第1章 什么是对象?
第 1 章 什么是对象
“我们并未意识到惯用语言结构的强大之处。甚至可以毫不夸张地说,惯用语言通过语义反应机制奴役了我们。而一门语言所展现出的结构,潜移默化地影响着我们,并自动映射至我们所生活的世界。”
——Alfred Korzybski(1930)
计算机革命起源于一台机器,而编程语言就好比是那台机器。
然而计算机并不只是机器而已,它们还是扩展思维的工具(就像乔布斯喜欢说的一句话:计算机是“思维的自行车”),也是一种与众不同的表达媒介。结果就是,工具已经越来越不像机器,而是越来越像思维的一部分。
编程语言是用于创建应用程序的思维模式。语言本身可以从写作、绘画、雕塑、动画、电影制作等表达方式中获取灵感,而面向对象编程(Object-Oriented Programming, OOP)则是用计算机作为表达媒介的一种尝试。
许多人并不了解面向对象编程的思想框架,他们在进行编程时会感到举步维艰。因此,本章会简要的介绍一些面向对象编程的基础概念。还有一些人在接触相关机制之前可能无法理解这些概念,在看不到代码的情况下就会迷失。如果你属于后者并且渴望尽早接触到具体的语言特性,你完全可以跳过这一章,这样做并不会影响你学习编程语言或者写代码。不过,之后你可以再回到这里补充相关知识,这样有助于你理解对象如此重要的原因,以及如何利用对象做程序设计。
本章的内容假设你具有一定的编程基础,但不一定是C语言的经验。在全面学习本书之前,如果你需要补充一些基础的编程知识,可以在 On Java 8 网站下载多媒体课程“Thinking in C”来学习。
1.1 抽象的历程
所有编程语言都是一种抽象。甚至可以说,我们能够解决的问题的复杂程度直接取决于抽象的类型和质量。这里提到的“类型”的含义是“你要抽象的是什么”。比如,汇编语言是对计算机底层的一个极简化的抽象。还有许多所谓的命令式编程语言(比如 FORTRAN、BASIC 和 C 语言等)都是各自对汇编语言的抽象。虽然这些语言已经取得了长足的进步,但它们主要的抽象方式依然要求你根据计算机的结构而非问题的结构来思考。于是,程序员必须在机器模型(也叫作“解决方案空间”,即实际解决问题的方式,比如计算机)和实际解决的问题模型(也叫作“问题空间”,即问题实际存在之处,比如来源于某个业务)之间建立关联。建立这种关联需要耗费很大的精力,而且它是与编程语言无关的,这一切都导致程序难以编写且不易维护。
构建机器模型的一种代替方案是针对需要解决的问题构建问题模型。早期的一些编程语言(比如 LISP 和 APL)会采取特定的视角看待周遭问题(例如,“所有问题最终都可以用列表呈现”或者“所有问题都是算法问题”),Prolog 语言则会将所有问题都转换为决策链。这些语言要么是基于约束性的编程语言,要么是专门用来操作图形符号的编程语言。这些编程语言都能够出色地解决一些特定的问题,因为它们正是为此而生的。然而,一旦遇到它们专属领域以外的问题,它们就显得无能为力了。
面向对象编程则更进一步,它为程序员提供了一些能够呈现问题空间元素的工具。这种呈现方式具备足够的通用性,使得程序员不再局限于特定的问题。而这些问题空间中的元素及其解决方案空间中的具体呈现,我们称其为“对象”(需要注意的是,有些对象并不支持问题空间的类比)。其背后的理念则是,通过添加各种新的对象,程序可以将自己改编为一种描述问题的语言。于是,你阅读的既是解决方案的代码,也是表述问题的文字。这种灵活且强大的语言抽象能力是前所未有的。因此,面向对象编程描述问题的依据是实际的问题,而非用于执行解决方案的计算机。不过,它们之间依然存在联系,这是因为从某种意义上来说,对象也类似于一台小型计算机——每一个对象都具有状态,并且可以执行一些特定的操作。这一特点与现实中的事物极为相似,它们都具有各自的行为和特征。
SmallTalk 是历史上第一门获得成功的面向对象语言,并且为后续出现的 Java 语言提供了灵感。Alan Kay 总结了 SmallTalk 语言的 5 个基本特征,这些特征代表了纯粹的面向对象编程的方式。
- 万物皆对象。你可以把对象想象为一种神奇的变量,它可以存储数据,同时你可以“发出请求”,让它执行一些操作。对于你想要解决的问题中的任何元素,你都可以在程序中用对象来呈现(比如狗、建筑、服务等)。
- 一段程序实际上就是多个对象通过发送消息来通知彼此要干什么。当你向一个对象“发送消息”时,实际情况是你发送了一个请求去调用该对象的某个方法。
- 从内存角度而言,每一个对象都是由其他更为基础的对象组成的。换句话说,通过将现有的几个对象打包在一起,你就创建了一种新的对象。这种做法展现了对象的简单性,同时隐藏了程序的复杂性。
- 每一个对象都有类型。具体而言,每一个对象都是通过某个类生成的实例,这里说的“类”就(几乎)等同于“类型”。一个类最为显著的特性是“你可以发送什么消息给它”。
- 同一类型的对象可以接收相同的消息。稍后你就会意识到这句话的丰富含义。举例来说,因为一个“圆形”对象同样也是一个“形状”对象,所以“圆形”也可以接收“形状”类型的消息。这就意味着,你为“形状”对象编写的代码自然可以适用于任何的“形状”子类对象。这种可替换性是面向对象编程的一个基石。
Grady Booch 对对象做了一种更为简洁的描述:
对象具有状态、行为及标识。
这意味着对象可以拥有属于自己的内部数据(赋予其状态)、方法(用于产生行为),同时每一个对象都有别于其他对象。也就是说,每一个对象在内存中都有唯一的地址。$^1$
