虚拟机搭建Hadoop集群
虚拟机搭建Hadoop集群
1. 创建虚拟机
下载VirtualBox或其他虚拟机软件并安装.
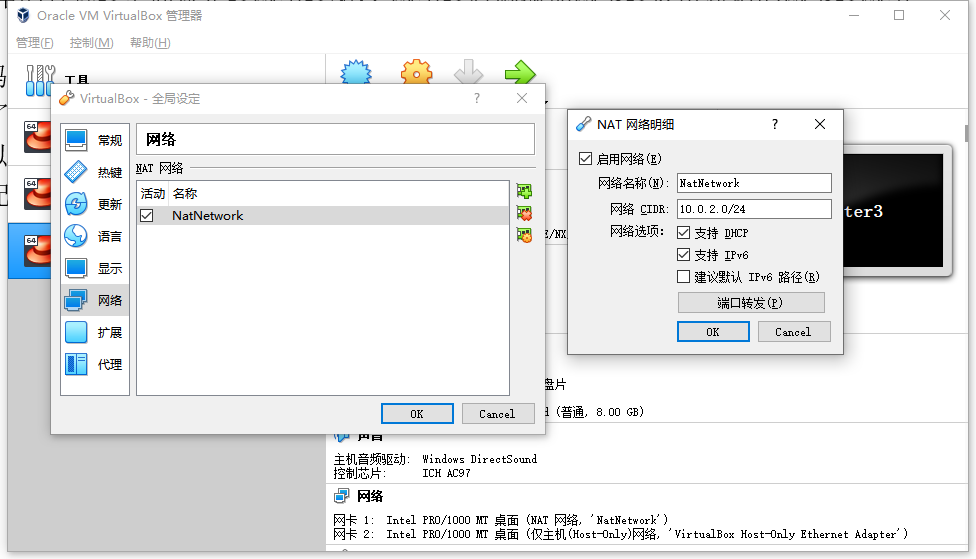
进入管理菜单->全局设置->网络->添加新NAT网络, 勾选启用网络并开启DHCP,确认即可.
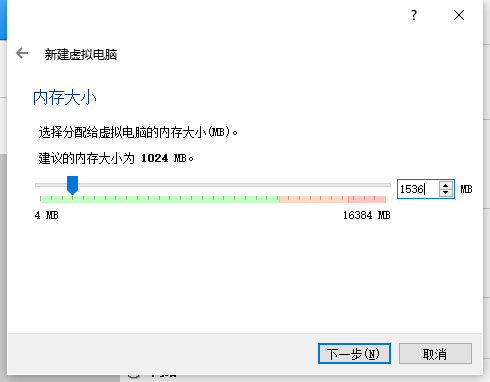
随后点击新建虚拟机, 将名称改为cluster1, 虚拟机类型选择Linux, Red Hat(64位),

将内存大小改为1536MB,点击下一步
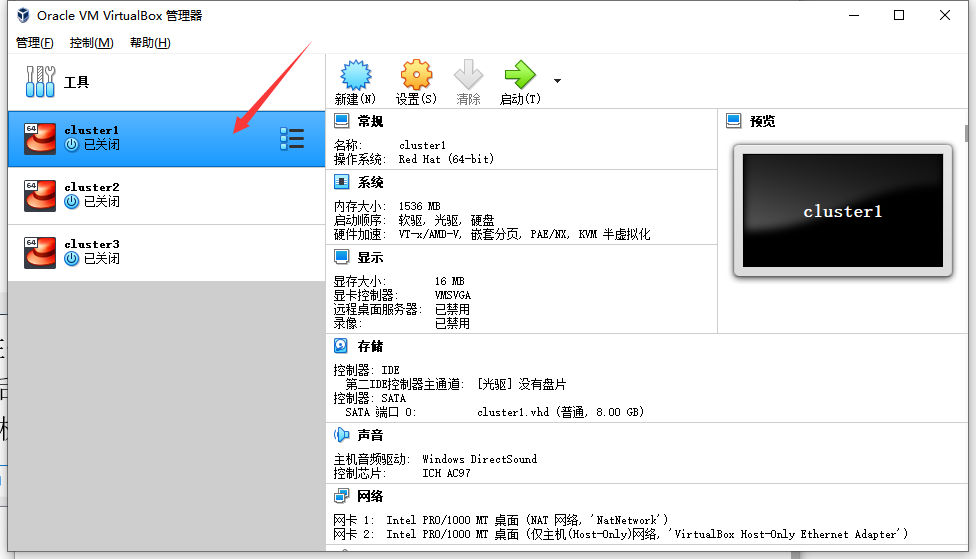
选择现在创建虚拟硬盘(VHD, 动态分配, 8G), 点击创建即可成功创建虚拟机:
如下图所示,
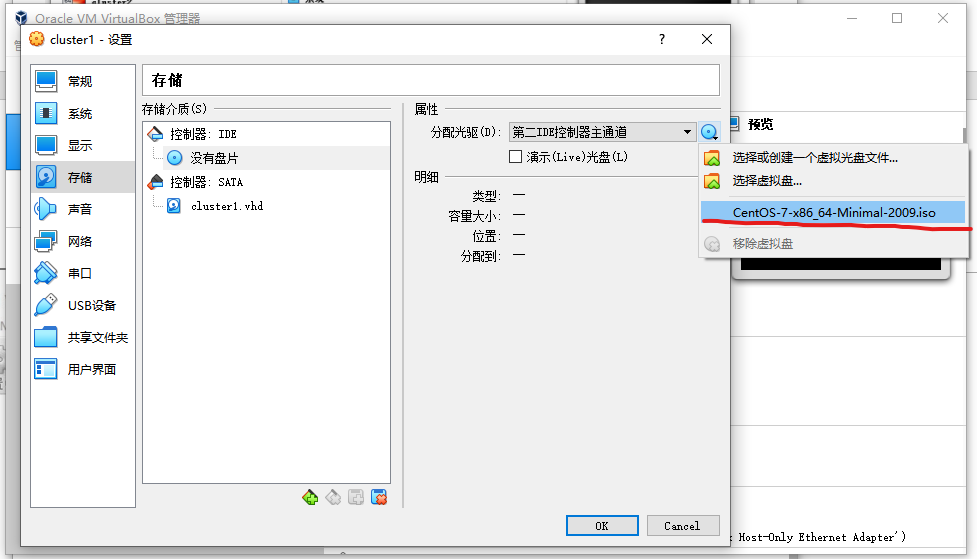
进入刚刚新建的虚拟机设置, 在网卡1处连接方式选择NAT网络, 在网卡2处勾选启用网络连接,连接方式设为: 仅主机(Host-Only)网络,点击OK即可,网络信息如下所示,

