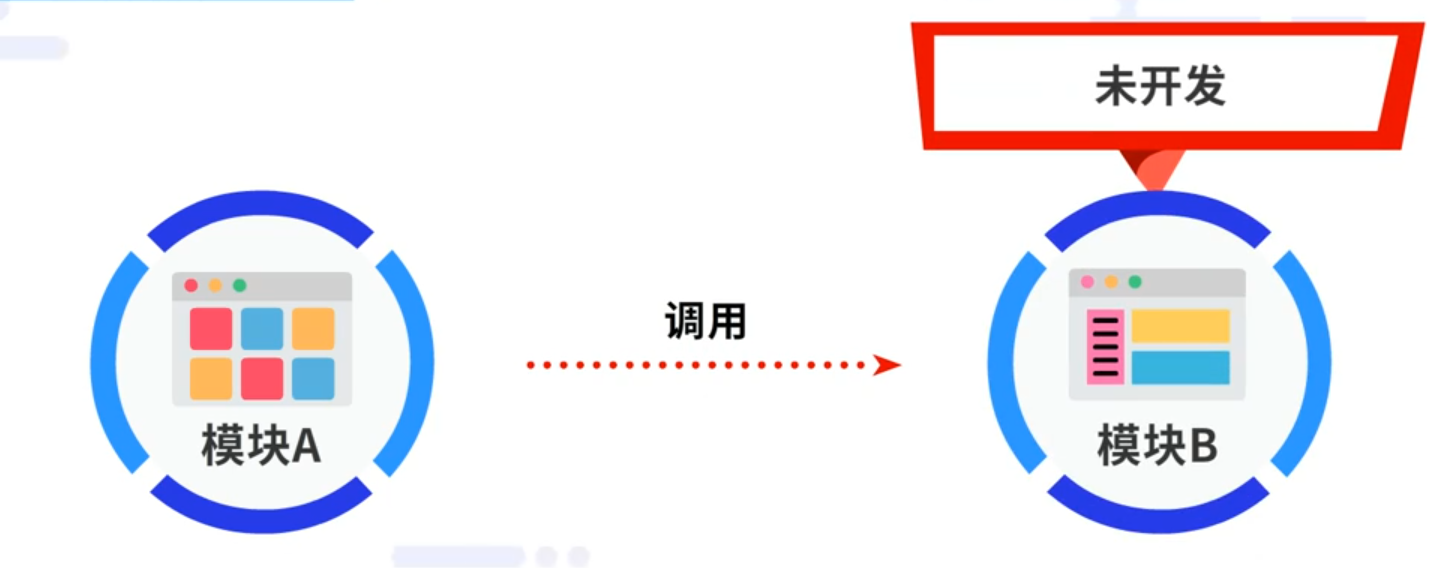 需要测试模块A,但它要调用的模块B还未开发,可是测试却不容推迟、需按时进行,面对这种情况,我们可以使用Mock生成一个还未写完的代码,即可进行相应的测试。
需要测试模块A,但它要调用的模块B还未开发,可是测试却不容推迟、需按时进行,面对这种情况,我们可以使用Mock生成一个还未写完的代码,即可进行相应的测试。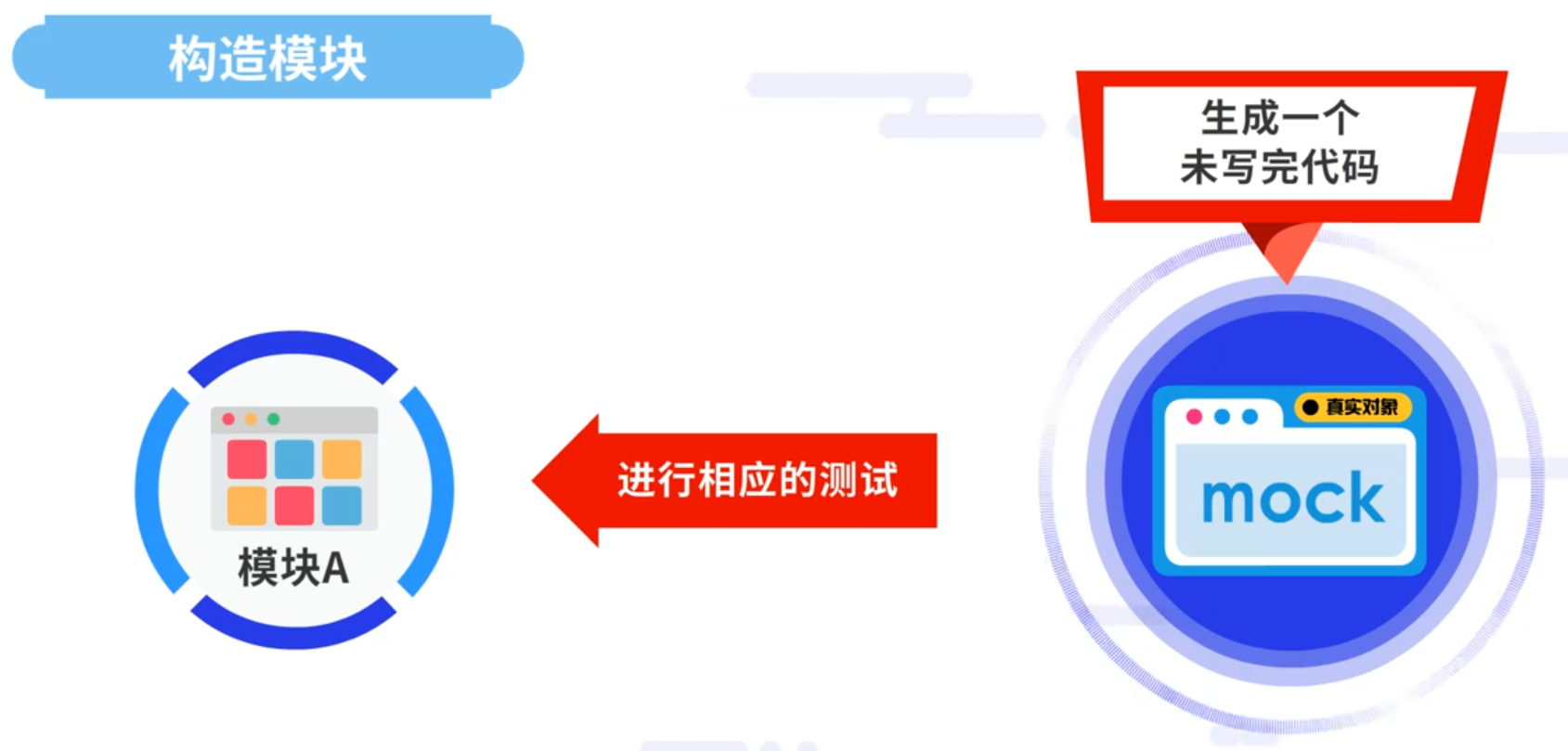
改变函数逻辑。
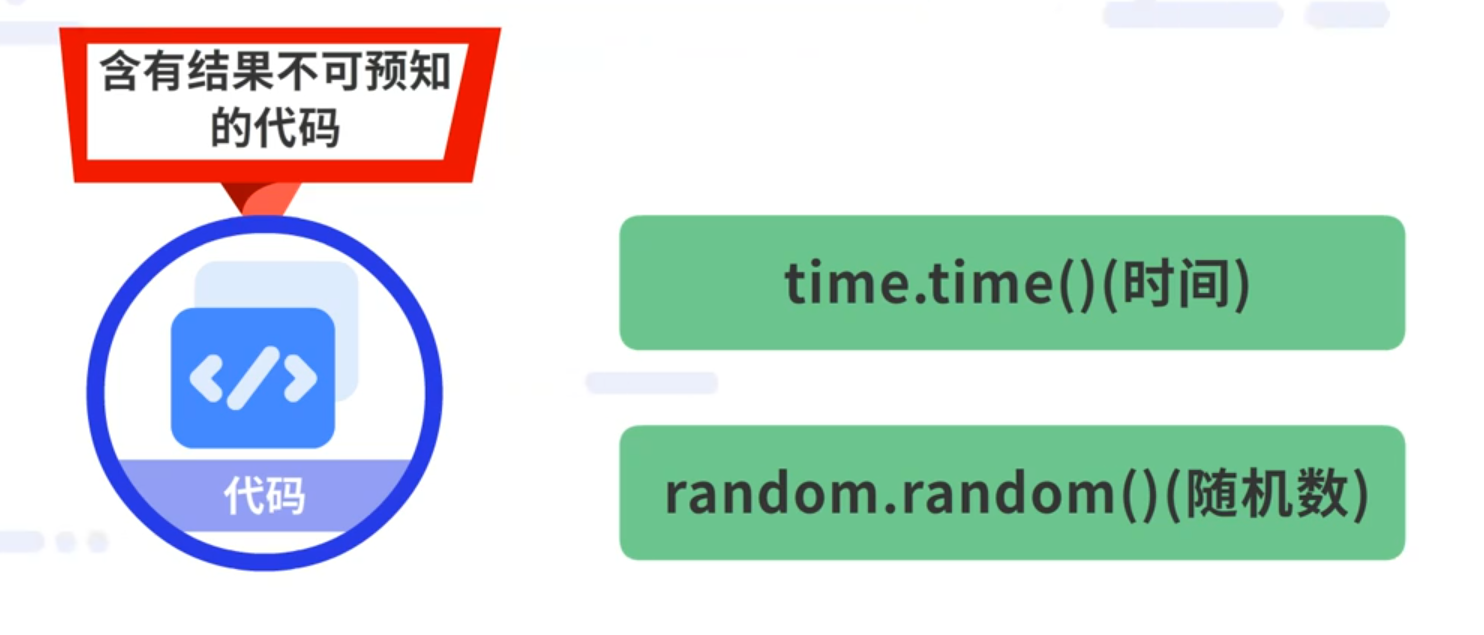 代码中含有结果不可预知的代码,例如time.time()(时间), random.random()(随机数)。Mock可以改变含有结果不可预知代码的函数的逻辑,强行让其返回我们想要的返回值,使其结果可预知。
代码中含有结果不可预知的代码,例如time.time()(时间), random.random()(随机数)。Mock可以改变含有结果不可预知代码的函数的逻辑,强行让其返回我们想要的返回值,使其结果可预知。减少依赖。
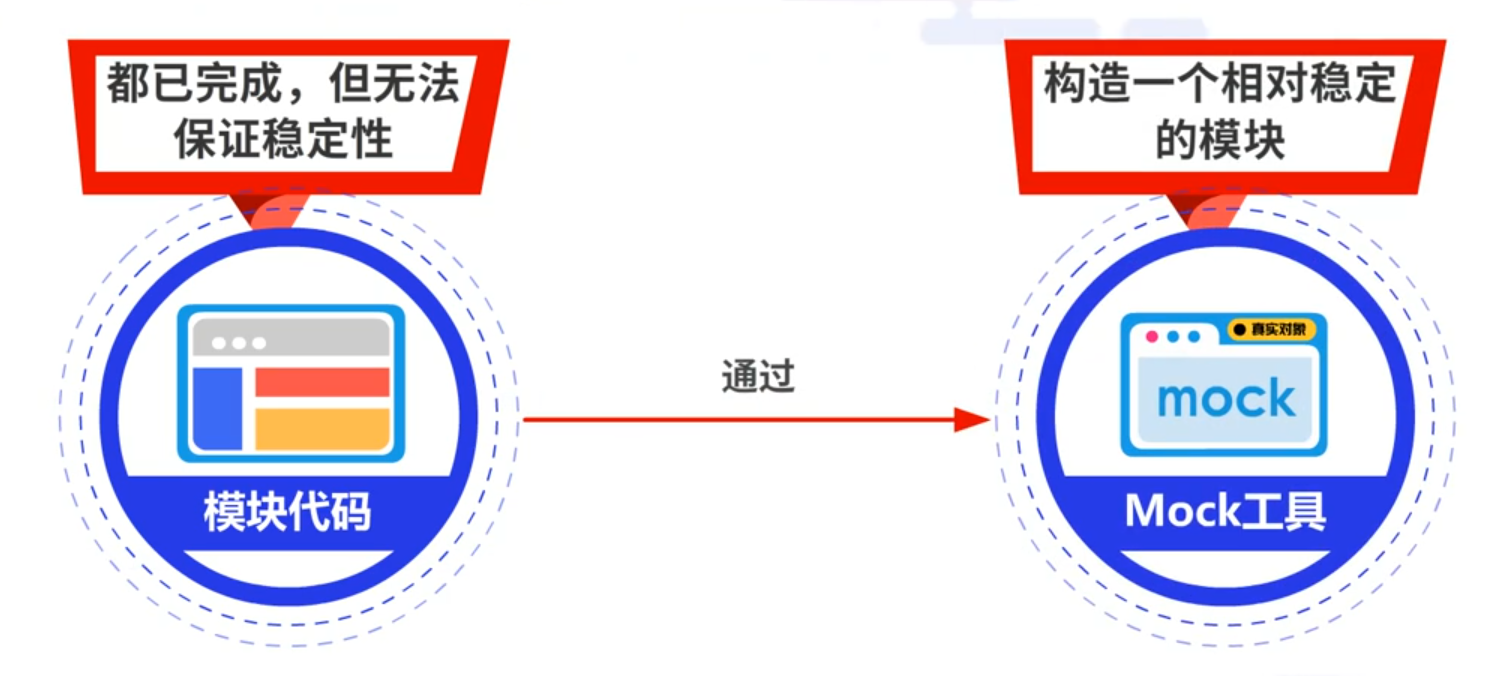 在所有模块代码都已完成,但无法保证代码稳定性的情况下。针对其他模块的质量不可靠的情况,可通过Mock工具构造一个相对稳定的模块,从而规避其他模块的问题。
在所有模块代码都已完成,但无法保证代码稳定性的情况下。针对其他模块的质量不可靠的情况,可通过Mock工具构造一个相对稳定的模块,从而规避其他模块的问题。
3.3.2 Mock使用场景
通过以下10个场景来讲述Mock的常见用法。
场景01:通过 return_value,Mock可以强行修改,永远返回我们想要的返回值,支持的类型包括string,number,Boolean,list,dict等。
场景02:将前一个例子的实例名改为类名,可实现替换类方法的返回值。
场景03:通过 side_effect,根据调用次数返回想要的结果,当超出调用次数时抛StopIteration 异常。
场景04:通过 side_effect可以完全修改函数的逻辑,使用另一个函数来替换它,根据参数返回想要的结果。
场景05:通过 side_effect抛出想要的异常或错误。
场景06:针对需要mock在特定要求下生效的情况,通过with.patch.object设定一个作用域以达到限制mock作用域的目的。
场景07:获取调用信息,如函数是否被调用、函数被调用的次数、函数被调用的形式、函数调用的参数等。
场景08:通过create_autospec在返回值改变的同时,确保api不会因mock而改变。
场景09:针对需要调用的函数、调用的接口完全没有开发的情况,可以通过Mock从零构造依赖模块从而完成测试。
场景10 :替换函数调用链。比如说用popen去执行一个命令,然后用read函数把它读取出来,再用split去做切分,这就是一个函数调用链(os.popen(cmd).read().split())。
3.3.3 Mock对编码的要求
在模块引入方式上,推荐以import XXX的形式引入,以XXX.func()形式调用,不要from.xxx import *,因为需要一个链条指向它,否则无法达到我们的预期。
3.4 总结
4 单元测试实践
4.1 Unittest 简单应用

如图所示,这是一个要被测试的类,这个类代表了一个人,类中有一个函数为get_name(),作用是获取这个人的名字。围绕着这个函数首先想到的测试点就是函数能否正确输出人名。因此就有了如下图所示的单元测试代码。
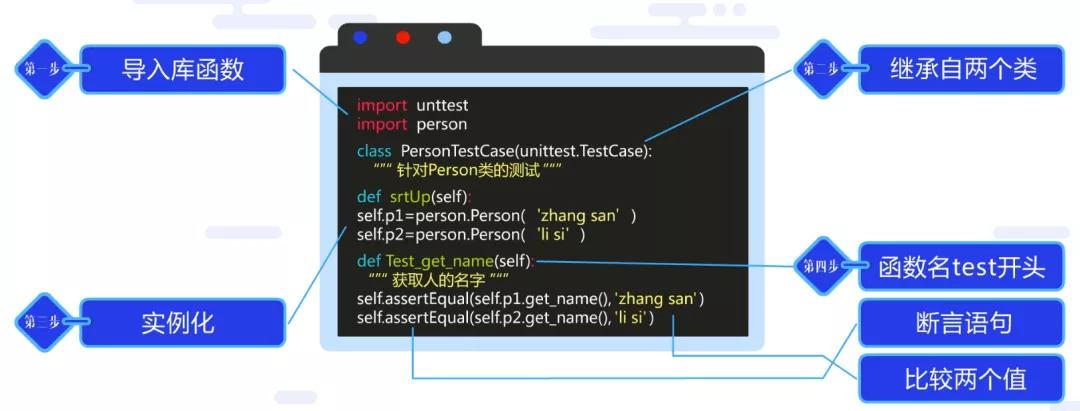
第一步,将使用到的unittest框架和所需要的函数导入。
第二步,针对被测试的函数写一个测试类,这里要注意测试类必须继承自unittest和TestCase。
第三步,构建实例化的函数,可以理解为生成两个人,一个叫张三,一个叫李四。