$^1$这个说法实际上不太全面。这是因为对象可以保存在不同的机器或内存地址中,甚至还可以保存在磁盘上。在上述情况中,对象的标识(identity)就需要用其他方式而非内存地址来表示。
1.2 对象具有接口
亚里士多德可能是第一个仔细研究类型这一概念的人,他曾经提出过“鱼的类别和鸟的类别”。所有的对象,哪怕是相当独特的对象,都能够被归为某一类,并且同一类对象拥有一些共同的行为和特征。作为有史以来第一门面向对象编程语言,Simula-67 引入了上述的“类别”概念,并且允许通过关键字 class 在程序中创建新的类型。
Simula 语言恰如其名,其诞生的目的是用于“模拟”,比如模拟经典的“银行出纳问题”。这个问题的元素包括大量的出纳员、顾客、账户、交易,以及各种货币单位等,这些都是“对象”。而那些状态不同但结构相同的对象汇聚在一起,就变成了“同一类对象”(classes of objects),这就是关键字 class的由来。
创建抽象数据类型(即“类”)是面向对象编程的一个基本概念。抽象数据类型的工作原理和内置类型几乎一样:你可以创建某种类型的变量(在面向对象领域,这些变量叫作“对象”或“实例”),随后你就可以操作这些变量(叫作“发送消息”或“发送请求”,即你发送指令给对象,然后对象自行决定怎么处理)。同一类型的所有成员(或元素)都具有一些共性,比如:每一个账户都有余额,每一位出纳员都能处理存款业务。同时,每一个成员都具有自己的专属状态,比如:每一个账户的余额都是不同的,每一位出纳员都有名字。因此,对于所有这些成员,包括每一位出纳员、每一位顾客、每一个账户,以及每一笔交易等,我们都能够在程序中用一个唯一的实体来表示。这种实体就是对象,同时每一个对象所归属的类决定了对象具有何种行为特征。
虽然我们在面向对象编程中会创建新的数据类型,但实际上所有面向对象编程语言都会使用 class 这个关键字。所以当你看到“类型”(type)这个词的时候,请第一时间想到“类”(class),反之亦然。$^2$
$^2$有时候我们会将两者加以区分,将类型(type)定义为接口,而类(class)则是接口的具体实现。
因为类描述了一系列具有相同特征(即数据元素)和行为(即功能方法)的对象,而即便是浮点数这种内置数据类型也具有一系列的行为和特征,所以类其实就是数据类型。抽象数据类型和内置数据类型的区别是,程序员可以通过定义一个新的类来解决问题,而非受限于已有的数据类型。这些已有的数据类型其设计本意是为了呈现机器内的存储单元,你可以根据实际的需求创建新的数据类型,同时扩展编程语言的能力。此外,编程系统对于新的类十分友好,比如也会为新的类提供类型检查等功能,就像对待内置数据类型一样。
面向对象编程的作用并不局限于模拟。无论你是否同意“任何程序都是对系统的一种模拟”,面向对象编程技巧都可以帮你将众多复杂的问题简化。
一旦创建了一个类,就可以用它创建任意多个对象,然后在操作这些对象时,可以把它们视为存在于问题空间的元素。实话实说,面向对象编程的一大挑战就是,如何在问题空间的元素和解决方案空间的对象之间建立一对一的关联。
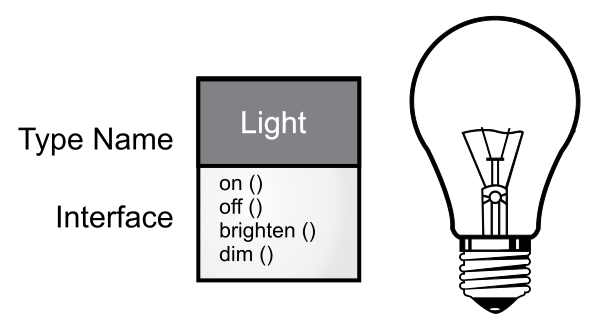
那么,如何能让一个对象真正发挥其作用呢?答案是向对象发送请求,比如让它完成一次交易、在屏幕上画个图形或者打开一个开关等。对象能够接受什么请求,是由它的“接口”(interface)决定的,而对象所归属的类定义了这些接口。接下来以电灯泡为例,如下图所示。
插图翻译:
Type Name:类型名
Interface:接口
1 | Light lt = new Light(); |
图中的接口定义了你能够向这个对象发送的请求。此外,也必然存在一些代码用于响应这些请求。这些代码再加上隐藏的数据,叫作“实现”(implementation)。对于每一个请求,类都有一个方法与之对应。当你向一个对象发送特定的请求时,对应的方法就会被调用。我们通常会这样描述该过程:向对象“发送消息”(即发出请求),然后由对象决定如何处理(即运行对应的代码)。
在上面的例子中,类的名字是 Light,Light 所生成的对象的名字是 lt,我们能够对 Light 对象发出的请求是开灯(on())、关灯(off())、灯光变亮(brighten())以及灯光变暗(dim())。通过定义一个“引用”即 lt,以及用 new 关键字生成一个新对象,我们就创建了一个 Light 对象。此外,如果你需要向对象发送消息,可以用一个英文句号(.)将对象名和请求(即方法)连接起来。如果我们只是使用内置类,那么基本上关于对象编程的内容就是以上了。
此外,前面的图示遵循了统一建模语言(Unified Modeling Language, UML)的规范。在此规范下,每一个类都表示为一个方块,方块头部是类名,方块中部是你想要描述的数据成员,而方法(即该对象的函数,负责接收发送至对象的请求)则位居方块的底部。通常,UML 图中只会展示类名和公有方法,所以在上图的例子中,方块中部的内容并没有展示出来。如果你只关心类名,方块底部的内容也可以不显示。
1.3 对象可以提供服务
当你开发一个面向对象程序或理解其设计时,一个上佳的方法是将对象想象成“服务提供者”。你的程序本身也是为用户提供服务的,它通过使用其他对象提供的服务来做到这一点。所以,你的任务是创建(更好的情况是,从已有的库中找到)一些提供对应服务以解决问题的对象。