然后选择存储设置, 加载CentOS7系统镜像到光驱
确认之后将虚拟机启动,
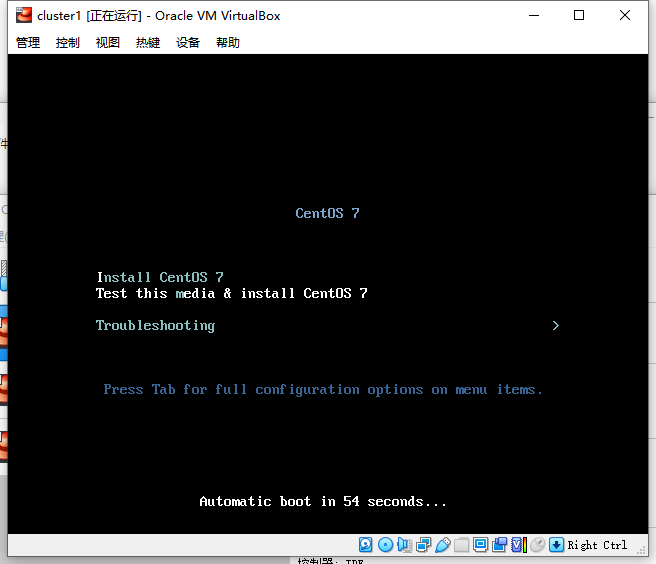
单击界面,让Virtual Box捕获鼠标(注:右Ctrl键可以接触捕获), 上移光标至Install CentOS 7处按回车键进行系统安装,
随后单击Continue
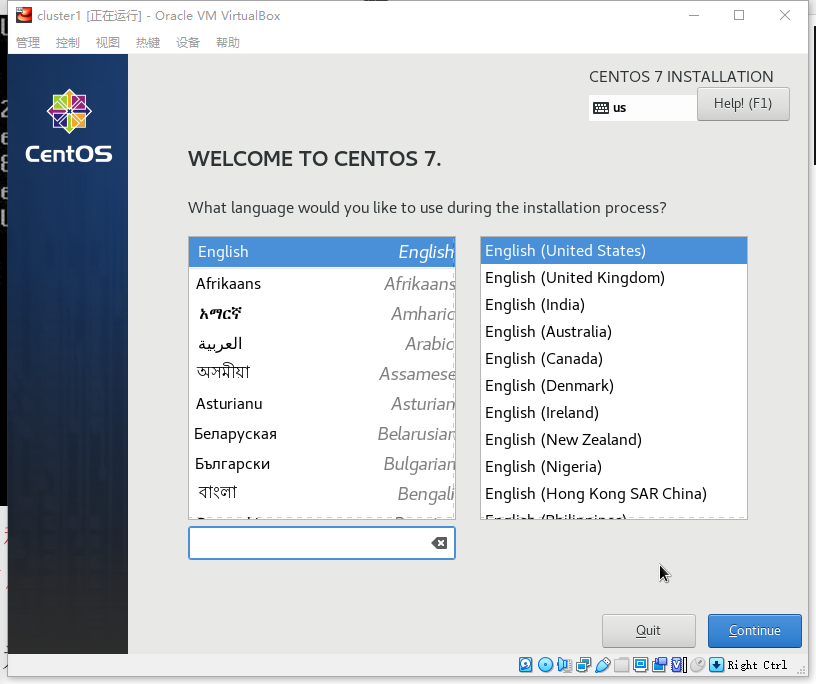
将时区更改为: :earth_asia: Asia, Shanghai

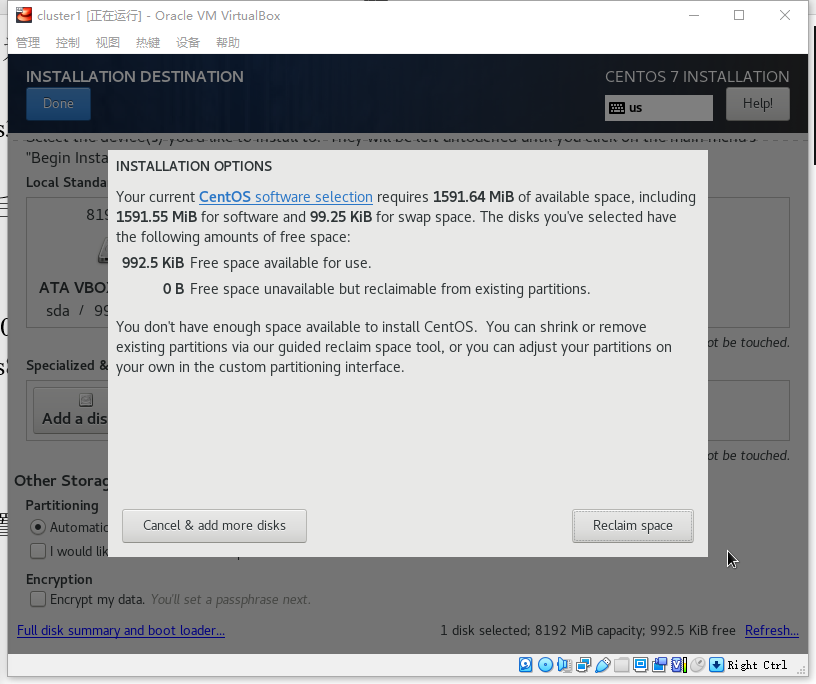
磁盘分区默认即可,
随后设置用户名和密码, 如果密码不符合安全要求, 会需要点击两次以确认,耐心等待系统安装完成,然后点击重启按钮, 系统即安装完成
另外创建两台配置一样的虚拟机, 用户名分别为 cluster2 和 cluster3.
2. 准备工作
2.1 关闭防火墙和 Selinux
1 | // 关闭防火墙并阻止服务开机启动 |

1 | // 编辑Selinux配置文件关闭Selinux |
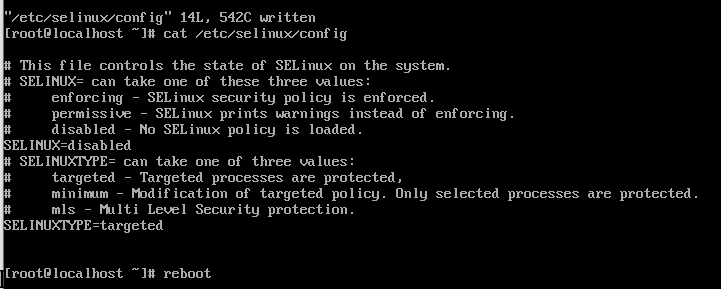
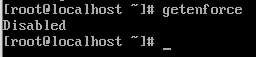
另两台虚拟机进行同样的操作.
2.2 检查网卡是否开机自启
使用ip addr命令查看网卡名称,
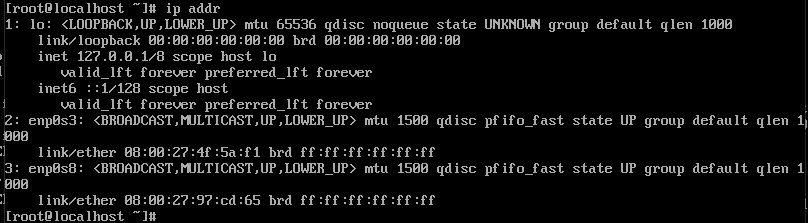
可见两张网卡均未启用,
接下来编辑第一张网卡的配置文件, 修改如下文件/etc/sysconfig/network-scripts/ifcfg-enp0s3,将其中的ONBOOT项修改为yes,使网卡能够开机自启,
随后编辑第二章网卡的配置文件etc/sysconfig/network-scripts/ifcfg-enp0s8, 将BOOTPROTO设置为none, ONBOOT同样改为yes,并新增如下项:
1 | IPADDR=192.168.56.121 # cluster2为192.168.56.122, cluster3为192.168.56.123 |
保存之后, 重启网络服务发现配置成功