第四步,编写一个用于测试的函数,这里注意函数名必须是以test开头。通过图片里的代码可以看到,通过使用assertEqual断言来做相应的测试,断言中包括了两部分,第一部分是预期,第二部分是实际的值。通过对两个值的比较来完成测试。
4.2 Unittest复杂应用

下面来看一个复杂的例子。如图所示,这个被测试的类是一个公司。这个公司的信息包含了公司的名字、公司的老板、公司的员工数。在这个公司的类中设置了三个函数,老板是谁、雇佣一个新员工、解雇一个员工。通过这些信息,可以想到的测试点有:
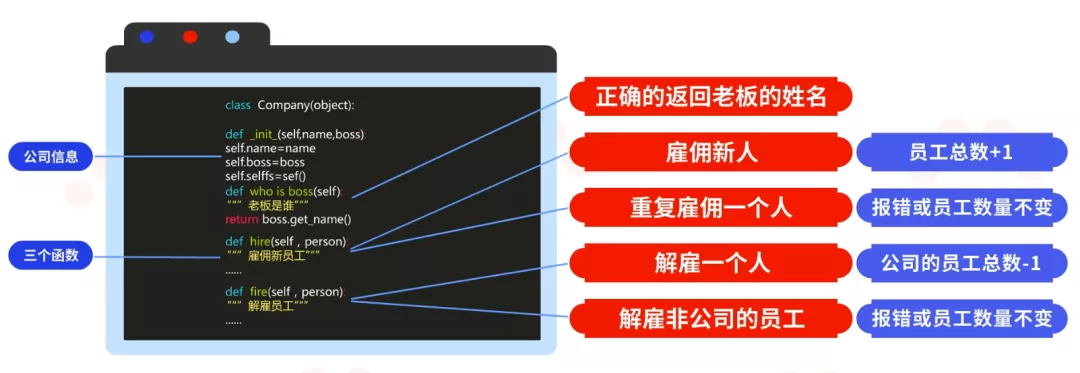
(1)who_is_boss()这个函数能够正确的返回老板的姓名;
(2)使用hire()函数雇佣新人,公司的员工总数+1;
(3)使用hire()函数重复雇佣一个人,函数会报错或者公司员工数量不变;
(4)使用fire()函数解雇一个人,公司的员工总数-1;
(5)使用fire()函数解雇非公司的员工,函数会报错或者员工数量不变。
针对以上的几个测试点,可以编写出相应的测试类。
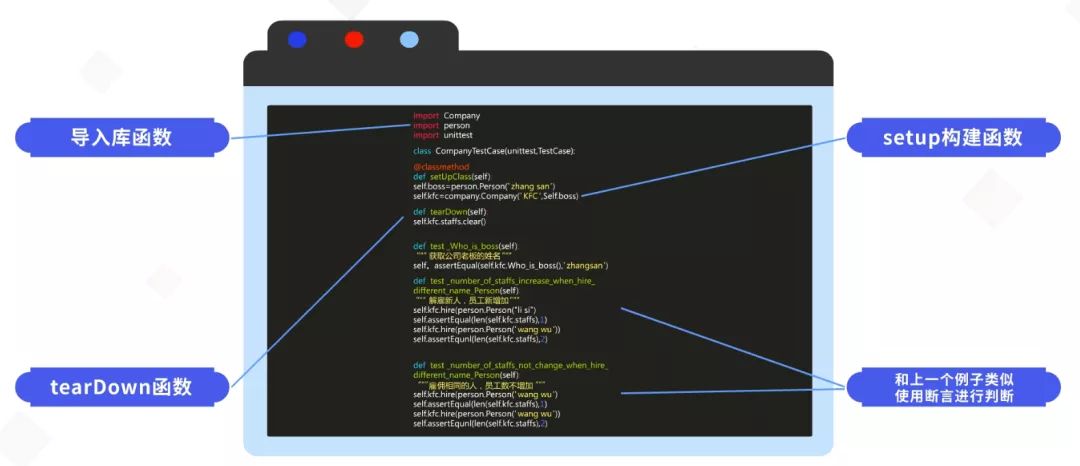
首先将所需要的类库导入,并且测试类要继承自unittest和TestCase。然后使用setUpClass()函数构建一个公司,设置老板的姓名和公司的名字。在这里设置了一个tearDown()清理函数,是为了方便测试的时候将员工全部清理掉。
通过图片可以看到,下面的三个函数原理基本跟上一个案例相同,都是通过断言来进行测试。测试类编写完成之后,需要运行这个类进行测试。如果需要执行全部的测试用例,如图所示,使用unittest.main()这个函数且不需要添加任何参数。执行完成后会得到如下图所示的结果,测试结果分为几个部分:
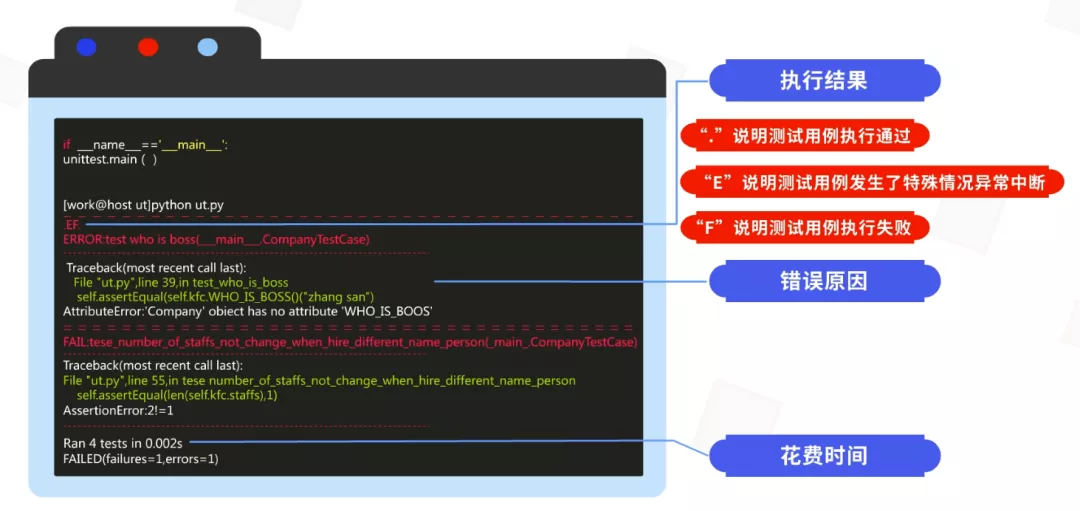
第一部分的代码展示的是执行测试用例的结果,“.”说明测试用例执行通过,“E”说明测试用例发生了特殊情况异常中断,“F”说明测试用例执行失败。
第二部分则是打印的报错信息,当出现“E”或者“F”的时候,系统会打印出异常中断和执行失败的原因。
第三部分为统计信息,包括了共执行了几个测试用例,测试用例执行共花费了多少时间,测试用例执行成功或失败的数量。
四、百度高效研发实战训练营Step4
1 代码检查规则:Java语言案例讲解
1.1 源文件规范

1.1.1 文件名
Java源文件名必须和它包含的顶层类名保持一致,包括大小写,并以.java作为后缀名。
1.1.2 文件编码
为保持编码风格的一致性,避免编码不一致导致的乱码问题,要求所有源文件编码必须使用UTF-8格式。
1.1.3 特殊字符
特殊字符方面的规则主要是针对换行、缩进、空格等操作而制定,有以下强制规定:
- 除换行符以外,ASCII空格(0x20)是唯一合法的空格字符。
- 由于不同系统将Tab转化成空格的数目不一致,统一使用空格进行缩进。
- 文件的换行符统一使用Unix格式(\n),而不要使用Windows格式(\r\n)。
1.2 源文件组织结构规范
这一大类规则主要规定了源文件所应包含的具体组成部分和各个部分之间应遵循的一系列规则。
对于源文件的组成部分,规定如下:
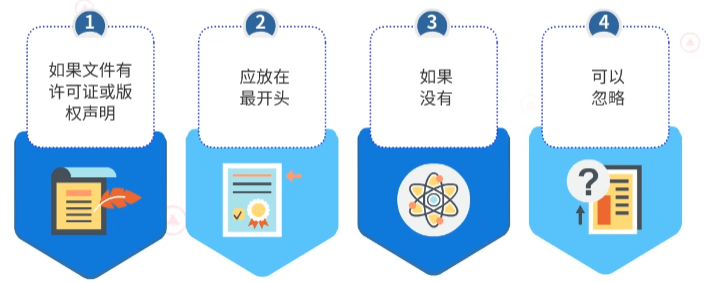
源文件必须按顺序包含:许可证或版权声明、package语句、import语句、唯一的顶层类,四个方面的内容。
同时,每两个部分之间用一个空行进行分隔,不允许出现多余空行。对于以上四个方面的内容,每个组成部分又有相应的编码规则。
1.2.1 许可证或版权声明规范
1.2.2 package语句规范
1.2.3 import语句规范
1.2.4 类声明规范
1.3 代码结构规范
1.3.1 花括号
花括号经常在类和方法定义以及代码块划分中使用,花括号在使用中常需要合理的换行操作进行配合。规定为:在非空代码块中使用花括号时要遵循K&R风格(Kernighan and Ritchie Style),三个主要原则为:
- 在左花括号({)前不能换行,在其后换行;
- 在右花括号(})前应有换行;
- 表示终止的右花括号(})后必须换行,否则,右花括号后不换行。
1.3.2 缩进与换行