可以先从一个问题开始:“如果我能从魔术帽里变出一些对象,究竟什么对象才能解决我的问题呢?”比如,你要创建一个记账系统,于是你可能会需要一些预设的输入页面对象、负责计算的对象,以及连接各种打印机以打印支票和发票的对象。其中有些对象也许已经存在,那么其他不存在的对象应该是什么样的呢?它们应该提供哪些服务,同时它们还需要哪些其他对象的支持呢?如果继续深入的话,到了最后,你要么会说“编写这个对象的代码应该很简单”,要么会说“我确信这个对象早已存在”。这种将问题拆解为一系列对象的方法确实行之有效。
把对象视为服务提供商还有一个额外的好处,即提升了对象的聚合程度。说到这里,就需要提到软件设计领域中一个体现基础品质的术语——“高内聚性”(high cohesion),这指的是设计的组件(比如对象、方法或者对象库等)无论从哪个方面看都整合得很好。人们在设计对象时很容易犯的一个错误就是为对象添加太多的功能。例如,在一个打印支票的程序里,你一开始可能会认为需要一个既能排版又能打印的对象。然后,你发现这些功能对于一个对象而言太多了,其实你需要 3 个或者更多对象来负责这些功能。比如,一个对象包含了所有可能的打印布局,通过查找它可以知道如何打印一张支票。另一个或一组对象则作为通用打印接口,负责连接所有不同型号的打印机(但不负责记账,也许你需要购买该功能而非自行创建)。还有一个对象负责整合前两个对象提供的服务以完成打印任务。因此,每一个对象都提供了一种配套服务。在面向对象领域,出色的设计往往意味着一个对象只做好一件事,绝不贪多。这条原则不只适用于那些从外部购买的对象(比如打印接口对象),也适用于那些可复用的对象(比如支票排版对象)。
把对象视为服务提供商,不仅对你设计对象的过程有所帮助,也有利于他人阅读你的代码或复用这些对象。换句话说,如果别人因为对象提供的服务而认识到它的价值,那么他就会更加轻松地在自己的设计中使用这个对象。
1.4 隐藏的实现
我们可以把程序员划分为两大阵营:一是“类的创建者”(负责创建新数据类型的人),二是“客户程序员” $^3$(在自己的应用程序里使用现有数据类型的人)。客户程序员的诉求是收集一个装满了各种类的工具箱,以便自己能够快速开发应用程序。而类的创建者则负责在创建新的类时,只暴露必要的接口给客户程序员,同时隐藏其他所有不必要的信息。为什么要这么做呢?这是因为,如果这些信息对于客户程序员而言是不可见的,那么类的创建者就可以任意修改隐藏的信息,而无须担心对其他任何人造成影响。隐藏的代码通常代表着一个对象内部脆弱的部分,如果轻易暴露给粗心或经验不足的客户程序员,就可能在顷刻之间被破坏殆尽。所以,隐藏代码的具体实现可以有效减少程序 bug。
$^3$关于这个称谓,我需要感谢我的老朋友 Scott Meyers。
所有的关系都需要被相关各方一致遵守的边界。当你创建了一个库,那么你就和使用它的客户程序员建立了一种关系。该客户程序员通过使用你的代码来构建一个应用,也可能将其用于构建成一个更大的库。如果一个类的所有成员都对所有人可见,那么客户程序员就可以恣意妄为,而且我们无法强制他遵守规定。也许你的预期是客户程序员不会直接操作任何类的成员,但是如果没有访问控制的话,你就无法实现这一点,因为所有的一切都暴露在对方面前了。
所以我们设置访问控制的首要原因就是防止客户程序员接触到他们本不该触碰的内容,即那些用于数据类型内部运转的代码,而非那些用于解决特定问题的接口部分。这种做法实际上为客户程序员提供了一种服务,因为他们很容易就可以知道哪些信息对他们来说是重要的,哪些则是无须关心的(请注意这也是一个富有哲理的决策。比如有些编程语言认为,如果程序员希望访问底层信息,就应该允许他们访问)。
设置访问控制的第二个原因则是,让类库的设计者在改变类的内部工作机制时,不用担心影响到使用该类的客户程序员。例如,你为了开发方便而创建了一个简单的类,之后你发现必须重写这个类以提升它的运行效率。如果接口部分和实现部分已经被分离和保护起来了,那么你就可以轻松地重写它。
Java 提供了 3 个显式关键字来设置这种访问控制,即 public、private 以及 protected。这些关键字叫作“访问修饰符”(access specifier),它们决定了谁可以使用修饰符之后的内容。public表示定义的内容可以被所有人访问。private 表示定义的内容只能被类的创建者通过该类自身的方法访问,而其他任何人都无法访问。所以,private 就是一道横亘在你和客户程序员之间的高墙,任何人从外部访问 private 数据都会得到一个编译时报错。最后,protected 类似于 private,两者的区别是继承的子类可以访问 protected 成员,但不可以访问 private 成员。至于继承的概念,本书稍后会讲述。
如果你不使用上述任意一种访问修饰符,Java 会提供一种“默认”访问权限,通常叫作“包访问”(package access),意思是一个类可以访问同一个包(库组件)里的其他类,但是如果从外部访问这些类的话,它们就像 private 内容一样不可访问了。
1.5 复用实现
如果一个类经过了充分测试,其代码就应该是有效且可复用的(理想情况)。不过,要实现这种复用性并不像想象的那么简单。创建可复用的对象设计需要大量的经验和洞见。然而,一旦你拥有了可复用的设计,不复用就可惜了。代码复用是我们使用面向对象编程的理由之一。
复用一个类最简单的方法是直接使用这个类所生成的对象,不过你也可以把这个对象放到另一个新类里面。新创建的类可以由任意数量和类型的对象组成,也可以任意组合这些对象,以满足想要的功能。因为利用已有的类组合成一个新的类,所以这个概念叫作“组合”(composition)。如果组合是动态的,通常叫作“聚合”(aggregation)。组合通常代表一种“有”(has-a)的关系,比如“汽车有发动机”(见下图)。