将另外两台机器也配置完成,进入下一步,
将网络配置成功之后我们就可以使用SSH工具连接虚拟机了,在这里我使用Finalshell工具进行连接:
添加如下所示的三个连接就可以连上虚拟机了:
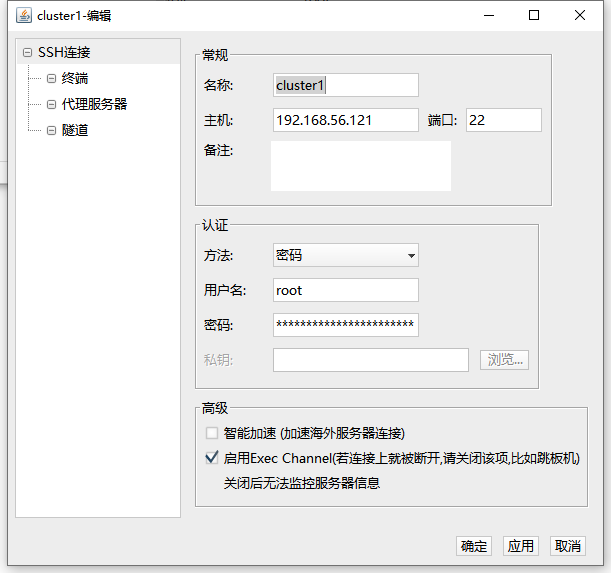
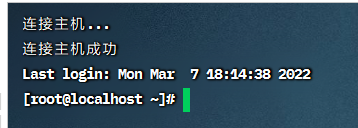
对于文件传输功能, Finalshell有集成功能可以方便的拖拽文件进行上传和下载操作.
2.3 安装软件
每台机器上都要安装,
1 | yum install perl* ntpdate libaio screen -y |
2.4 修改hosts
将每台机器的ip写入每台机器的hosts文件
1 | 10.0.2.8 cluster1 |
修改之后测试网络连通性, 在cluster1上 ping 另两台机器:
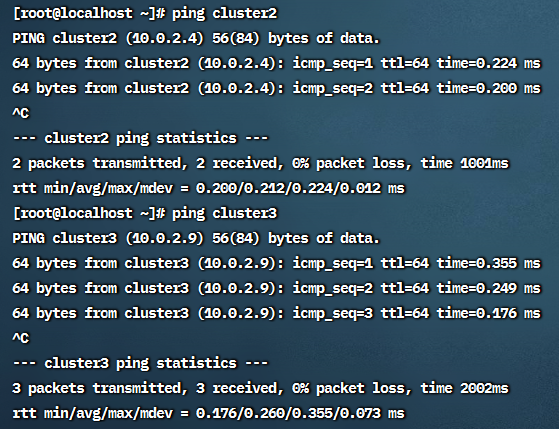
可见hosts文件生效.
2.5 新建用于维护集群的hadoop用户
在每台机器上用root用户执行
1 | # 新建hadoop组 |
2.6 生成SSH密钥并分发
首先在cluster1上切换到hadoop用户, 然后执行如下命令生成密钥:
1 | ssh-keygen -t rsa |
随后分发密钥,
1 | ssh-copy-id cluster1 |
密钥分发完毕, 使用cluster1与cluster2和cluster3建立连接均能成功,说明密钥分发无误.

2.7 安装NTP服务
在三台机器上安装ntpdate
1 | yum install ntpdate |
在cluster1上执行yum安装命令安装ntp并将/etc/ntp.conf文件的下列四行注释掉,
1 | server0.centos.pool.ntp.org iburst |
在文件末加入如下内容:
1 | restrict default ignore |
重启ntp服务并设置ntp 服务器开机自启
1 | service ntpd restart |
接下来对cluster2和cluster3这两个客户端进行配置:
设定每天0:00向服务器同步时间并写入日志:
1 | # crontab -e |
输入以下内容后保存并退出:
1 | 0 0 * * * /usr/sbin/ntpdate cluster1>> /root/ntpd.log |
之后在两台客户机上使用ntpdate cluster1同步时间.
 3. 安装MySQL
3. 安装MySQL
3.1 安装
只需要在cluster2上安装一个MySQL即可
登录root用户以执行以下命令:
若安装过MySQL先移除原有MySQL:
1 | yum remove mysql mysql-server mnysql-libs compat-mysql51 |
将mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz上传至cluster2,随后将其解压到/usr/local/目录下,并将解压后的文件目录名改为mysql
1 | tar -zxvf mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz |
将MySQL添加进环境变量:在/etc/profile末尾添加:
1 | export MYSQL_HOME=/usr/local/mysql |
随后用source命令使其生效
1 | source /etc/profile |
新建MySQL用户:
1 | groupadd mysql |
将当前目录的拥有者改为root
1 | chown -R root |
修改当前data目录拥有者为mysql
1 | chown -R mysql data |
用bin/mysql命令登录MySQL,成功后使用exit;命令退出即可
进行修改MySQL的root账户密码操作
1 | bin/mysql_secure_installation |
查看MySQL的进程号并kill掉
1 | ps -ef | grep mysql |
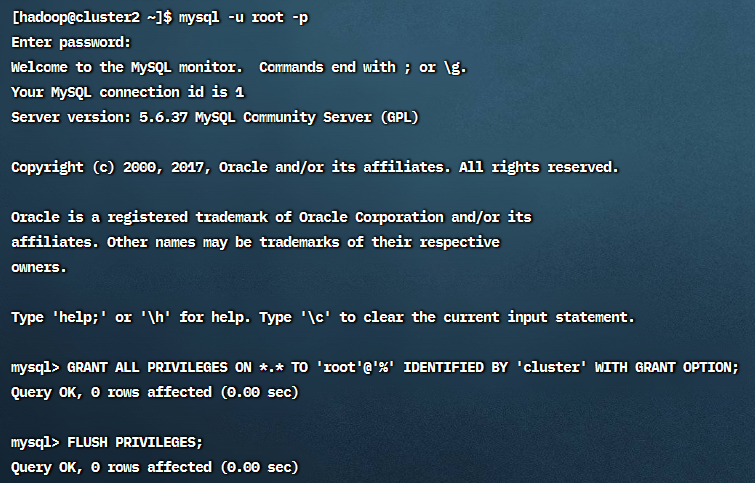
用普通用户配置访问权限:
1 | mysql -u root -p |
1 | mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'cluster' WITH GRANT OPTION; |
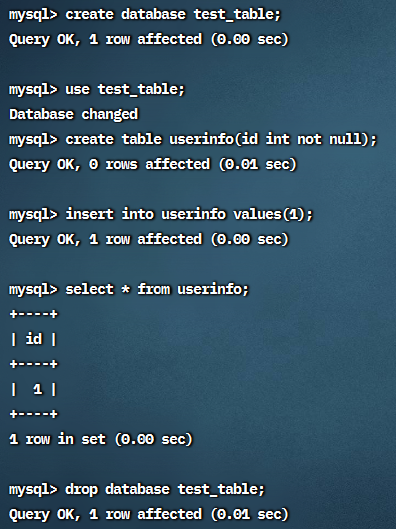
3.2 测试
1 | mysql> create database test_table; |
4. 安装JDK
需要在每台机器上安装JDK,将jdk压缩包传到服务器/usr/local目录下并解压,修改环境变量:
1 | export JAVA_HOME=/usr/local/jdk1.8.0_102 |
配置完成,并使用scp命令将jdk复制到其他节点:
1 | scp -r /usr/local/jdk1.7.0_80/ cluster2:/usr/local/ |
同样的方式将jdk目录写入环境变量
5. 安装Zookeeper
最终需要在每一台机器上安装ZooKeeper:
在cluster1上将zookeeper的压缩包解压到/usr/local目录下,
并写入环境变量:
1 | export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.6 |
随后在 /usr/local/zookeeper-3.4.6/conf/zoo.cfg中新建zoo.cfg文件,写入如下内容:
1 | # 客户端心跳时间(毫秒) |
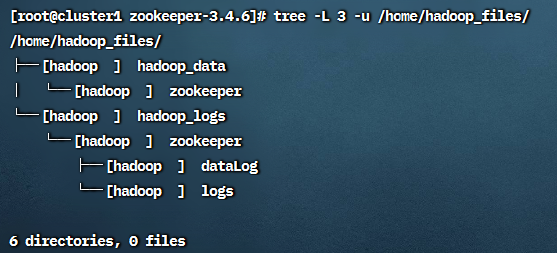
接下来创建zookeeper的数据目录和日志存储目录, 并修改文件夹的权限:
1 | mkdir -p /home/hadoop_files/hadoop_data/zookeeper |
在 cluster1 号服务器的 data 目录中创建一个文件 myid,输入内容为 1, 且myid 应与 zoo.cfg 中的集群节点相匹配, cluster2和cluster3就写2和3
1 | echo "1" >> /home/hadoop_files/hadoop_data/zookeeper/myid |