缩进与换行主要是为了保证代码风格的一致性,提升代码的可维护性。主要规范有:
每次开始书写一个新代码块时,使用4个空格进行缩进,在代码块结束时,恢复之前的缩进级别。
每条语句之后都要换行,每行只能有一条完整语句。
除package语句和import语句外,代码单行字符数限制不超过120个。超出则需要换行,换行时,遵循如下五条原则:
- 第二行相对第一行缩进四个空格,从第三行开始,不再继续缩进。
- 运算符与下文一起换行,即运算符位于行首。
- 方法调用的标点符号与下文一起换行。
- 方法调用中的多个参数需要换行时,在逗号后进行。
- 在括号前不要换行。
1.3.3 空行
合理使用空行可以提高代码的可读性,有利于后期维护。
对于空行的使用,有如下规范进行约束:
- 在类的不同成员间增加空行,包括:成员变量、构造函数、方法、内部类、静态初始化块、实例初始化块等。
- 两个成员变量声明之间可以不加空行。空行通常对于成员变量进行逻辑分组。
- 方法体内,按需增加空行,以便从逻辑上对语句进行分组。
- 使用空行时,禁止使用连续的空行。
1.3.4 其他说明
Java中有两种数组定义形式,为规范代码书写形式,要求为:
①类型与中括号紧挨相连来表示数组,即中括号写在数组名之前。
而当注解与注释同时存在时,统一的规范要求为:
②添加在类、方法、构造函数、成员属性上的注解直接写在注释块之后,每个注解独占一行。
当同时存在多个修饰符时,需要按照顺序书写,顺序要求如下:
public protected private abstract static final transient volatile synchronized native strictfp
排在首位的一定是访问修饰符,随后是abstract,即抽象类或抽象方法,紧接着是static、final。这是常见的几类修饰符,对于其他的修饰符,可以参考以上列举的顺序进行书写。
为避免小写字母l与1混淆,有如下规定:
长整型数字必须使用大写字母L结尾,以便于和数字1进行区分。
1.4 命名规范
1.4.1 驼峰命名格式
对于两种驼峰命名格式的使用范围,有如下规范:
- 方法名、参数名、成员变量、局部变量都统一使用lowerCamelCase风格,即首字母小写的驼峰命名格式。
- 类名使用UpperCamelCase风格,即首字母大写的驼峰命名格式,以下情形例外:DO/BO/DTO/VO/AO/PO/UID等。
1.4.2 类的命名格式
除此之外,对于一些类,命名格式有更加具体的规范要求:
- 抽象类命名使用Abstract或Base开头;
- 异常类命名使用Exception结尾;
- 测试类命名以它要测试的类的名称开始,以Test结尾。
1.4.3 常量命名格式
常量的命名规范:
①常量命名全部大写,单词间用下划线隔开。
②不允许任何未经预先定义的常量直接出现在代码中。
1.5 OOP规约
OOP规约主要是针对面向对象编程过程中定义的一些类所制定的一些规则。
包含的强制规范要求有:
- 所有的POJO类属性必须使用包装数据类型,禁止使用基本类型。
- 所有的覆写方法,必须加@Override注解。
- Object的equals方法容易抛空指针异常,应使用常量或确定有值的对象来调用equals。
- 定义DO/DTO/VO等POJO类时,均不要设定任何属性默认值。
1.6 集合处理规范
集合和数组是我们开发过程中使用频度最高的两个数据结构,对于二者的使用也有严格的强制规范:
- 当需要将集合转换为数组时,必须使用集合的toArray方法,传入的是类型完全一样的数组,大小是list.size()。
- 对一个集合求子集合时,需高度注意对原集合元素的增加或删除,均会导致子列表的遍历、增加、删除,产生ConcurrentModificationException异常。应通过对子集合进行相应操作,来反射到原集合,从而避免异常的发生。
- 不要在循环体内部进行集合元素的remove/add操作。remove元素请使用Iterator(迭代器)方式,如果并发操作,需要对Iterator对象加锁。
1.7 控制语句规范
Java中的控制语句主要有switch、if、else、while等,这些语句的使用在编码过程中需要遵循以下规范:
- 在一个switch块内,每个case要么通过break/return等来终止,要么注释说明程序将继续执行到哪一个case为止;在一个switch快内,都必须包含一个default语句并且放在最后。
- 使用if/else/for/while/do语句必须使用花括号。即使只有一行代码,避免采用单行的编码方式。
- 在高并发场景中,避免使用“等于”判断作为中断或退出的条件。防止在击穿现象下,程序无法正常中断或退出的情况发生。
1.8 注释规约
合理使用注释可以提高程序可读性,便于后期维护。注释可以是程序说明,也可以是编程思路。Java中的注释主要分三种形式:文档注释、单行注释和多行注释。注释规约包括:
①类、类属性、类方法的注释必须使用文档注释形式,即使用 /内容/ 格式,不得使用单行注释的格式。单行注释和多行注释主要使用在方法体内。
②方法内部单行注释,在被注释语句上方另起一行,使用//注释。方法内部多行注释,使用/内容/注释,注意与代码对齐。
1.9 异常处理规范
在Java中,我们通常使用try catch来进行捕获异常处理,而Java中的异常又分为运行时异常和非运行时异常。
- 对于处理运行时异常,有如下规范:Java类库中定义的可以通过预检查方式规避的RuntimeException异常不应该通过try catch的方式来处理,比如:空指针异常和数组越界异常等等。
- 对于捕获后异常的处理,有如下规范:捕获异常是为了处理异常,不要捕获后不进行任何处理而将其抛弃。若不想进行异常的处理,应将该异常抛给它的调用者。最外层的业务使用者必须处理异常,将其转化为用户可以理解的内容。即对于捕获后的异常,要么继续向上抛,要么自己进行处理。
- 异常处理的规范要求还包括:不能在finally块中使用return语句。
1.10 缺陷检查规则
缺陷检查主要是对Java源代码进行静态分析,扫描其中潜在的缺陷,比如:空指针异常、死循环等,这一阶段所应遵循的规则包括:
- 不能使用单个字符定义StringBuffer和StringBuilder。
- 任何上锁的对象均需保证其锁可以被释放。
- 严格避免死循环的发生。
- 对于字符串中的点号(“.”)、竖线(“|”)和文件分隔符(“File.separator”)进行替代时,需要注意其特殊含义。
“.”:匹配任意单个字符。在replaceAll中使用,它匹配所有内容。
“|”:通常用作选项分隔符,它匹配字符间的空格
“File.separator”:匹配特定平台的文件路径分隔符。在Windows上,这将被视为转义字符。
- 当synchronize对成员变量进行上锁时,该成员变量必须是final类型的。
- synchronize上锁的成员变量类型一定不能是装箱类型。
- 所有被spring托管的类,其成员属性的初始化均要使用注入的方式。
- 当使用try catch方式进行异常捕获,且需要在catch中对异常信息进行输出时,不得使用printStackTrace的方式。这种方式会导致后期分析代码困难。而应采用一些Log框架,方便用户检索和浏览日志。
- 方法返回值包含操作状态代码时,该状态码不应被忽略
- 【%s】数组具有协变性,元素赋值类型与初始化类型不一致,此种情况可通过编译,但运行阶段会发生错误。
- 对于用户名和密码不应直接写在Java的文件中,避免泄露。而应将相应关键信息写在配置文件中进行读取。
- 方法和成员变量的命名不应相同,也不应通过大小写来进行区分。
2 单元测试之Java实践
2.1 如何写单元测试
2.1.1 基本流程
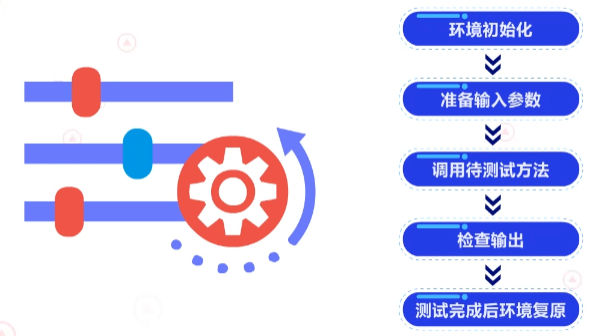
单元测试的基本流程如下:
首先,环境初始化;
其次,准备输入参数;
再次,调用待测试方法;
然后,检查输出;
最后,测试完成后环境复原。
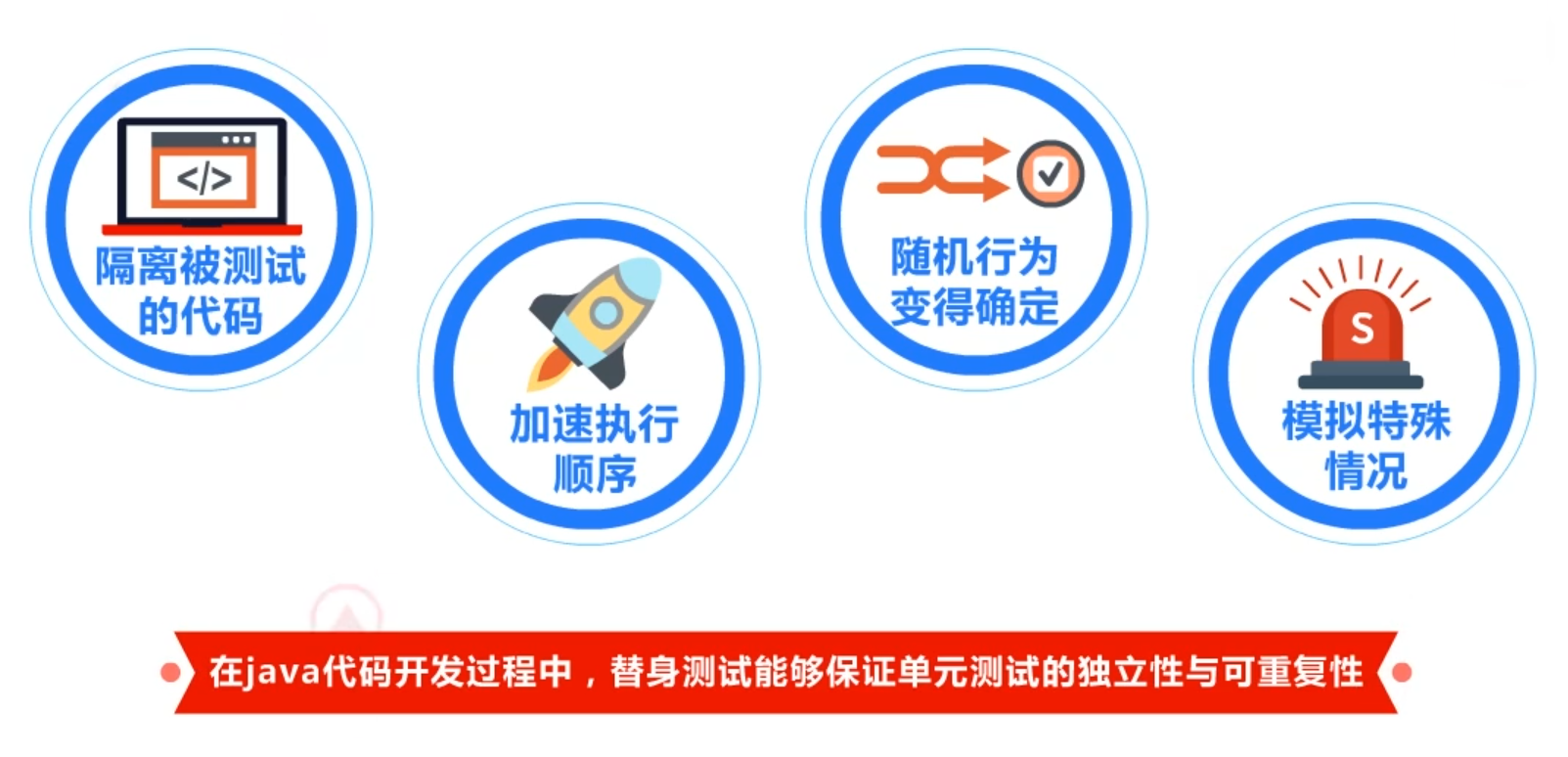
2.1.2 测试替身
测试替身可用于隔离被测试的代码、加速执行顺序、使得随机行为变得确定、模拟特殊情况以及能够使测试访问隐藏信息等。
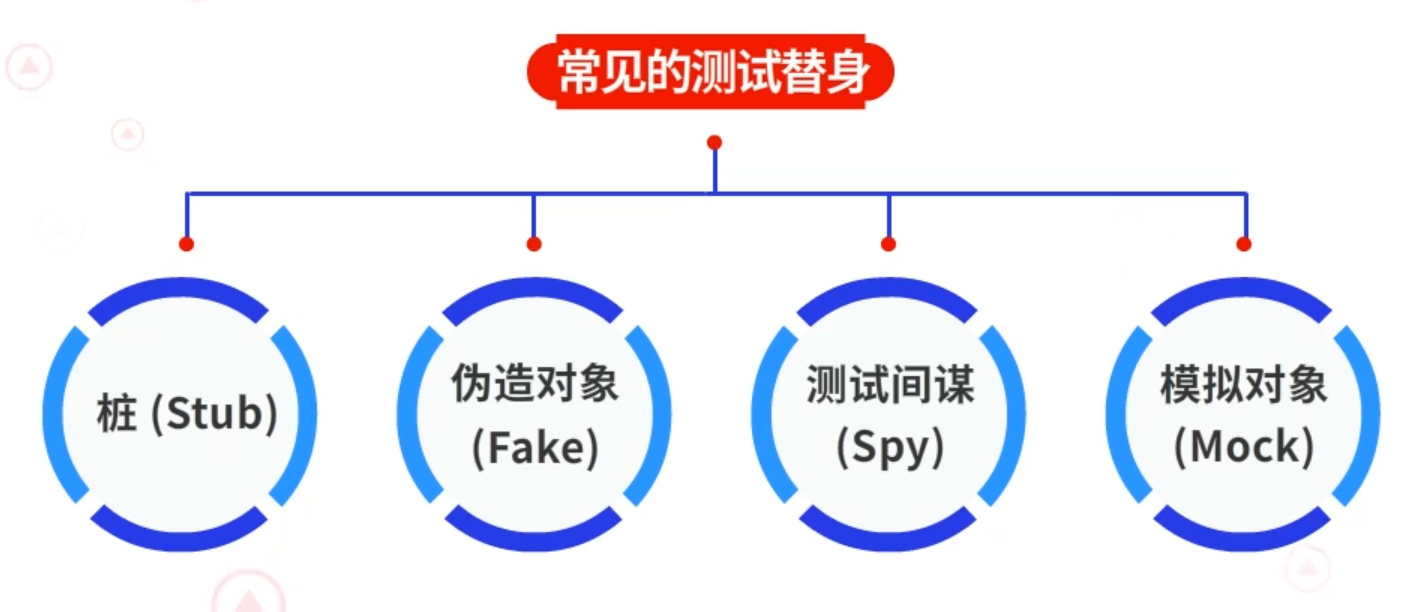