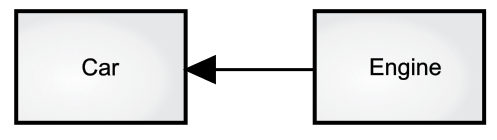
图中文字:
Car 汽车
Engine 发动机
上图中用箭头表示了一辆汽车的组合关系。而我习惯用一种更简单的方式,即一条没有箭头的直线来表达两者之间的关联。$^4$
$^4$这些信息对于大多数图来说已经足够了,也无须特别说明使用的是聚合还是组合。
组合为我们提供了极大的灵活性。这些在你的类内部创建的对象通常具有 private 属性,所以其他使用这个类的客户程序员无法访问它们。这也意味着,就算我们修改了这些内部对象,也不会影响外部已有的代码。此外,你还可以在运行时改变这些内部对象,从而动态调整程序的行为。下一节要讲述的继承机制则不具备这种灵活性,因为编译器对使用继承创建的类设置了一些编译时的限制。
继承常被视为面向对象编程的重中之重,因此容易给新手程序员留下这样的印象:处处都应该使用继承。而实际上,这种全盘继承的做法会导致设计变得十分别扭和过于复杂。所以相比之下,在创建新类时应该首先考虑组合,因为使用组合更为简单灵活,设计也更为清晰简洁。一旦你拥有了足够的经验,何时使用继承就会变得非常清晰了。
1.6 继承
对象本身的理念是提供一种便捷的工具。对象可以根据定义的概念来封装数据和功能,从而展现给人们对应的问题空间的概念,而不是强迫程序员操作机器底层。在编程语言里,这些基础概念通过关键字 class 得以呈现。
然而,当我们大费周折才创建了一个类之后,如果不得不再创建一个与之前功能极为相近的类,这种滋味一定不太好受。如果我们能够复制现有的类,并且在该复制类的基础上再做一些增补的话,那就太妙了。实际上,这就是继承给我们带来的好处,除了一点:如果最初的类(叫作“基类”“超类”或“父类”)发生了变化,那么被修改的“复制”类(叫作“衍生类”“继承类”或“子类”)同样会发生变化(见下图)。
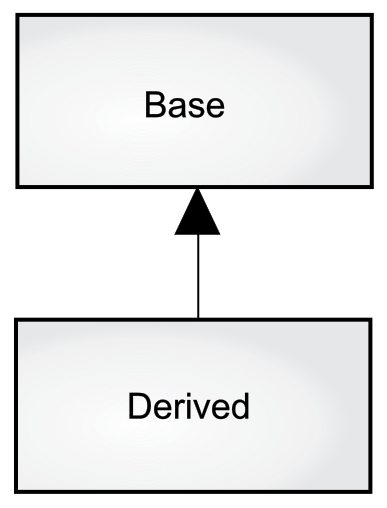
图字翻译:
Base 基类
Derived 子类
上图中的箭头从子类指向其基类。之后你将看到,子类通常会有多个。
一个类呈现的内容不只是对象能做什么、不能做什么,它还可以关联其他的类。两个类可以拥有相同的行为和特征,但一个类可以比另一个类拥有更多的特征,以及处理更多的消息(或者用不同的方式处理消息)。继承通过基类和子类的概念来表述这种相似性,即基类拥有的所有特征和行为都可以与子类共享。也就是说,你可以通过基类呈现核心思想,从基类所派生出的众多子类则为其核心思想提供了不同的实现方式。
举个例子。一个垃圾收集器需要对垃圾进行分类。我们创建的基类是“垃圾”,具体的每一件垃圾都有各自不同的重量、价值,并且可以被切碎、溶解或者分解等。于是,更为具体的垃圾子类就出现了,并且带有额外的特征(比如,一个瓶子有颜色,一块金属有磁性等)和行为(比如你可以压扁一个铝罐)。此外,有些行为还可以产生不同的效果(比如纸质垃圾的价值取决于它的类型和状态)。通过继承,我们创建了一种“类型层次”(type hierarchy)以表述那些需要根据具体类型来解决的问题。
还有一个常见的例子是形状,你可能在计算机辅助设计系统或模拟游戏中碰过到。具体来说,基类就是“形状”(Shape),而每一个具体的形状都具有大小、颜色、位置等信息,并且可以被绘制(draw())、清除(erase())、移动(move())、着色(getColor 或 setColor)等。接下来,基类 Shape 可以派生出特定类型的形状,比如圆形(Circle)、矩形(Square)、三角形(Triangle)等,每一个具体形状都可以拥有额外的行为和特征,比如某些形状可以被翻转(见下图)。有些行为背后的逻辑是不同的,比如计算不同形状的面积的方法就各不相同。所以,类型层次既体现了不同类之间的相似性,又展现了它们之间的差异。
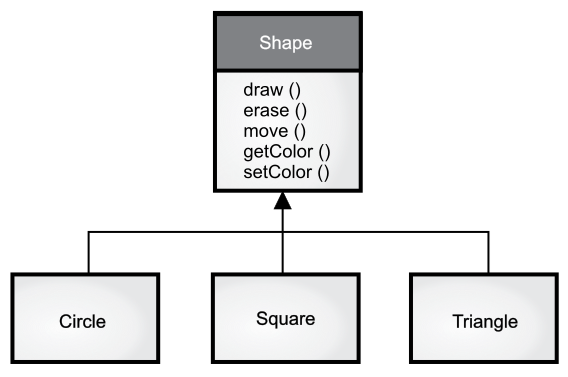
问题和解决方案都使用相同的表达方式是非常有用的,因为这样就不再需要一个中间模型将问题翻译为解决方案。在面向对象领域,类型层次是该模型的一个重要特征,它让你可以方便地从现实世界中的系统转换到代码世界的系统。不过现实情况是,有些人由于习惯了复杂的解决方案,因此对于面向对象的简约性反而会有些不适应。
继承已有的类将产生新类。这个新的子类不但会继承其基类的所有成员(虽然 private 成员是隐藏且不可访问的),而且更重要的是,子类也会继承基类的接口。也就是说,所有基类对象能够接收的消息,子类对象也一样能够接收。我们可以通过一个类所接收的消息来确定其类型,所以从这一点来说,子类和基类拥有相同的类型。引用之前的例子,就是“圆形是一个形状”。所以,掌握这种通过继承表现出来的类型相同的特性,是理解面向对象编程的基础方法之一。
既然基类和子类拥有相同的基础接口,就必然存在接口的具体实现。这意味着,当一个对象接收到特定的消息时,就会执行对应的代码。如果你继承了一个类并且不做任何修改的话,这个基类的方法就会原封不动地被子类所继承。也就是说,子类的对象不但和基类具有相同的类型,而且不出所料的是,它们的行为也是相同的。
有两种方法可以区分子类和基类。第一种方法非常简单直接:为子类添加新的方法(见下图)。因为这些方法并非来自基类,所以背后的逻辑可能是,基类的行为和你的预期不符,于是你添加了新的方法以满足自己的需求。有时候,继承的这种基础用法能够完美地解决你面临的问题。不过,你需要慎重考虑是否基类也需要这些新的方法(还有一个替代方案是考虑使用“组合”)。在面向对象编程领域里,这种对设计进行发现和迭代的情况非常普遍。