接下来修改zookeeper/目录下相关配置文件
修改 zookeeper 的日志输出路径(注意CDH 版与原生版配置文件不同)
修改bin/zkEnv.sh中的部分如下所示:
2
3
4
5
6
7
8
then
ZOO_LOG_DIR="/home/hadoop_files/hadoop_logs/zookeeper/logs"
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi
然后修改conf/zookeeper的日志配置文件log4j.properties:
1 | zookeeper.root.logger=INFO,ROLLINGFILE log4j.appender.ROLLINGFILE=org.apache.log4j.DailyRollingFileAppender |
将zookeeper-3.4.6的内容复制到其他两个节点上:
1 | scp -r /usr/local/zookeeper-3.4.6 cluster2:/usr/local/ |
接下来切换到hadoop用户,使用source /etc/profile刷新环境变量,随后启动zookeeper:
1 | zkServer.sh start |
三台机器都把zookeeper启动之后用命令jps查看进程是否启动:
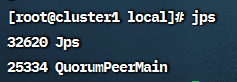
可以看到在每台机器上都能看到一个叫QuorumPeerMain的进程,说明启动成功
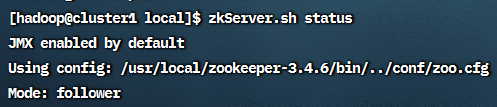
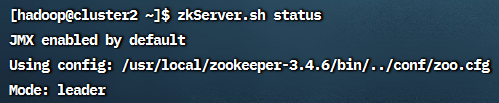
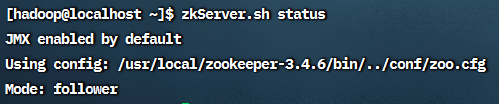
可以看到三台机器中一台是leader,另两台是follower
zookeeper的关闭命令是zkServer.sh stop
6. 安装Kafka
6.1 安装
在cluster1上解压kafka到/usr/local
然后添加环境变量:
1 | export KAFKA_HOME=/usr/local/kafka_2.10-0.8.2.1 |
随后修改kafka/config/server.properties文件:
1 | # 1. 将brokers 的 id设为唯一的值,这里就把编号作为它的值, 即1,2,3 |
创建logs文件夹:
1 | mkdir -p /home/hadoop_files/hadoop_logs/kafka |
之后使用 hadoop 用户启动 kafka 集群
先启动 zookeeper 集群,然后在 kafka 集群中的每个节点使用,下面是启动命令
1 | kafka-server-start.sh /usr/local/kafka_2.10-0.8.2.1/config/server.properties & |
6.2 测试
使用hadoop用户执行命令,
创建topic
1 | kafka-topics.sh --create --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --replication-factor 3 --partitions 1 --topic mykafka |
查看Topic
1 | kafka-topics.sh --list --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 |
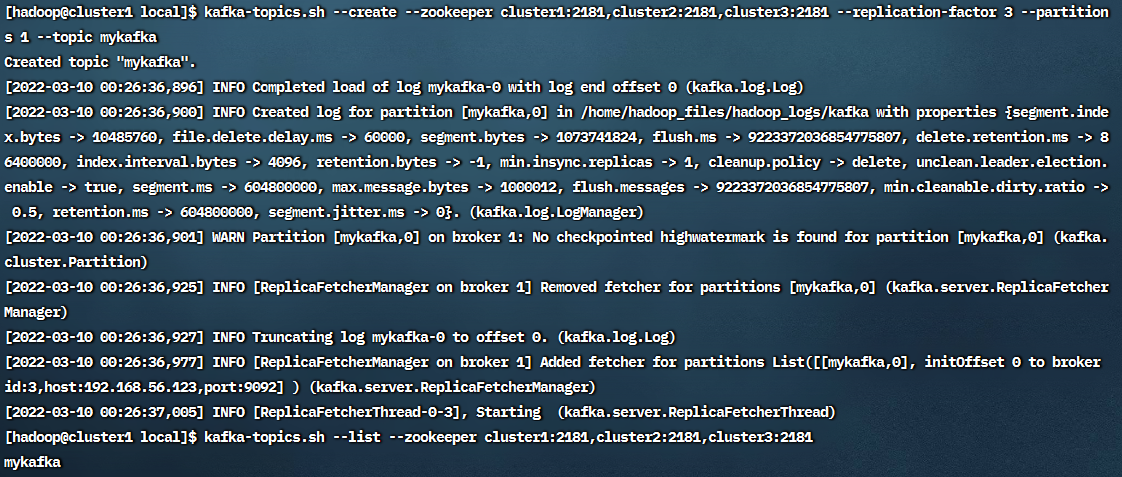
查看详细信息:
1 | kafka-topics.sh --describe --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 |

在cluster1上执行如下命令用来发送消息:
1 | kafka-console-producer.sh --broker-list localhost:9092 --topic mykafka |
在cluster2上执行如下命令用来接收消息:
1 | kafka-console-consumer.sh -zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --topic mykafka --from-beginning |
接着在cluster1上输入以下内容:
test
mycluster test
在cluster2上可以成功接收到相应信息