常见的测试替身有四类:桩(Stub)、伪造对象(Fake)、测试间谋(Spy)以及模拟对象(Mock)。
- Stub(桩):一般什么都不做,实现空的方法调用或者简单的硬编码返回即可。
- Fake(伪造对象):真实数据的简单版本,伪造真实对象的行为,但是没有副作用或者使用真实事物的其它后果。比如替换数据库的对象,而得到虚假的伪造对象。
- Spy(测试间谋):需要得到封闭对象内部状态的时候,就要用到测试间谋,事先学会反馈消息,然后潜入对象内部去获取对象的状态。测试间谋是一种测试替身,它用于记录过去发生的情况,这样测试在事后就能知道所发生的一切。
- Mock(模拟对象):模拟对象是一个特殊的测试间谋。是一个在特定的情况下可以配置行为的对象,规定了在什么情况下,返回什么样的值的一种测试替身。Mock已经有了非常成熟的对象库,包括JMock、Mockito和EasyMock等。
重点讲解一下模拟对象(Mock):
假如我们有业务逻辑→数据存取→数据这三层逻辑,现在需要对“业务逻辑”层进行单元测试,那么我们可以使用Mock对数据存取与数据层的内容进行模拟,从而使上面的单元测试是独立的。
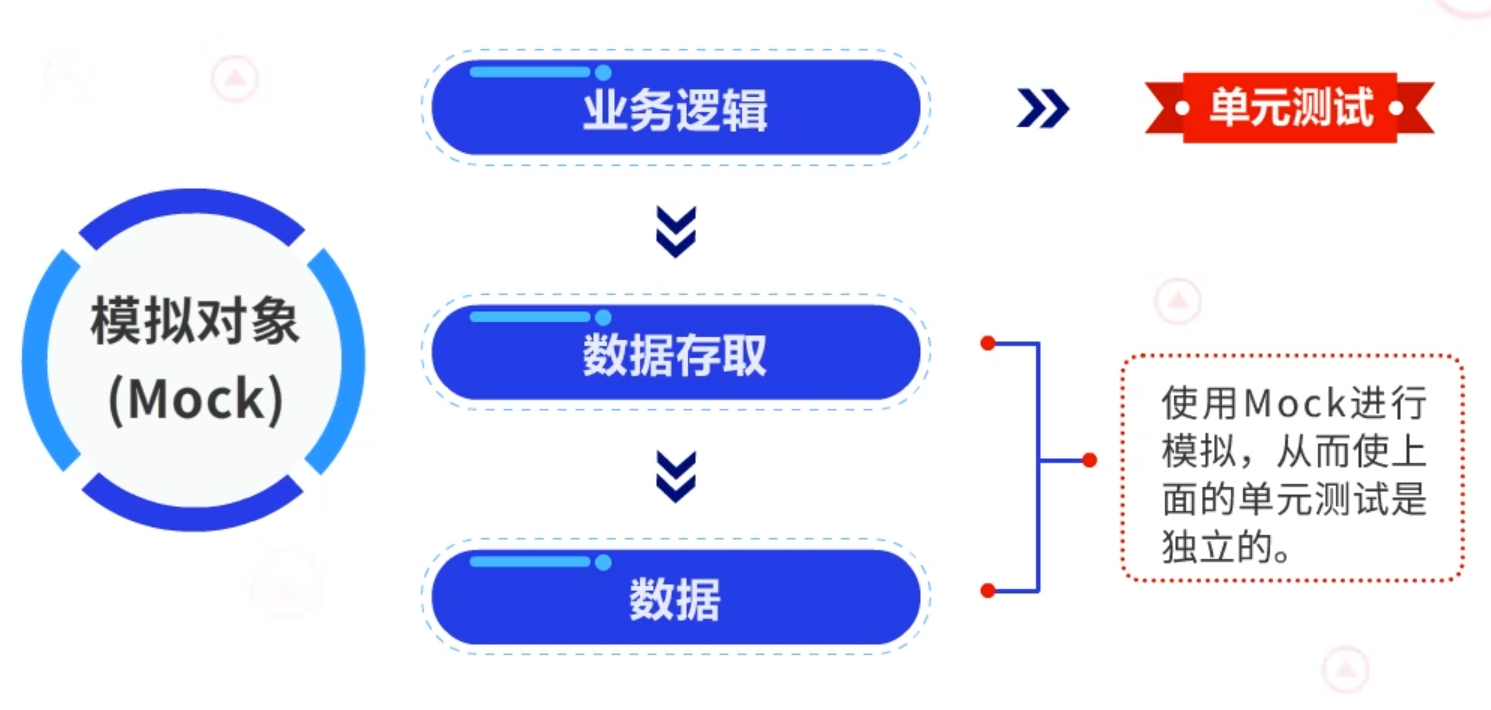
2.1.3 设计思路
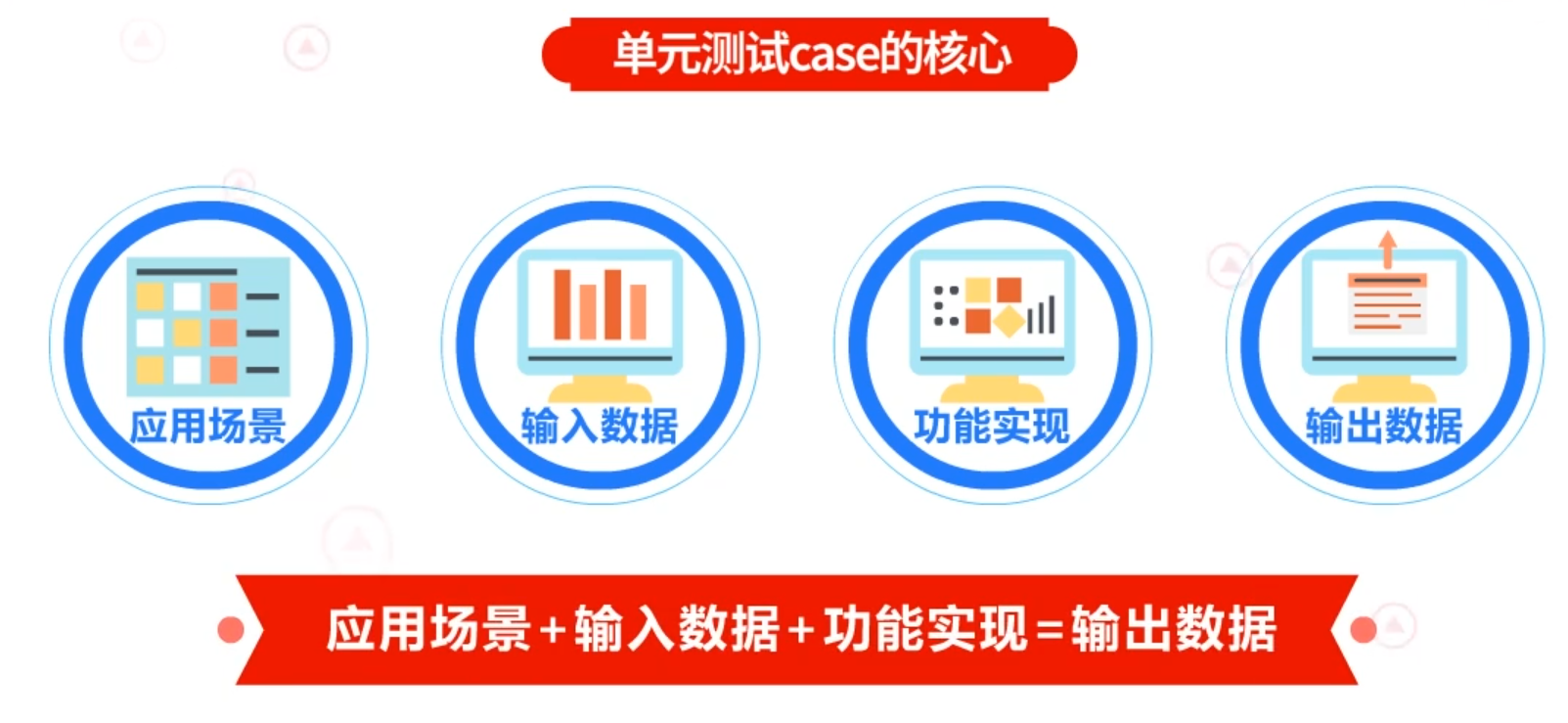
如何设计单元测试:
单元测试case的核心:结合具体的应用场景、具体的输入数据与当前函数的功能实现,对于输出数据作出具体的预期,即可把全部待测试的分支都罗列了出来。
即:应用场景+输入数据+功能实现=输出数据。
2.1.4 断言(Assertions)
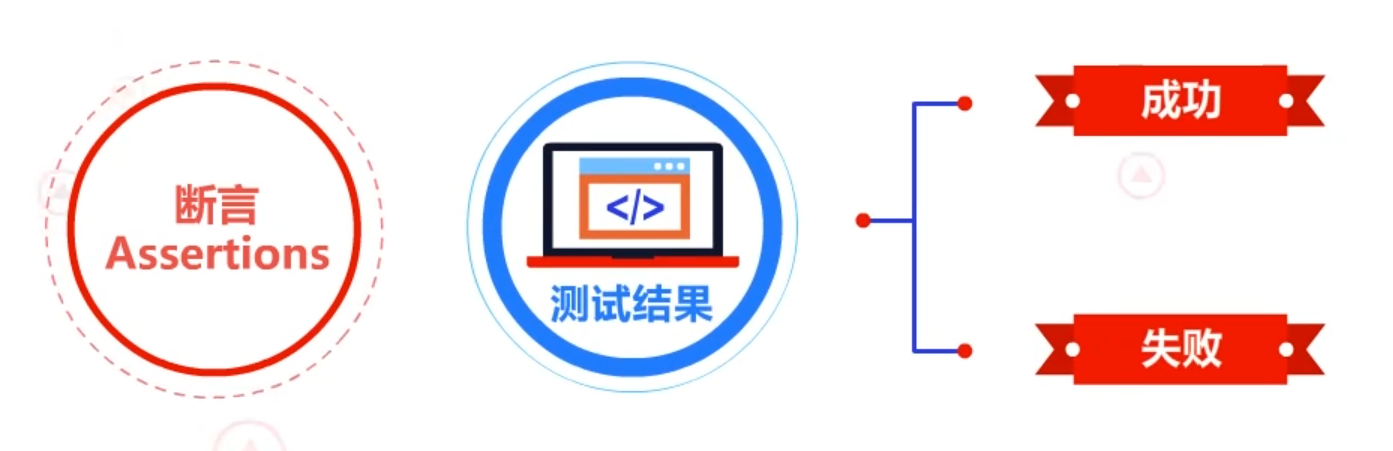
断言是一种在java单元测试中经常使用的测试方法。在单元测试中,我们使用“断言”来检验当前的测试结果是成功还是失败。
常见的断言:
Assert.assertNotNull
Assert.assertEquals
Assert.assertTrue
Assert.assertFalse
Assert.fail
在单元测试中使用断言可以令预测结果自动呈现,无需人工对单元测试结果进行判断。
2.2 单元测试的运行
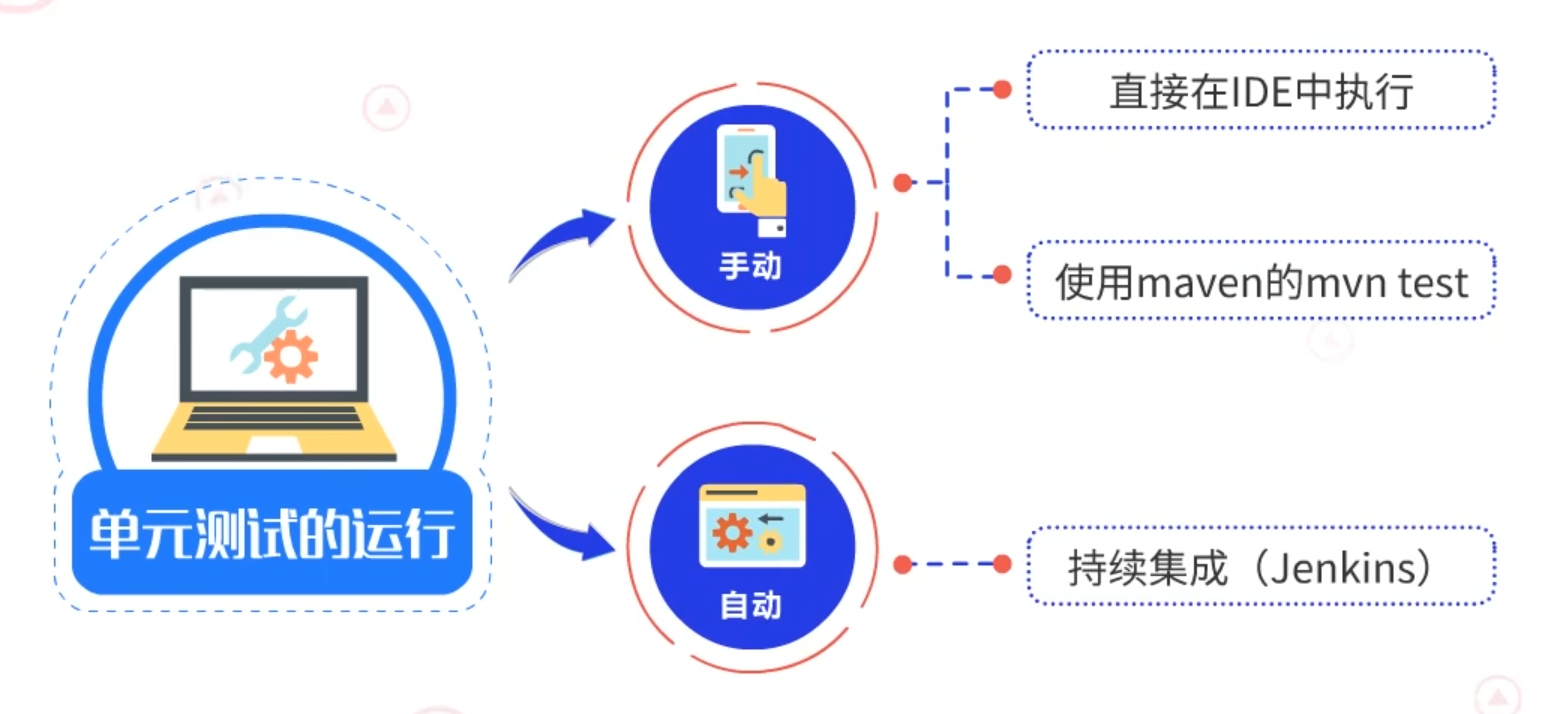
2.2.1 手动
- 直接在IDE中执行
在开发编码完成之后,开发人员可以直接在自己的环境和编译器内运行单元测试。
- 使用maven的mvn test
Maven是目前java开发中最流行的项目构建工具,它非常全面的包含了很多功能。mvn test这个测试模块就可以为我们的单元测试提供极大的便利。
2.2.2 自动
持续集成(Jenkins):自动化持续集成是我们在项目中常用的一种单元测试的方法。通用工具为Jenkins,Jenkins是一种持续集成的工具,它的功能非常强大。他的主要的功能有软件发布和版本测试、外部调用监控。
2.3 如何判断单元测试的质量

衡量标准:
从主观层面,优秀的单元测试可读性高、易于维护、值得信赖.
从客观层面,使用单元测试代码覆盖率来衡。覆盖率工具包括:集成IDE和单独布署。
3 如何做好 Code Review
3.1 为什么要做好 Code Review
3.1.1 Code Review是提升代码质量的最好方法
强化Code Review是提升代码质量的第一选择。
在代码开发过程中,我们越早发现问题、定位问题,在修复问题时付出的成本越小。
大约有50%以上的bug,都是在做Code Review时发现的。前期做好Code Review,后期将会减少反复修改等不必要的复工。
3.1.2 Code Review能够在团队内传递知识
从知识传递的角度看,Code Review是极为重要的。
做好Code Review,能够帮助团队传递知识、沟通交流、互相学习,能够提升学习能力、提升编写代码能力、提升代码质量、提升工作效率、降低项目风险。
另外,基于codebase可以使我们了解项目全局,培养系统的思考方式。
3.1.3 Code Review是辅导怎么写代码的最好方法