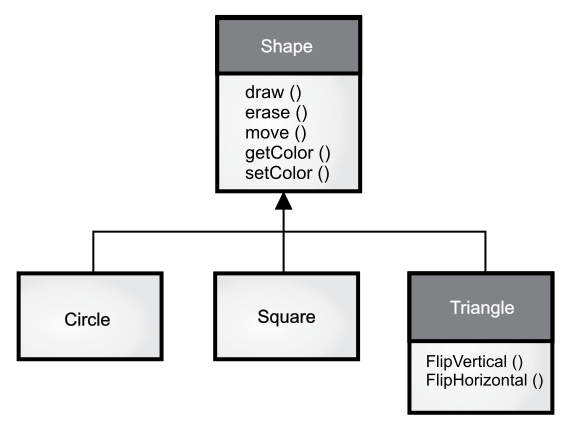
虽然有时候继承意味着需要为子类添加新的方法[Java 尤其如此,其用于继承的关键字就是“扩展”(extends)],但这不是必需的。还有一种让新类产生差异化的方法更为重要,即修改基类已有方法的行为,我们称之为“重写”该方法(见下图)。
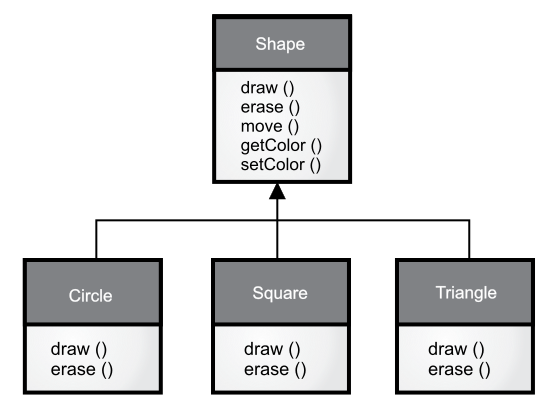
如果想要重写一个方法,你可以在子类中对其进行重新定义。也就是说,你的预期是“我想通过相同的接口调用该方法,但是我希望它可以在新的类中实现不同的效果”。
is-a关系与is-like-a关系
继承机制存在一个有待商榷的问题:只应该重写基类中定义的方法吗?(并且不能添加基类中不存在的新方法)如果是,就意味着子类和基类的类型是完全相同的,因为它们的接口一模一样。结果就是,你可以直接用子类的对象代替基类的对象。这种纯替换关系通常叫作“替换原则” $^5$。从某种意义上说,这是一种理想的继承方式。这种情况下基类和子类之间的关系通常叫作“is-a”关系,意思是“A 是 B”,比如“圆形是一个形状”。甚至有一种测试是否是继承关系的方法是,判断你的类之间是否满足这种“is-a”关系。
$^5$也叫作“里氏替换原则”(Liskov Substitution Principle),这一理论最初由 Barbara Liskov 提出。
有时候,你会为子类的接口添加新的内容,从而扩展了原有的接口。在这种情况下,子类的对象依然可以代替基类的对象,但是这种代替方案并不完美,因为不能通过基类的接口获取子类的新方法。我将这种关系描述为“is-like-a”关系(这是我自创的词),意思是“A 像 B”,即子类在拥有基类接口的同时,也拥有一些新的接口,所以不能说两者是完全等同的。以空调为例,假设你的房间里已经安装了空调,也就是拥有能够降低温度的接口。现在发挥一下想象力,万一空调坏了,你还可以用热泵作为替代品,因为热泵既可以制冷也可以制热(见下图)。在这种情况下,热泵“就像是”空调,只不过热泵能做的事情更多而已。此外,由于设计房间的温度控制系统时,功能仅限于制冷,所以系统和新对象交互时也只有制冷的功能。虽然新对象的接口有所扩展,但现有系统也只能识别原有的接口。
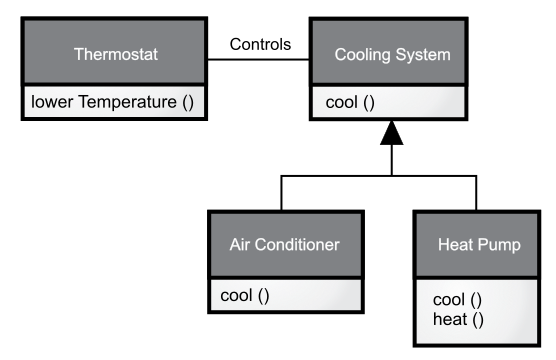
图字翻译
Thermostat 恒温器
Controls 控制
Cooling System 制冷系统
Air conditioner 空调
Heat Pump 热泵
观察上图你就能知道,基类“制冷系统”通用性并不高,最好可以将其改名为“温度调节系统”,使其同时包含制热功能。这样一来,之前提及的替换原则就可以派上用场了。不过话说回来,这张图也反映了真实世界中的设计方式。
当你充分理解了替换原则之后,可能会认为这种纯替换方式才是唯一正确的方式。如果你的设计能够应用纯替换原则,那就太棒了。然而实际情况是,你会发现经常需要为子类的接口添加新方法。只要稍加观察,就很容易分辨出这两种情况的应用场合。
1.7 多态
在编程中涉及类型层次时,我们通常会将一个对象视为其基类的一个实例,而不是对象实际的类。这种方式可以让你在编写代码时不依赖于具体的类。在形状的例子中,方法都是作用于通用的形状,而不需要关心该形状具体是圆形、矩形、三角形,还是一个没有明确定义的形状。因为所有的形状都可以被绘制、清除、移动,所以当这些方法发送消息至对象的时候,就无须关注对象是如何处理这条消息的。
当我们添加新的类时,这些代码是不受影响的,添加新的类可以扩展面向对象程序的能力,从而能够处理一些新的情况。比如,你为基类“形状”创建了一个子类“五边形”,并且不改变那些基于通用形状的方法。这种通过派生子类就可以轻松扩展程序设计的能力,是封装变化的一种基础方式。这种方式在改善设计的同时,也降低了软件维护的成本。
当你尝试用派生的子类替代通用基类(比如,把圆形当作形状,把自行车当作交通工具,把鸬鹚当作鸟等)时会发现一个问题,即调用方法来绘制这个通用的形状、驾驶这辆通用的交通工具或者让这只鸟飞翔时,编译器并不知道在编译时具体需要执行哪一段代码。那么重点来了,当消息被发送时,程序员并不关心具体执行的是哪一段代码。也就是说,当负责绘制的方法应用于圆形、矩形或者三角形时,这些对象将能够根据其类型执行对应的正确代码。
如果你并不关心具体执行的是哪一段代码,那么当你添加新的子类时,即使不对其基类的代码做任何修改,该子类实际执行的代码可能也会有所不同。但如果编译器无法得知应该具体执行哪一段代码,它会怎么做呢?比如下图中的 BirdController 对象,它可以和通用的 Bird 对象协同工作,同时它并不知道这些对象具体是什么类型的鸟。对于 BirdController 来说,这种方式非常方便,因为它无须额外编写代码来确定这些对象的具体类型和行为。那么问题来了,当一个 Bird 对象的 move() 方法被调用时,如果我们并不清楚其具体的类型,该如何确保最终执行的是符合预期的正确行为呢[比如 Goose 对象执行的是行走、飞翔或游泳,Penguin 对象则是移动或游泳;见下图]?
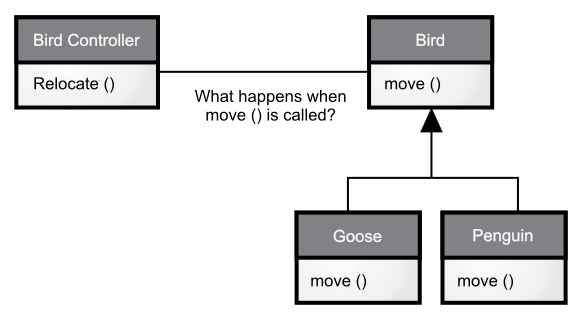
图字翻译
What happens when move() is called?
如果move()被调用,究竟会发生什么呢?