在每台机器上执行kafka-server-stop.sh命令关闭kafka,随后在每台机器上用screen命令新建窗口在后台跑kafka集群
1 | screen -S kafka |
随后使用Ctrl + A + D退出新建的screen,用jps命令看到Kafka进程在运行
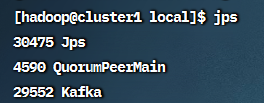
7. 安装Hadoop
7.1 安装
在启动Hadoop之前应先启动zookeeper
以下命令若无特殊说明,均使用 用户hadoop执行
将 hadoop-2.6.5.tar.gz 解压到 /usr/local/ 目录下
进入hadoop配置文件目录:
1 | cd /usr/local/hadoop-2.6.5/etc/hadoop |
修改hadoop-env.sh文件:
1 | export JAVA_HOME=/usr/local/jdk1.7.0_80 |
配置mapred-env.sh
1 | export HADOOP_MAPRED_PID_DIR=/home/hadoop_files |
配置core-site.xml文件
1 | <configuration> |
配置hdfs-site.xml文件
1 | <configuration> |
配置mapred-site.xml文件
1 | <configuration> |
配置yarn-site.xml文件
1 | <configuration> |
配置slaves文件
1 | cluster1 |
在所有节点上创建如下目录,即上述配置涉及的目录:
1 | mkdir -p /home/hadoop_files/hadoop_data/hadoop/namenode |
将cluster1的hadoop工作目录同步到集群其他节点:
1 | scp -r /usr/local/hadoop-2.6.5 cluster2:/usr/local/ |
之后保证工作目录所有者为hadoop用户
每台机器新建环境变量如下, 并使之生效:
1 | export HADOOP_HOME=/usr/local/hadoop-2.6.5 |
启动zookeeper集群后开始格式化:
在所有节点上启动journalnode
1 | hadoop-daemon.sh start journalnode |
使用jps可以看到journalnode进程
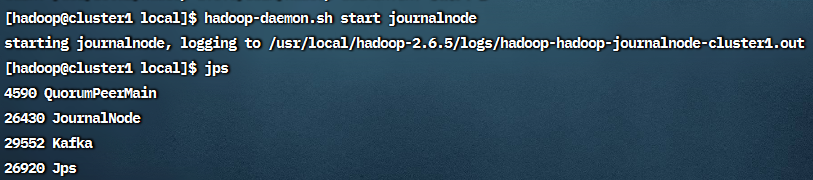
在cluster1上执行格式化HDFS命令:hdfs namenode -format,
之后使用hadoop-daemon.sh stop journalnode命令可在节点上关闭journalnode,
在cluster1上启用HDFS:start-dfs.sh,
可在cluster1上看到NameNode, DataNode, SecondaryNameNode;
在cluster2和cluster3上看到DataNode:
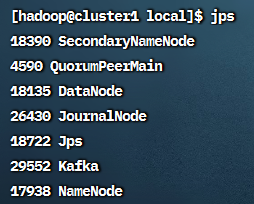
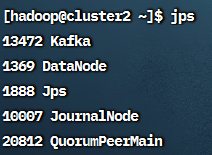
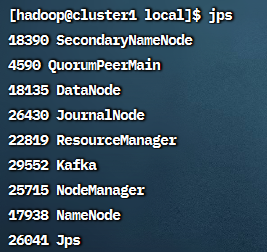
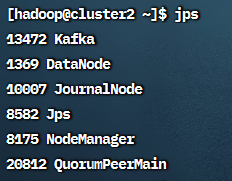
在cluster1上启用YARN:start-yarn.sh
启动后 cluster1 上使用 jps 可以看到NodeManager, ResourceManager,
cluster2 和 cluster3 上可以看到NodeManager:
7.2 测试
启动HDFS 后,可以在浏览器中,打开 http://192.168.56.121:50070,可以看到HDFS 的 web 界面:
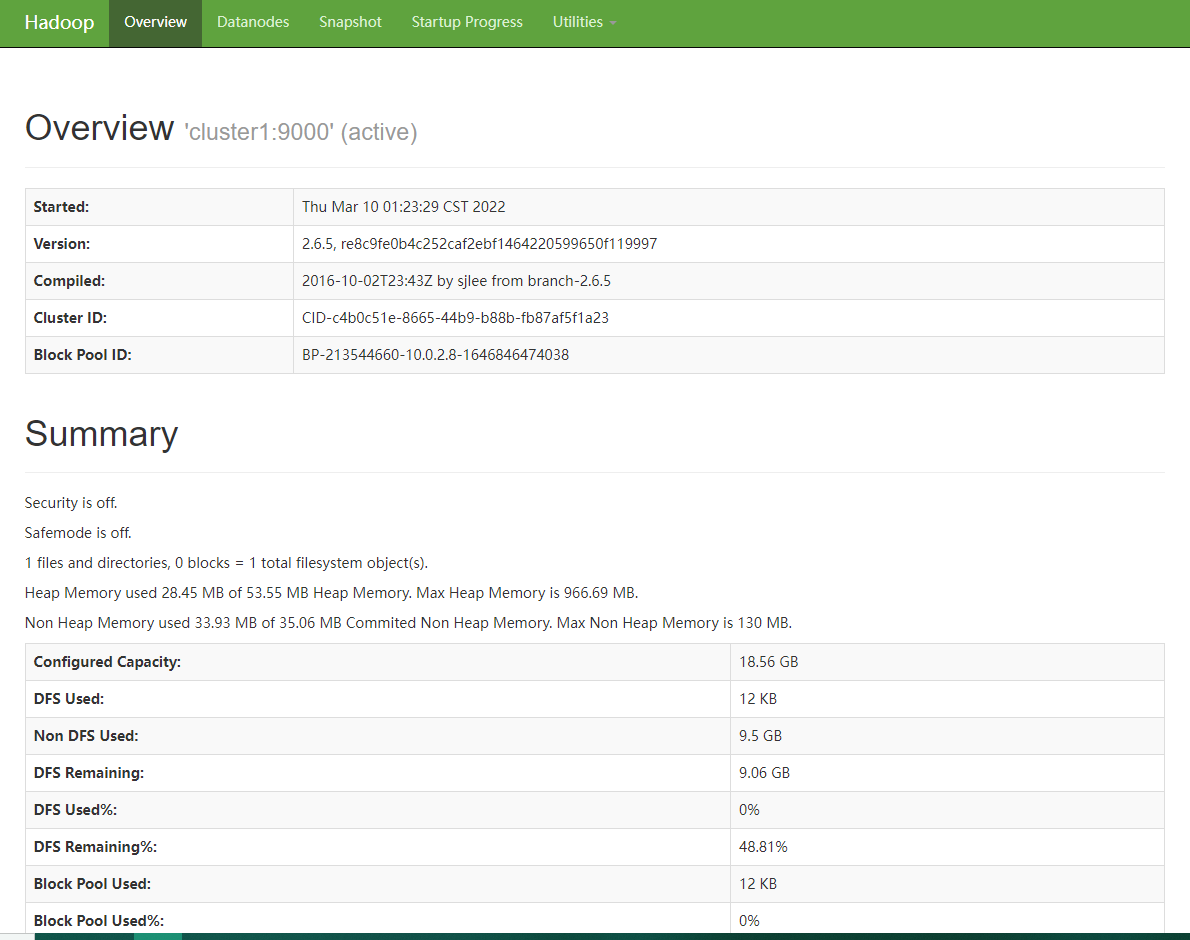
上图第一页是当前HDFS 的概况,里面显示了HDFS 的启动时间,版本等信息。