我们要意识到,做Code Review可以学习到别人的经验,同时也可以向别人传递我们的经验。
如果我们想辅导别人,最好的办法就是让对方先写一段代码,我们对他的代码进行Code Review。在辅导他人的过程中,我们可以快速地发现问题,从而帮助改进。
3.1.4 做好Code Review可以增加公司对最顶级开发者的吸引力
工作中是否有Code Review对于公司或团队来说非常重要。不但对于公司或团队内的人员有所提升,而且能够吸引出色的开发者加入开发团队。
未做好Code Review的公司或团队有如下特点:
- 代码质量差。
- 团队内人员备份差。
- 团队开发人员得不到有效的辅导,提高慢。
3.1.5 为什么要提高代码质量?
- 提高代码质量可以提高代码的可读性。
- 提高代码质量可以提高代码的复用性和参考性。
- 提高代码质量可以减少bug出现的风险。
- 提高代码质量可以减少后期补丁的风险。
- 提高代码质量可以降低代码失控的风险。
- 提高代码质量可以降低项目重构和升级的麻烦。
3.1.6 为什么要提高写代码的能力
- 代码能力如果停滞不前,对于个人而言,将导致职业危机。
- 代码能力如果停滞不前,对于团队而言,将意味着团队没有成长。
Code Review是一个非常重要的提升代码质量和代码能力的手段。无论是从个人发展角度,还是团队发展角度,我们都需要重视Code Review。
3.2 如何做好 Code Review
3.2.1 在Code Review中可能发现的问题
3.2.2 在Code Review中应有的态度
对所有检查的代码逻辑要做到“完全看懂”,对于审核的代码,熟悉程度要做到“如数家珍”。如果在审核代码后,对代码的逻辑和背后的原因仍然很模糊,则是一个失败的Code Review。
好代码的标准,不仅仅是“可以运行通过”,在正确性、可读性、可重用性、可运维性等方面上,都需要综合考虑。
建立Code Review和写代码一样重要的意识。即:
- Code Review和写代码一样,也有产出,即产出更高质量的代码。
- 审核代码在很多情况下比写代码还要辛苦,需要理解和找出问题等。
以提升代码质量为最终目标。
要投入足够的时间和精力。
1. 审核代码花费的时间经常和写代码一样多,有时甚至比写代码的时间更多,要有时间意识。 1. 要有责任意识。如果出现bug,不仅仅是写代码人员的职责,也不仅仅是QA的职责,代码审核者也需要承担相当大的责任。
3.2.3 在Code Review之前,需要了解一流代码的特性
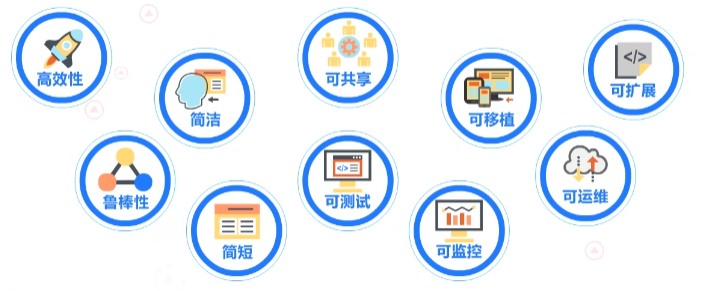
一流代码有以下特性:①高效性;②鲁棒性;③简洁;④简短;⑤可共享;⑥可测试;⑦可移植;⑧可监控;⑨可运维;⑩可扩展。
将以上十条标准进行总结精简归纳为:
- 代码的正确和性能;
- 代码的可读和可维护性;
- 代码的可运维和可运行;
- 代码的可共享和可重用;
在Code Review时,综合考虑以上一流代码的特性,可以快速提升代码质量、提升编写代码的能力等。
3.2.4 在Code Review时,需要有对 bad code 进行简单判断的能力
通常bad code有以下特点:
- 5分钟内不能看懂的代码。
不能快速看懂的代码,一定是有问题的代码,可以先抛回给编写代码人员进行修正。一般一个函数的操作不能超过6个step,如果超过这个数量,则需要重新调整编码逻辑。
- 需要思考才能看懂的代码。
好的代码阅读时基本不用动脑子,甚至看注释就能看懂。
- 需要来回翻屏才能看懂的代码。
好的代码,经常在一屏内就是一个完整的逻辑。
- 没有空行或注释的代码。
在Code Review时,发现不会用段落、不会写注释的代码,肯定不是好的程序员写的代码,可以直接打回给编写代码人员进行修正。
3.2.5 Code Review的注意事项
- 在必要时,review的双方做面对面的沟通。
面对面沟通并不是单指当面沟通,还包括云共享、电话、视频沟通等。在沟通时,对于背景、关键点等应进行说明,便于reviewer的理解。在必要时,应提供设计文档。
- 对于关键模块,应该建立owner制度。