答案来自继承机制的一种重要技巧:编译器并非通过传统方式来调用方法。对于非面向对象编译器而言,其生成的函数调用会触发“前期绑定”(early binding),这是一个你可能从来都没听说过的词,因为你从未考虑过使用这种方式。前期绑定意味着编译器会生成对一个具体方法名的调用,该方法名决定了被执行代码的绝对地址。但是对于继承而言,程序直到运行时才能明确代码的地址,所以就需要引入其他可行的方案以确保消息可以顺利发送至对象。
为了解决上面提及的问题,面向对象语言使用的机制是“后期绑定”(late binding)。也就是说,当你向某个对象发送消息时,直到运行时才会确定哪一段代码会被调用。编译器会确保被调用的方法是真实存在的,并对该方法的参数和返回值进行类型检查,但是它并不知道具体执行的是哪一段代码。
为了实现后期绑定,Java 使用了一些极为特殊的代码以代替直接的函数调用,这段代码使用存储在对象中的信息来计算方法体的地址(第 9 章会详细地描述这个过程)。其结果就是,在这些特殊代码的作用下,每一个对象会有不同的表现。通俗地讲,当你向一个对象发送消息时,该对象自己会找到解决之道。
顺便一提,在某些编程语言里,你必须显式地为方法赋予这种后期绑定特性。比如,C++ 使用 virtual 关键字来达到此目的。在这些编程语言中,方法并不默认具备动态绑定特性。不过,Java 默认具备动态绑定特性,所以你无须借助于其他关键字或代码来实现多态。
我们再来看一下形状的例子。之前的图中展示了一些形状的类(这些类都基于统一的接口),为了更好地描述多态,我们编写一小段只关注基类而不关注具体子类的代码。由于这段代码不关注类的细节,因此非常简单易懂。此外,如果我们通过继承添加了一个新的子类“六边形”,我们的代码仍然适用于这个新的 Shape 类,就像适用于其他已有子类一样。因此可以说,这段程序具备扩展性。
如果你用 Java 编写一个方法(你马上就会学到具体应该怎么做):
1 | void doSomething(Shape shape) { |
这个方法适用于任何 Shape 对象,所以它不关心进行绘制和清除的对象具体是什么类型。如果程序的其他地方调用了 doSomething() 方法,比如:
1 | Circle circle = new Circle(); |
不管对象具体属于哪个类,doSomething() 方法都可以正常运行。
简直妙不可言。我们再看这一行代码:
1 | doSomething(circle); |
在这段代码里,原本我们需要传递一个 Shape 对象作为参数,而实际传递的参数却是一个 Circle 类的对象。因为 Circle 也是一个 Shape,所以 doSomething() 也可以接受 Circle。也就是说,doSomething() 发送给 Shape 对象的任何消息也可以发送给 Circle 对象。这是一种非常安全且逻辑清晰的做法。
这种将子类视为基类的过程叫作“向上转型”(upcasting)。这里的“转型”指的是转变对象的类型,而“向上”沿用的是继承图的常规构图,即基类位于图的顶部,数个子类则扇形分布于下方。因此,转变为基类在继承图中的路径就是一路向上,也就叫作“向上转型”。
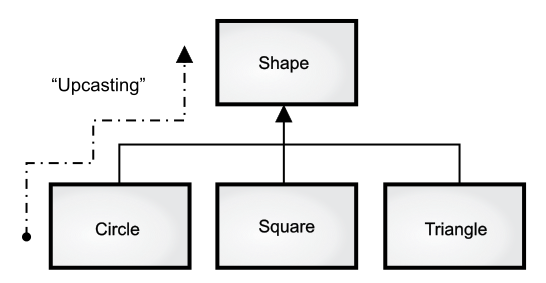
图字翻译:
“Upcasting”:“向上转型”
面向对象程序总会包含一些向上转型的代码,因为这样就可以让我们无须关心对象具体的类是什么。再看一下 doSomething() 方法中包含的代码:
1 | shape.erase(); |
需要注意的是,代码并没有告诉我们,“如果是一个 Circle 请这样做,如果是一个 Square 请那样做,诸如此类”。如果你真的编写了一段代码用于检查所有可能出现的形状,那么这段代码必然是一团糟,并且每当你为 Shape 添加一个新的子类时,都必须修改这段代码。所以,上面的代码实际上做的是:“这是一个 Shape,我知道它可以进行绘制和清除,那就这么干吧,具体细节交给形状自己处理就好”。
doSomething() 方法的神奇之处在于,代码运行的结果是符合预期的。如果直接通过 Circle、Square 或者 Line 对象调用 draw() 方法,运行的代码自然是不同的。如果调用 draw() 方法时并不知道 Shape 对象的具体类型,它也能正常工作,即执行其实际子类的代码。这一点十分了不起,因为当 Java 编译器编译 doSomething() 的代码时,它并不知道对象的类型是什么。通常来说,你可能会想当然地认为被调用的是基类 Shape 的 erase() 和 draw() 方法,而非具体的 Circle、Square 或者 Line 子类,然而实际情况是,确实是具体的子类被调用了,这就是多态。编译器和运行时系统负责处理各种细节,你需要了解的就是多态机制的存在,更重要的是要知道如何利用多态进行设计。当你向一个对象发送消息时,哪怕需要用到向上转型,该对象也能够正确地处理该消息。
1.8 单根层次结构
自从 C++ 语言出现以来,面向对象中是否所有的类都应该默认继承自某个基类的问题变得尤为突出。Java 则给出了肯定的答案(除了 C++ 以外,实际上几乎所有动态面向对象编程语言都是如此),这个终极基类的名字是 Object。
这种“单根层次结构”(singly-rooted hierarchy)具备很多明显的优势。由于所有对象都具有共同的接口,因此它们都属于同一个终极基类。另一种方案(来自 C++)则无法确保所有对象都属于同一个基类。从向后兼容的角度来看,这种限制性较小的设计方式对C语言更为友好,但是从完全的面向对象编程的角度来看,你就必须自己手动构建类的层次,这样才能拥有其他面向对象编程语言默认提供的便捷性。此外,你在使用任何新的库时,都有可能遇到一些不兼容的接口。如果你希望这些接口为你所用,就必须额外花费一些精力来改造它们。所以,C++ 这种额外的“灵活性”真的物有所值吗?如果需要的话,比如你已经花费了大量心血编写C语言代码,那么答案就是肯定的。而如果你是从头开始,那么使用 Java 或者其他替代方案则会高效许多。
单根层次结构有利于实现垃圾收集器(garbage collector),这也是 Java 对比 C++ 的一个重要改进。既然所有对象都拥有类型信息,你就再也不用发愁不知道某个对象具体是什么类型了。这一特性对于系统级别的操作而言尤为重要,比如异常处理(exception handling,一种用于处理错误的语言机制)等,同时也极大地提升了编程时的灵活性。
1.9 集合
一般来说,你并不知道解决一个特定的问题需要用到多少个对象,也不知道这些对象会存在多久,你甚至不知道该如何保存这些对象。问题是,如果你无法在程序运行前确切地知道这些信息,那你应该申请多少内存空间呢?