Datanodes页面显示了当前HDFS 中的可用节点。
启用YARN后可以通过访问http://192.168.56.121:8088查看YARN的web界面
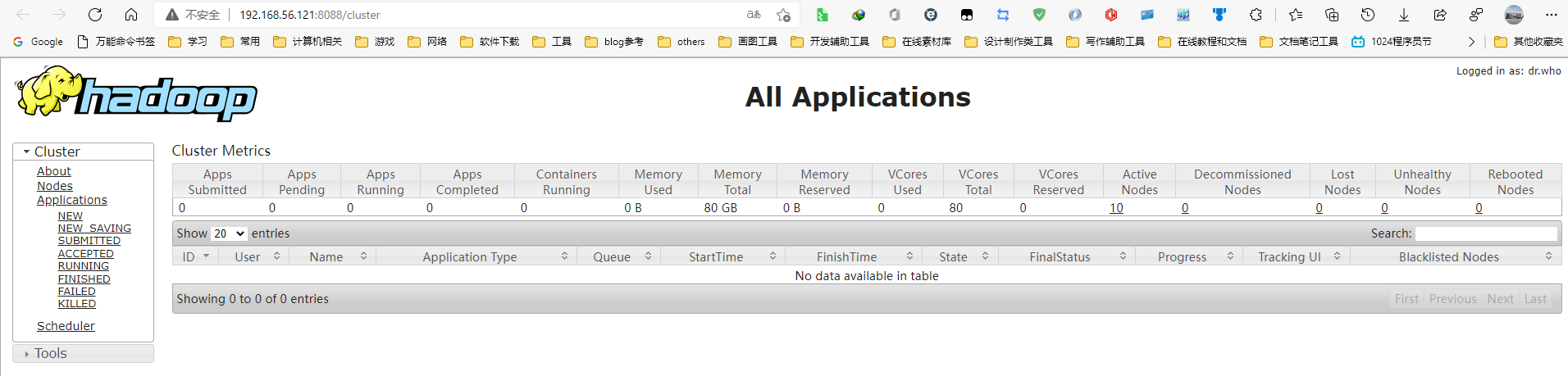
该页面展示了所有提交到 YARN 上的程序,点击左侧的Nodes 可以看到 YARN 的节点:
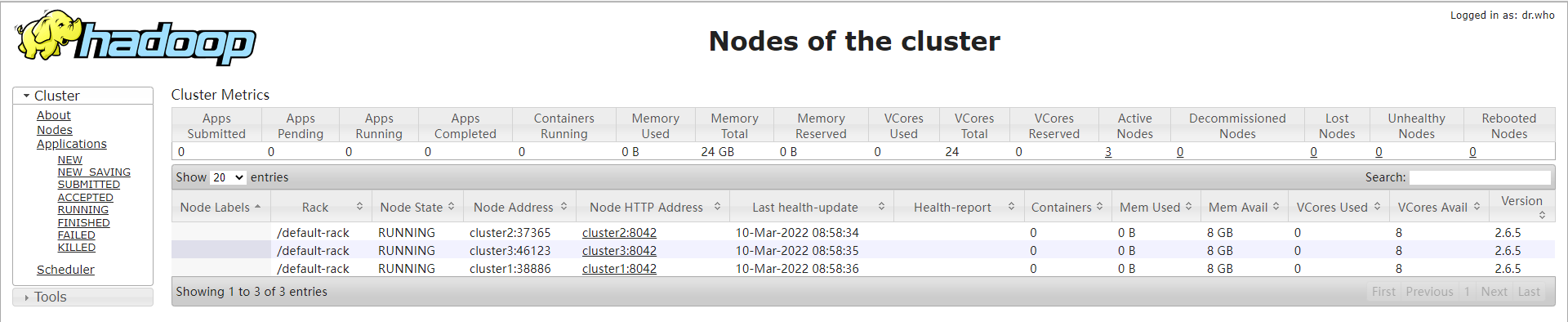
此处每个节点的可用内存 Mem Avail 为 8G,而我们的虚拟机每台内存只有 1.5G,由于没有在 yarn-site.xml 这个文件中对节点的可用内存进行配置出现了此问题,可以增加以下内容进行配置:
1 | <!-- 配置 nodemanager 可用的资源内存 --> |
进行命令行测试:
在cluster1上,
首先切换到hadoop用户目录:cd ~/
新建一个测试文件:Vi testfile
输入:
1 | 1 |
保存之后退出
在 HDFS 的根目录创建 test 目录: hdfs dfs -mkdir /test
查看HDFS 根目录的文件: hdfs dfs -ls /

将测试文件 testfile 上传至 HDFS 根目录下的 test 目录中: hdfs dfs -put testfile /test
在cluster2上,
首先切换到hadoop用户目录:cd ~/
查看HDFS 根目录: hdfs dfs -ls /