所有提交的代码,必须由owner做最终确认。由owner掌握全局,并建立明确的责任关系。
检查中发现的问题,要一追到底。
要注意细节。对每一行提交的代码,都要进行检查。
Code Review的方式,要小步快跑。每次提交review的代码量不要太多,降低复杂度。在特殊情况时,比如一个新模块的构建,最好逐步完成,通过多次进行提交。
要为Code Review预留出足够的时间。Code Review VS Coding的时间,有时可能达到1:1。在这里需要考虑到有时会做大的修改,科学地规划工作量,尽量避免出现时间倒排。
注意每天 review代码的数量不宜过多。
3.2.6 Code Review的步骤

Code Review的步骤为以下几点:
Step1:先看系统全貌
不深究细节,浏览系统全貌,理清模块划分的逻辑、模块间的关系、如何构成的整个系统等。
Step2:进入模块级别
同样不深究细节,浏览模块内的全貌,判断模块切分是否合理,理清模块内的逻辑,明确关键数据、关键的类和函数等。
Step3:理清类、函数内部的逻辑。
Step4:进入细节。
比如Layout、命名等。
3.2.7 人为因素
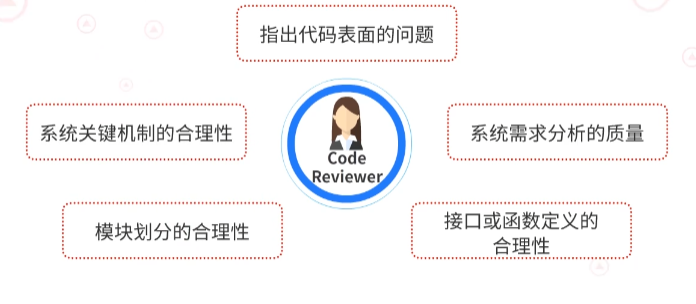
除了代码上的问题,在Code Review过程中还会有一些人为因素,例如:
①QA人员
好的QA人员不仅仅会发现系统中的bug,还会质疑或提出产品需求,挑战或优化系统架构和实现方式。
②Code Reviewer
好的代码审核人员不仅仅指出代码表面的问题,还会检查系统需求分析的质量、接口或函数定义的合理性、模块划分的合理性、系统关键机制的合理性等。
3.3 例子:Python 代码的 Code Review
3.3.1 Python的编码规范

代码要写的漂亮。
代码要明确直接,不要含蓄表达。
代码要简洁,一个函数可以实现的功能就不要写两个函数。
代码深奥胜过代码复杂。代码可以写的深奥难懂,但是不能写的过于复杂。
代码要平铺直叙,不要层层嵌套。
代码要做到合理间隔。
代码可读性非常重要。
代码要有普适性。尽量规避代码特殊性,用最简洁最通用的代码来实现。
代码要实用。
要重视所有发现的错误。
代码逻辑要清晰。在含糊混乱的面前,我们要拒绝猜测。读写代码时,不要出现“好像”、“可能”、“似乎”等猜测。当一段代码很难懂的时候,代码一定存在问题。
写代码要注重行动。
代码实现方法要简洁。如果一个方法很难解释,就意味着这个方法存在一定的问题。
要重视命名空间的使用。
3.3.2关于Python编程规范的部分说明
Python编程规范有九个维度。
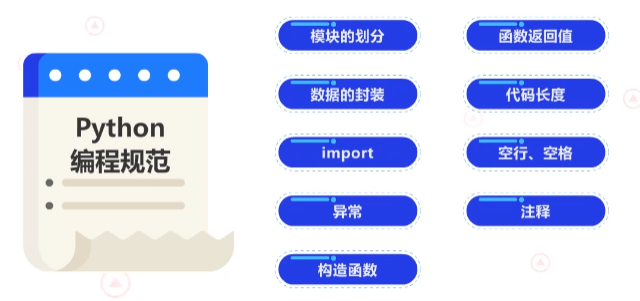
1 模块的划分

我们要对模块有概念,这是整个系统的基础。
一个.py文件是一个模块。
模块的划分对软件的长期维护非常重要。
每个模块都应该有特定的功能。
比如:配置文件的读取,网页文件的写入,网页文件的解析,一个内存数据表,一个抓取的线程等等。
- 多个本应独立的模块,写到一个.py文件中是常见的错误。从Code Review角度看,首先就是要看模块切分的对不对。
2 数据的封装

在Code Review时,要着重注意数据是否封装这一问题。
3 import

Import在使用过程中,禁止使用from xxx import yyy语法直接导入类或函数。禁止使用from xxx import *这样的方法。这样做的目标是:容易判断代码中使用外部变量或函数的来源。
如果使用禁止中的语法,会大大增加判断来源的难度,以及代码阅读的难度。
在Code Review时,遇到这种情况,及时将代码打回给编程人员进行修正。
4 异常
对于异常的处理有以下几点需要注意:

- 异常的使用
使用异常前请需要详细了解异常的行为。不要主动抛出异常,使用返回值。如果一定要抛异常,需要注释进行说明。
- 异常的获取强制
除非重新抛出异常,否则禁止使用except:捕获所有异常,不建议捕获Exception或StandardError。
在实际编码中建议try中的代码尽可能少,避免catch住未预期的异常,掩藏掉真正的错误。底线是至少要打印异常的日志,而不是捕获后直接pass通过。