在面向对象设计领域,大多数问题的解决方案看似极为简单粗暴:创建一种新类型的对象,这种对象通过保存其他对象的引用来解决这个问题。而在大多数编程语言里,你也可以用数组(array)做到这一点。
这种新对象通常叫作集合(也可以叫做“容器”,不过 Java 的库普遍使用的是“集合”),它会根据你放入其中的内容自行调整空间。也就是说,你无须关注集合里会有多少对象,直接创建集合就好了,剩下的细节交给它自己处理就可以。
幸运的是,优秀的面向对象语言都会提供一些集合作为语言的基础功能。在 C++ 里,集合是 C++ 标准库的一部分,通常叫作“标准模板库”(Standard Template Library, STL)。SmallTalk 提供了一系列完整的集合。Java 在其标准库中也提供了大量的集合。在有些语言的库中,通常会有一两个集合能够适用于所有需求。而在另外一些语言(比如 Java)的库中,不同的集合具有不同的用途。比如,有几个不同的 List 类(用于保存序列),几个 Map 类(也叫“关联数组”,用于关联对象),几个 Set 类(用于保存不同类型的对象),以及一些队列(queue)、树(tree)、栈(stack)等。
从程序设计的角度而言,你真正需要的是能够解决实际问题的集合。一旦某种集合能够满足你的需求,你就不再需要其他集合了。之所以需要选择集合,可能有以下两个原因。
- 不同的集合提供了不同类型的接口和行为。比如,栈和队列的用途就与
Set以及List完全不同。针对你的问题,其中的某个集合也许可以提供比另一个集合更灵活的解决方案。 - 不同的集合在特定操作的执行效率方面也会有差异。比如,
List有两种基础类型的集合:ArrayList和LinkedList。虽然两者可以具有相同的接口和行为,但是某些操作的执行效率却存在明显的差异。比如用ArrayList随机获取元素是一种耗费固定时间的操作,意思是不管你选择获取哪个元素,耗费的时间都是相同的。但是对于LinkedList来说,在列表中随机选择元素是一种代价很大的操作,查找列表更深处的元素也会耗费更多的时间。另外,如果需要在列表中插入元素,LinkedList耗费的时间会比ArrayList更少。取决于两者底层架构的不同实现方式,其他一些操作的执行效率也各有不同。你也可以先用LinkedList编写代码,然后为了追求效率而转投ArrayList的怀抱。由于两者都是基于List接口的子类,因此只需要改动少量代码就可以切换集合。
参数化类型(泛型)
在 Java 5 之前,Java 语言的集合所支持的是通用类型 Object。因为单根层次结构决定了所有对象都属于 Object 类型,所以一个持有 Object 的集合就可以持有任何对象$^6$,这就使得集合十分易于复用。
6其实并不能保存原始类型,不过“自动装箱”(autoboxing)机制从某种程度上缓解了这个问题。相关细节将在后续章节介绍。
为了使用这样一个集合,你要将对象引用添加到集合中,然后再将其取出。但由于该集合只能持有 Object 类型,因此当你添加一个对象引用到集合时,该对象会向上转型为 Object,从而失去了其原本的特征。当你需要将其取出时,会获得一个 Object 类型的对象引用,这就不是当初的类型了。那么问题来了,当初被放入集合中的对象如何才能转换回原来的类型呢?
这里需要再一次用到转型,只不过这次不是向上转为更通用的类型,而是向下转为更具体的类型,这种转型叫作“向下转型”(downcasting)。当使用向上转型时,我们知道 Circle 对象属于 Shape 类型,所以这种向上转型是安全的。但是反过来,我们并不知道一个 Object 对象实际上是 Circle 还是 Shape 类型,所以除非你明确知道对象的具体类型是什么,否则向下转型是不安全的。
不过,也不是说向下转型一定是危险的。如果向下转型失败,你会得到一个运行时的错误提示,这叫作“异常”(exception),后面你很快就会看到相关的介绍。不过话说回来,当你从集合中获取对象引用时,需要通过一些方法明确对象的类型,这样的话才能正确的向下转型。
当一段程序在运行时,向下转型和与其关联的运行时检查都会耗费额外的时间,同时程序员也需要关注这种向下转型。为什么我们创建的集合就不能明确地知道所包含的对象类型呢?如果知道的话,我们就不再需要向下转型,也避免了在此期间可能出现的报错。这个问题的解决方案就是“参数化类型”(parameterized type)机制。一个被参数化的类型是一种特殊的类,可以让编译器自动适配特定的类型。比如,对于参数化的集合而言,编译器可以将集合定义为只接受放入 Shape 的对象,因此从集合也只能取出 Shape 对象。
Java 5 新增的主要特性之一是支持参数化类型,也叫作“泛型”(generics)。你可以通过在一对尖括号中间加上类名来定义泛型,比如,你可以这样创建一个放置 Shape 对象的 ArrayList:
1 | ArrayList<Shape> shapes = new ArrayList<>(); |
泛型带来的好处促使许多标准库组件都进行了相应的调整。此外,你在本书所列举的许多代码示例中都会看到泛型的作用。
1.10 对象的创建和生命周期
和对象打交道时有一个至关重要的问题,那就是它们的创建和销毁方式。每个对象的创建都要消耗一些资源,尤其是内存资源。当我们不再需要一个对象时,就要及时清理它,这样它占用的资源才能被释放并重复使用。在一些环境简单的场景下,清理对象似乎不是一个难题:你创建了一个对象,根据自己的需要使用,不再使用的时候就将其销毁。然而不幸的是,我们经常会遇到更为复杂的情况。
假设你需要为某个机场设计一个航空管制系统(你也可以用同样的方式管理仓库中的箱子、录像带租赁系统,甚至还有装宠物的笼子)。刚开始的时候,一切都是如此简单:新建一个用于保存飞机对象的集合,然后每当有飞机需要进入航空管制区域的时候,就新建一个飞机对象并将其放入集合中。而每当有飞机离开航空管制区域时,就清理对应的飞机对象。
再做一个假设:还有其他系统也会记录飞机的数据,而这些数据不需要像主控制程序那样及时更新,比如只会对离开机场的小型飞机做记录。于是,你需要创建一个新的集合用于保存小飞机对象,并且每当新建的飞机对象是小型飞机时,需要将其放入这个新的集合中。当有后台进程处于空闲状态时,就会操作这些对象。
现在问题变得更加棘手了,你怎么判断什么时候需要清理对象?当你不再需要一个对象时,系统的其他部分也许还在使用该对象。更糟糕的是,在许多其他情况下也会遇到同样的问题。而对于诸如 C++ 这样需要显式删除对象的编程语言来说,这绝对是一个相当让人头疼的问题。