查看HDFS 根目录下的 test 目录,看到刚才在 cluster1 上上传的文件 testfile: hdfs dfs -ls /test

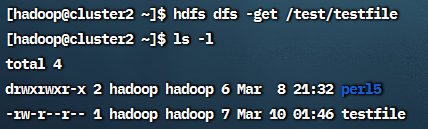
使用hdfs dfs -get /test/testfile将testfile下载到本地,
再查看当前目录下的文件可以发现testfile,
8. 安装HBase
8.1 安装
HBase 启动的先决条件是 zookeeper 和Hadoop 已经启动
在cluster1上, 将hbase-1.2.6-bin.tar.gz解压到/usr/local/目录下,随后修改/usr/local/hbase-1.2.6/conf/目录下的hbase-env.sh如下:
1 | # 配置 JDK 安装路径 |
配置hbase-site.xml
1 | <configuration> |
配置regionservers
1 | cluster1 |
删除hbase的slf4j-log4j12-1.7.5.jar, 解决hbase和hadoop的LSF4J冲突,
1 | mv /usr/local/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar /usr/local/hbase-1.2.6/lib/slf4j-log4j12-1.7.5.jar.bk |
将 hbase 工作目录同步到集群其它节点
1 | scp -r /usr/local/hbase-1.2.6/ cluster2:/usr/local/ |
在所有节点创建 hbase 的缓存文件目录和日志文件目录,并修改相应权限
1 | mkdir -p /home/hadoop_files/hadoop_tmp/hbase/tmp |
Hbase的环境变量如下:
1 | export HBASE_HOME=/usr/local/hbase-1.2.6 |
在cluster1上,先启动zookeeper, Hadoop的HDFS和YARN,然后才能启动HBase,
1 | start-dfs.sh |
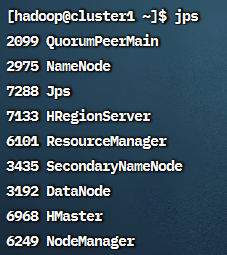
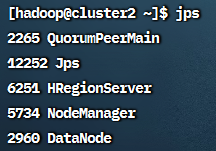
启动后在cluster1上使用jps可以看到HMaster和HRegionServer,
cluster2和cluster3上可以看到HRegionServer
8.2 测试
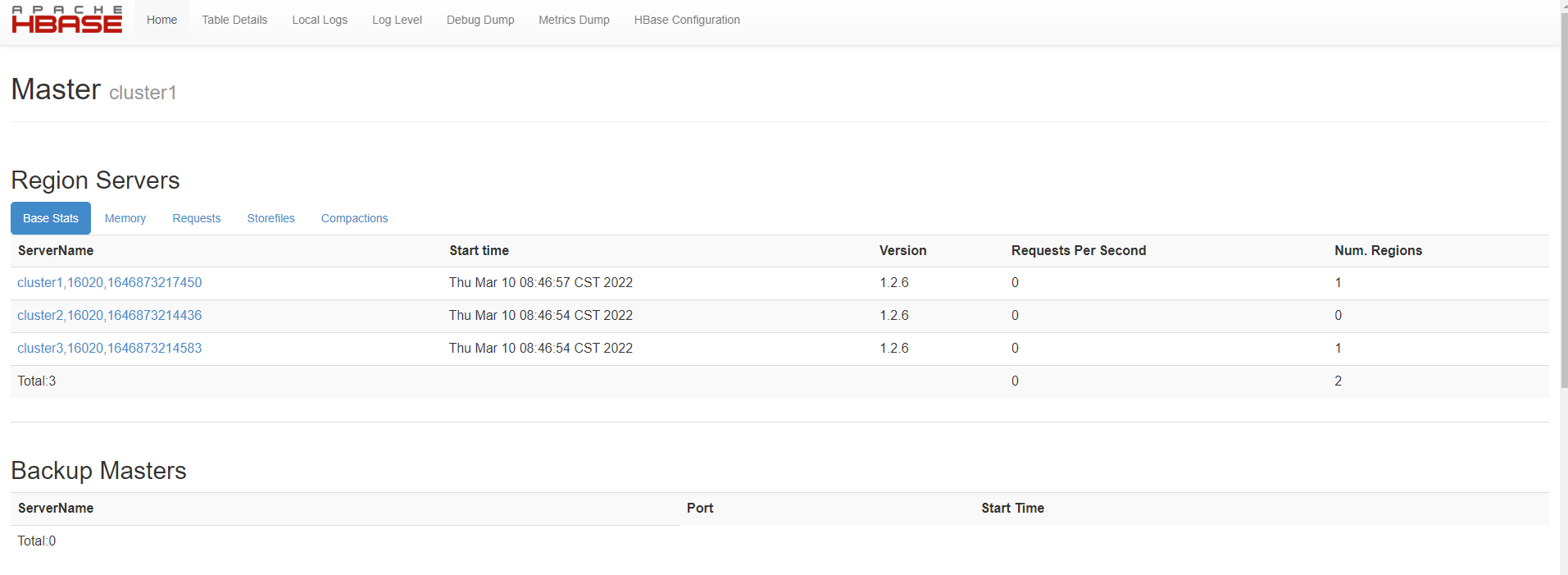
打开http://192.168.56.121:60010查看Hbase的web界面
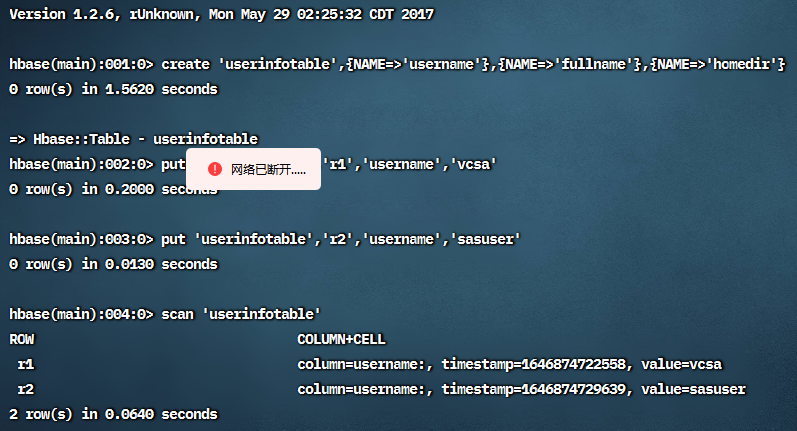
在cluster1上, 输入hbase shell 进入hbase shell.键入以下命令:
1 | create 'userinfotable',{NAME=>'username'},{NAME=>'fullname'},{NAME=>'homedir'} |
在 web 界面也可以看到刚才建立的表:
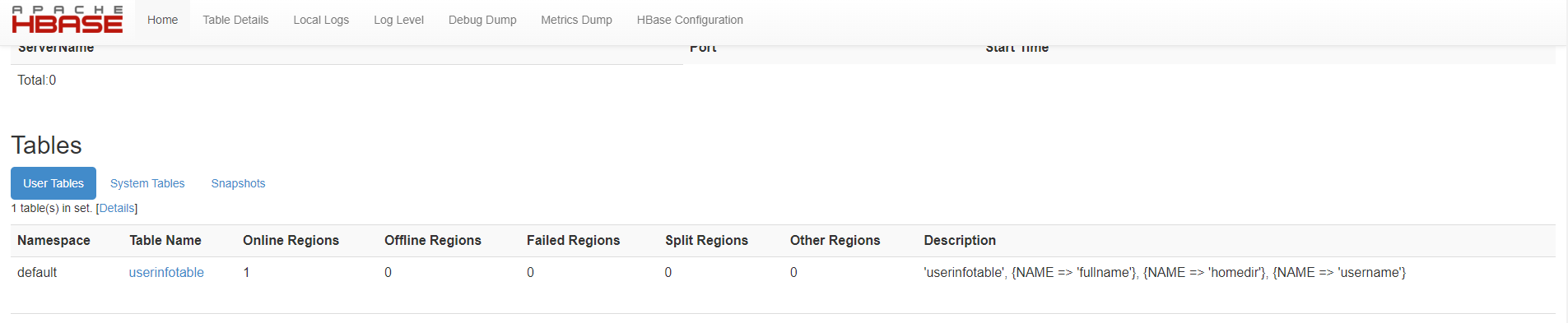
删除刚才建立的表:
1 | disable 'userinfotable' |
9. 安装Hive
9.1 安装
hive 能启动的先决条件是 MySQL 已经安装并配置完成,而且 HDFS 也要启动之后才能运行 hive
将apache-hive-1.1.0-bin.tar.gz上传到/usr/local并解压
添加环境变量:
1 | export HIVE_HOME=/usr/local/apache-hive-1.1.0-bin |
使用root用户登录MySQL:
1 | mysql -u root -p |
创建用户hive, 密码hive:
1 | mysql> GRANT USAGE ON *.* TO 'hive'@'%' IDENTIFIED BY 'hive' WITH GRANT OPTION; |
创建数据库hive
1 | mysql> create database hive; |
允许任意 ip 以hive 登陆数据库
1 | mysql> grant all on hive.* to hive@'%' identified by 'hive'; |
刷新权限并退出:
1 | mysql> flush privileges; |
验证hive用户是否正确创建:
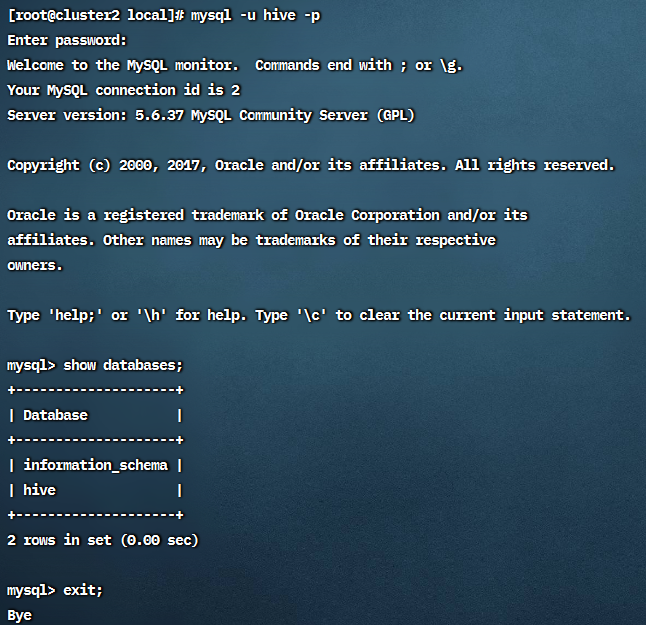
接下来修改hive-site.xml
将提供的hive-site.xml上传到apache-hive-1.1.0-bin/conf/目录下即可
将mysql-connector-java-5.1.43-bin.jar上传至 /usr/local/apache-hive-1.1.0-bin/lib/,
将jline-2.12.jar拷贝到/usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/
1 | cp /usr/local/apache-hive-1.1.0-bin/lib/jline-2.12.jar /usr/local/hadoop-2.6.5/share/hadoop/yarn/lib/ |
并将原先存在的jline-0.9.94.jar重命名为jline-0.9.94.jar.bak,
切换到hadoop用户执行:
1 | mkdir -p /home/hadoop_files/hadoop_tmp/hive/iotmp |
10. 安装Scala
在cluster1上将scala-2.10.6.tgz解压到/usr/local/目录下,
环境变量为:
1 | export SCALA_HOME=/usr/local/scala-2.10.6 |
刷新环境变量后用scala -version查看Scala版本验证安装:

复制到所有的服务器上
1 | scp -r /usr/local/scala-2.10.6 cluster2:/usr/local/ |
之后设置环境变量,并且修改文件夹权限:
1 | chown -R hadoop:hadoop /usr/local/scala-2.10.6 |
11. 安装Spark
11.1 安装
将spark-1.6.3-bin-hadoop2.6.tgz解压到/usr/local
环境变量为:
1 | export SPARK_HOME=/usr/local/spark-1.6.3-bin-hadoop2.6 |
在 conf 文件夹里面复制一份 template,改名为 spark-env.sh
1 | cp conf/spark-env.sh.template conf/spark-env.sh |
并在其中添加以下语句:
1 | export JAVA_HOME=/usr/local/jdk1.7.0_80 |
在conf下新建slaves文件,内容为:
1 | cluster1 |
将 hive 目录下 conf 文件夹中的 hive-site.xml 复制到 spark 的 conf 目录下,
将 hadoop/etc/hadoop 文件中的 hdfs-site.xml 和 core-site.xml 文件复制到 spark 的 conf 目录下,
将 conf 目录下的 spark-defaults.conf.template 复制一份,改名为 spark-default.conf ,并在最下面加上一行:spark.files file:///usr/local/spark-1.6.3-bin-hadoop2.6/conf/hdfs-site.xml,file:///usr/local/spark-1.6.3-binhadoop2.6/conf/core-site.xml
复制到所有的服务器上
1 | scp -r /usr/local/spark-1.6.3-bin-hadoop2.6 cluster2:/usr/local/ |
修改 spark 文件夹的权限(每个 spark 结点)
1 | chown -R hadoop:hadoop /usr/local/spark-1.6.3-bin-hadoop2.6 |
在cluster1上运行Spark
运行 spark 前需启动 hadoop 的HDFS 和 YARN
1 | start-master.sh |
关闭 Spark 的命令(cluster1 上)
2
stop-master.sh
11.2 测试
在 cluster1 上使用 jps 命令可以看到 Master 和 Worker,cluster2 和 3 上可以看到Worker,
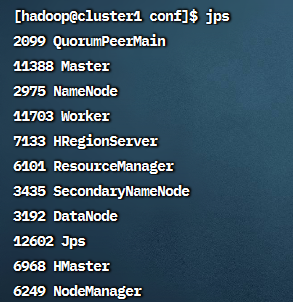
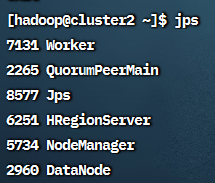
用浏览器访问 <http://192.168.56.121:8080 >可以看到 Spark 的web 界面,可以看到 3 个worker

12. 安装Storm
storm需要Python2.6以上版本
将apache-storm-1.1.1.tar.gz解压到/usr/local/下,
环境变量添加:
1 | export STORM_HOME=/usr/local/apache-storm-1.1.1 |
改一下权限
1 | chown -R hadoop:hadoop apache-storm-1.1.1 |
更改storm/conf/storm.yaml文件:
1 | storm.zookeeper.servers : |
新建tmp文件夹,改权限:
1 | mkdir -p /home/hadoop_files/hadoop_tmp/storm/tmp |
在cluster1上新建storm-master的虚拟窗口
1 | screen -S storm-master |
随后将窗口挂到后台
在cluster2,3上新建storm-supervisor的虚拟窗口
1 | screen -S storm-master |
随后将窗口挂到后台
在cluster1上新建storm-ui的虚拟窗口
1 | screen -S storm-ui |
随后将窗口挂到后台
在cluster1,2,3上新建storm-logviewer的虚拟窗口
1 | screen -S storm-logviewer |
随后将窗口挂到后台
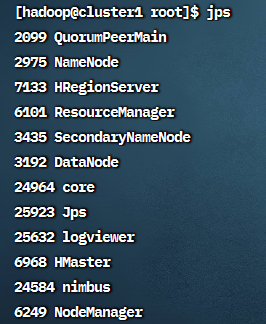
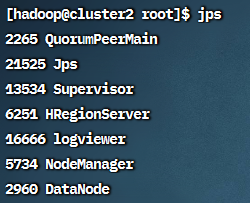
使用 jps 可以看到以下进程
cluster1:nimbus, core, logviewer
cluster2:Supervisor, logviewer
cluster3:Supervisor, logviewer
 微信扫码
微信扫码 支付宝扫码
支付宝扫码