在对异常进行处理时尽量针对特定操作的特定异常来捕获。
- 函数的返回值
如果函数会抛出异常,需要在函数的注释中明确说明。
在Code Review时,需要注意上述问题,及时返回给编程人员进行修正。
5 构造函数
对于构造函数有以下几点需要注意:
- 规范:
类构造函数应该尽量简单,不能包含可能失败或过于复杂的操作。
- 解读:
在构造函数中常出现的错误是:无法判断、或捕获异常。
6 函数返回值
对于函数返回值有以下几点需要注意:
- 规范:
函数返回值必须小于等于3个。返回值超过3个时必须通过class/namedtuple/dict等具名形式进行包装。
- 解读:
a. 多数情况下的错误,是因为很多人不会思考和设计函数的语义。
函数描述涉及的三要素为:功能描述、传入参数描述和返回值描述。
每个函数都应该有足够明确的语义。基于函数的语义,函数的返回值有三种类型:
b .另外,函数需要有返回值,对于正确或错误的情况,在返回值中要有体现。
c .还有一个问题是:Python的数据格式不需要定义,过于灵活。当程序规模变大、维护周期变长时,会导致后期极难维护。
应对措施是:多写注释,写清楚返回值说明、参数说明。

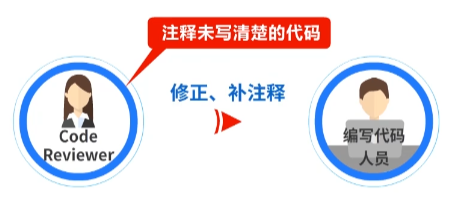
在Code Review时,注释未写清楚的代码,一定要打回给编程人员,进行修正、补注释。
7 代码长度
关于代码长度有以下几点需要注意:
- 每行不得超过120个字符。避免在终端上显示出现折行。
- 函数长度不得超过100行。函数过长会增加理解函数逻辑的难度。Python的函数应尽量控制在30~40行之间。
在Code Review时,代码过长,建议全部打回给编程人员进行修正。
8 空行、空格
关于空行、空格有以下几点需要注意:
- 空行
文件及定义之间隔两个空行。比如类或全局函数。类方法之间隔一个空行。
- 空格
逗号、分号、冒号前不加空格,后边加一个空格。所有二元运算符前后各加一个空格。
在Code Review时,需要着重注意空行和空格。空行和空格不是可有可无的。空行和空格的存在,是为了增加可读性。不好读的代码,一律打回给编程人员进行修正。
9 注释
关于注释有以下几点需要注意:
Python中的注释有一个特殊之处是docstring,docstring要和“#”注意区分开。
相关规范有:
使用docstring描述module、 function 、class和method接口时,docstring必须用三个双引号括起来。
对外接口部分必须用docstring描述。内部接口视情况自行决定是否写docstring。
接口的docstring描述至少包括功能简介、参数、返回值。如果可能抛出异常,必须使用注释进行说明。
每个文件都必须有文件声明,文件声明必须包括以下信息:版权声明、功能和用途简介、修改人及联系方式。
在Code Review时,不符合上述规范的,及时打回给编程人员进行修正。
3.4 如何成为一个好的reviewer
代码审核的质量,和审核者的代码能力直接相关。代码审核的质量差,反映的是审核者的代码水平。如果作为一个代码审核员不会写代码,就要承认真相,并且要不断提高自己的代码能力。
学习资料:
- 关于代码的书籍:《编写可读代码的艺术》,《代码整洁之道》。
- 综合的书籍:《代码大全》,《201 principles of software development》。
- 其他:《代码的艺术》课程,Python Good Coder考试指南。
3.5 公司针对 Code Review 的措施
1、建立高效可运营的代码审核机制,提升代码质量,降低代码评审成本。
①基于平台:icode+bugbye
②代码检查规则分级,分为ERROR、WARNING、ADVICE三类,对ERROR级别阻塞提交。
③通过统计数据驱动代码检测规则的优化。
2、通过工程能力地图考察项目的Code Review情况。
3、所有的Code Review行为,都基于icode平台进行。良好的工具可以帮助更好的进行代码审核
3.6 Code Review 总结
 微信扫码
微信扫码 支付宝扫码
支付宝扫码