对象的数据保存在哪里,系统又是如何控制对象的生命周期的呢?C++ 语言的宗旨是效率优先,所以它交给程序员来选择。如果要最大化运行时效率,可以通过栈区(也叫作“自动变量”或“局部变量”)保存对象,或者将对象保存在静态存储区里,这样在编写程序时就可以明确地知道对象的内存分配和生命周期。这种做法会优先考虑分配和释放内存的速度,在有些情况下是极为有利的。但是,代价就是牺牲了灵活性,因为你必须在编写代码时就明确对象的数量、生命周期以及类型。如果你希望解决一个更为普遍的问题,比如计算机辅助设计、仓库管理或者航空管制等,这种做法的限制性就太大了。
还有一种方案是在内存池里动态创建对象,这个内存池叫作“堆”(heap)。如果使用这个方案,直到运行时你才能知道需要多少对象,以及它们的生命周期和确切的类型是什么。也就是说,这些信息要等到程序运行时才能确定。如果你需要创建一个新对象,可以直接通过堆来创建。因为堆是在运行时动态管理内存的,所以堆分配内存所花费的时间通常会比栈多一些(不过也不一定)。栈通常利用汇编指令向下或向上移动栈指针(stack pointer)来管理内存,而堆何时分配内存则取决于内存机制的实现方式。
动态创建对象的方案基于一个普遍接受的逻辑假设,即对象往往是复杂的。所以在创建对象时,查找和释放内存空间所带来的额外开销不会造成严重的影响。此外,更大的灵活性才是解决常规编程问题的关键。
Java 只允许动态分配内存7。每当你创建一个对象时,都需要使用 new 操作符创建一个对象的动态实例。
7你之后将学习到的原始类型(primitive type)是一个特例。
然而还有另一个问题——对象的生命周期。对于那些允许在栈上创建对象的编程语言,编译器会判断对象将会存在多久以及负责自动销毁该对象。但是如果你是在堆上创建对象,编译器就无从得知对象的生命周期了。对于像 C++ 这样的语言来说,你必须在编码时就明确何时销毁对象,否则万一你的代码出了差错,就会造成内存泄漏。而 Java 语言的底层支持垃圾收集器(garbage collector)机制,它会自动找到无用的对象并将其销毁。垃圾收集器带来了很大的便利性,因为它显著减少了你必须关注的问题数量以及需要编写的代码。因此,垃圾收集器提供了一种更高级的保障以防止潜在的内存泄漏,而正是内存泄漏导致了许多 C++ 项目的失败。
Java 设计垃圾收集器的意图就是处理内存释放的相关问题(虽然不包括清理对象所涉及的其他内容)。垃圾收集器“知道”一个对象何时不再有用,并且会自动释放该对象占用的内存。再加上所有对象都继承自顶层基类 Object,以及只能在堆上创建对象等特点,使得 Java 编程比 C++ 简单了不少。一言以蔽之,需要你介入的决策和阻碍都大大减少了。
1.11 异常处理
自从有编程语言起,错误处理就是一项极为困难的工作。设计一个优秀的错误处理系统是如此困难,以至于许多编程语言忽视了这个问题,而将问题抛给库的设计者。这些设计者只能采取一些折中措施来填补漏洞,这些举措虽然在有很多场景中都有效,但很容易通过忽略提示的错误而轻易绕过。大多数错误处理方案存在的一个显著的问题是,这些方案并非编程语言强制要求的,而是依赖于程序员同意并遵守相关约定。如果遇到警惕性不高的程序员(通常都是因为需要赶进度而放松了警惕),这些方案就形同虚设了。
异常处理则是将编程语言甚至是操作系统和错误处理机制直接捆绑在一起。异常是从错误发生之处“抛出”的对象,而根据错误类型,它可以被对应的异常处理程序所“捕获”。而每当代码出现错误时,似乎异常处理机制会使用一条特殊的、并行的执行路径来处理这些错误。这是因为它确实采取了一条单独的运行路径,所以不影响正常执行的代码。同时这一点也降低了你编写代码的成本,因为你不用经常反复检查各种错误了。此外,抛出的异常也不同于方法返回的错误值或者方法设置的错误标识,因为这两者是可以被忽略的,但是异常不允许被忽略,所以这就确保了异常一定会在必要的时候被处理。最后,异常为我们提供了一种可以让程序从糟糕的情况中恢复过来的方法。即便发生了意外,我们也还有机会修正问题以及让程序重新恢复运行,而不是只能结束程序了事,而这一点无疑会增强许多程序的稳健性。
Java 的异常处理机制在众多编程语言之中几乎可以说是鹤立鸡群,这是因为 Java 从一开始就内置了异常处理,并且强制你必须使用它,这一点没有任何商量的余地,同时这也是Java唯一允许的报错方式。如果你的代码没有正确地处理各种异常,就会得到一条编译时的报错消息。这种有保障的一致性使得错误处理的工作简单了许多。
值得我们留意的是,虽然面向对象语言里的异常一般用对象的形式来呈现,异常处理却并不是面向对象语言的特性。其实,异常处理远在面向对象语言诞生之前就已经存在了。
1.12 总结
一段过程式程序(procedural program)包含了数据定义和函数调用。如果你想要搞清楚这种程序究竟做了什么,就必须仔细研究,比如查看它的函数调用以及底层代码等,以便在你的脑海中勾勒出一幅完整的蓝图。而这就解释了在设计过程式程序时,为什么还需要中间表示(intermediate representation, IR)。实话实说,过程式程序的理解成本确实很高,因其设计的表达方式更多是面向计算机,而不是你要解决的问题。
因为面向对象编程在过程式编程语言的基础上增加了许多新特性,所以你可能会想当然地认为同等效果的 Java 程序会远比过程式程序复杂。然而你会惊喜地发现,编写良好的 Java 程序通常比过程式程序更简单,也更易于理解。这是因为在 Java 中,对象的定义所呈现的是问题空间(而非计算机式的呈现)的概念,而发送至对象的消息则代表问题空间的具体活动。面向对象编程的一个令人愉悦之处在于,那些设计良好的程序,其代码总是易于阅读的。另外,因为许多问题都能够通过复用已有的库来解决,所以通常来说代码行数也不会太多。
面向对象编程和 Java 不一定适合所有人。有一点非常重要,那就是你必须仔细评估自己的需求,然后再判断 Java 是不是满足这些需求的最佳方案,也许使用其他编程语言是更好的选择(说不定就是你现在使用的编程语言)。如果在可预见的将来,你的需求非常专业并且具有一些 Java 无法满足的特殊条件,那么你就有必要研究一下其他可代替的编程语言(我尤其推荐 Python)。这样一来,就算你依然选择 Java 作为你的编程语言,至少你清楚还有哪些可选项,以及为什么选择它。
 微信扫码
微信扫码 支付宝扫码
支付宝扫码





